









 本文探讨了程序访问的局部性原理,特别是时间局部性和空间局部性,以及如何通过高速缓存技术利用这些原理提高程序执行速度。文章详细解释了Cache的工作原理、映射方式、替换算法和写策略,展示了多级Cache在现代计算机架构中的应用。
本文探讨了程序访问的局部性原理,特别是时间局部性和空间局部性,以及如何通过高速缓存技术利用这些原理提高程序执行速度。文章详细解释了Cache的工作原理、映射方式、替换算法和写策略,展示了多级Cache在现代计算机架构中的应用。
1.程序访问的局部性原理
1.1 时间局部性
在最近的未来要用到的信息,很可能是现在正在使用的信息。比如程序中的循环。
1.2 空间局部性
在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是连续的。因为指令通常是顺序存放,顺序执行的;数据通常也是以向量、数组等形式簇聚在一起。
高速缓冲技术便是利用的程序局部性原理,将程序正在使用的数据放到一个高速的、容量较小的Cache中,从而使CPU的访存操作大多对Cache进行,因而提高了程序的执行速度。
1.3 栗子🌰
int sumArrayRows(int a[M][N]){
int i,j,sum = 0;
for(i = 0 ; i < M ; i++){
for(j = 0 ; j < N ; j++){
sum += a[i][j];
}
}
return sum;
}
int sumArrayCols(int a[M][N]){
int i,j,sum = 0;
for(i = 0 ; i < N ; i++){
for(j = 0 ; j < M ; j++){
sum += a[j][i];
}
}
return sum;
}
说明
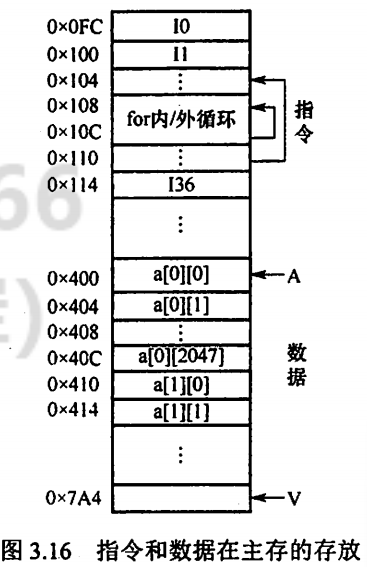
- 程序1的空间局部性要优于程序2。因为程序1的访问顺序为a[0][0]、a[0][1]、a[0][2]、…a[1][0]、a[1][1]、a[1][2]、…a[2047][1]、…,可以看出,访问顺序与存储顺序一致,因此空间局部性较好。