







今天在使用github开源的deeplabV2时,因为使用cv2.imread读取图像默认为uint8类型,导致分割精度很低。同时还发现一些别的问题,特此记录。
数据格式问题
总体来说就是:cv2.imread读取数据格式默认uint8,做数据归一化(预处理阶段)会导致精度缺失,最后导致分割精度下降
先看如下代码:
model = Res_Deeplab(21)
model.load_state_dict(t.load('./MS_DeepLab_resnet_trained_VOC.pth'))
model.eval()
model.cuda()
img = np.zeros((513, 513, 3));
# img_temp = cv2.imread('cat.jpg').astype(np.float32)
img_temp = cv2.imread('cat.jpg')我们构建模型类,同时用预训练模型参数导入模型。新建一个513x513大小的图像模板,用imread读取一张BGR,uint8类型的数据。注意注释的地方才是正确做法。
然后数据预处理过程如下:
# img_original = img_temp.copy()
img_original = img_temp
img_temp[:, :, 0] = img_temp[:, :, 0] - 104.008
img_temp[:, :, 1] = img_temp[:, :, 1] - 116.669
img_temp[:, :, 2] = img_temp[:, :, 2] - 122.675我们对图像数据按照BGR的训练集均值做0均值化处理。还将未处理的原图保存给另一个变量,用于后期显示原图进行结果对比。注释部分也是一个错误点待记录。
然后送入模型,发现结果如下:
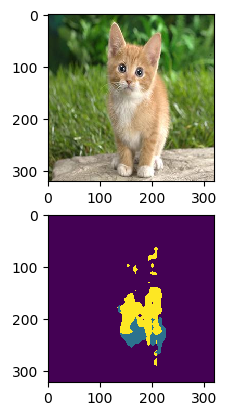
可以看出精度损失的很厉害。我之所以会犯这个错误,不是因为我不知道imread读取默认为uint8,而是我认为做0均值化处理的时候,img_temp的数值会自动变成 np.float32类型,然后在减去那三个均值。结果发现并不是。因为之前学习C++,知道数据类型是往精度更高的类型自动转换的,看来对于这个转换方式不包含unsigned类型。
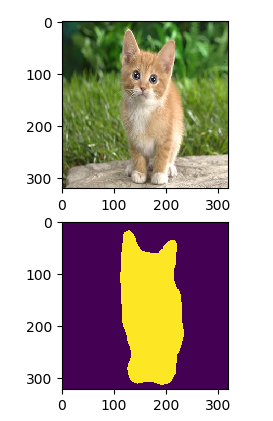
按照注释来,结果就正常了。
cv2.imread读取的数据作为赋值,被赋值的变量和原始变量有相同的地址
看如下代码。
img_temp = cv2.imread('cat.jpg').astype(np.float32)
a = img_temp
print(id(img_temp)==id(a))
'''
>>> True
'''后面要对img_temp做0均值化,其实也修改了a的值,我们本意想让a保存原图信息,但现在也修改了a的值。所以正确的做法是:
img_temp = cv2.imread('cat.jpg').astype(np.float32)
img_original = img_temp.copy()
img_temp[:, :, 0] = img_temp[:, :, 0] - 104.008
img_temp[:, :, 1] = img_temp[:, :, 1] - 116.669
img_temp[:, :, 2] = img_temp[:, :, 2] - 122.675这样二者就不是相同地址的变量了。修改一种一个不会影响另一个。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