而程序2的访问顺序为a[0][0]、a[1][0]、a[2][0]、…a[2047][1]、…,可见,其访问顺序与存储顺序不符,且每次访问的位置间隔为2048 × 4个字节,如果Cache的交换单位<8KB,那么每一次的访存都需要将一个主存块装入到主存中,因而丧失了空间局部性。
- 程序1和程序2的时间局部性都很差。因为每个元素均被访问了一次,没有在接下来再次被访问。
2.Cache的工作原理
2.1 特点
- Cache位于存储器的顶层,通常由SRAM组成。
- 因方便需要,Cache和主存被划分为多个块(行),且二者块的大小规格一致。块(行)又包含多个字节。
- Cache中块的数量 << 主存中块的数量,Cache仅保存主存中最活跃的块的副本。
- Cache中会按照某种策略预测CPU未来将使用到的块,然后将其由主存调入Cache。
- CPU与Cache的数据交换是以字为单位;Cache与主存的数据交换是以Cache块为单位。
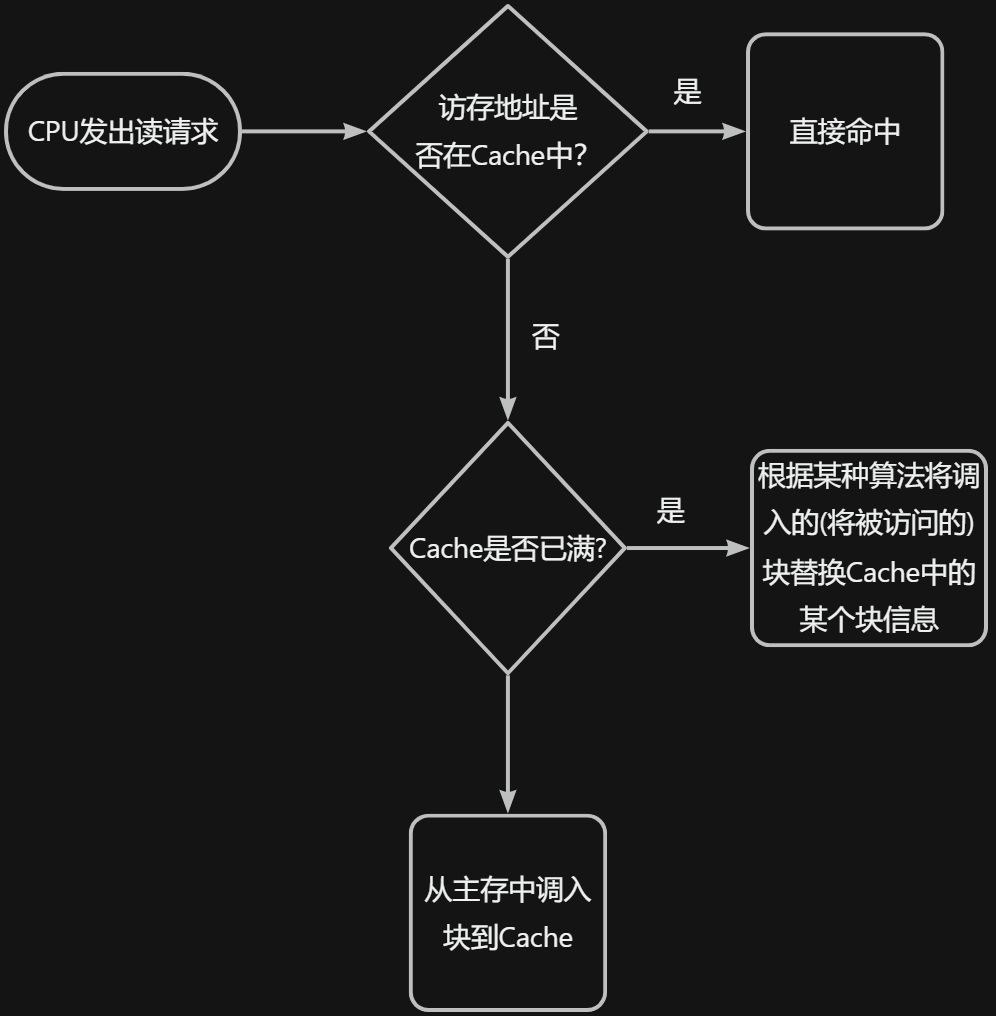
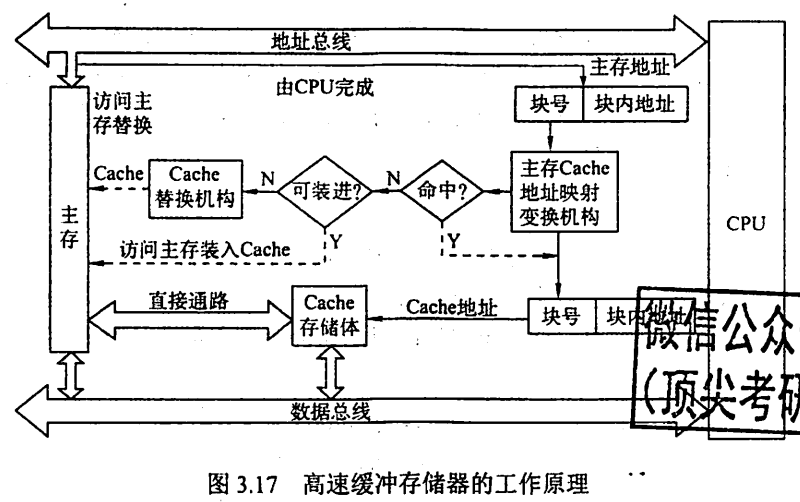
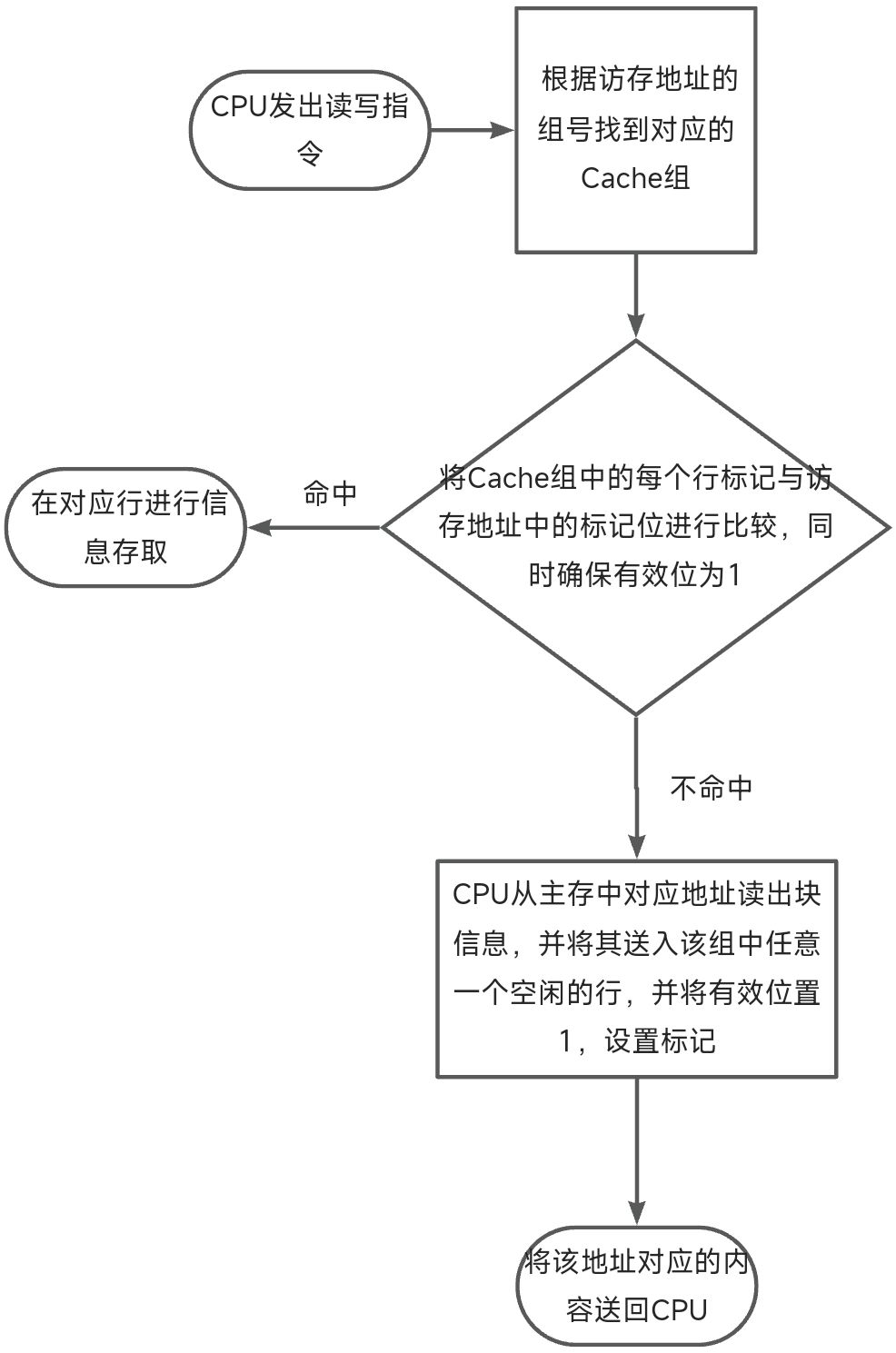
2.2 使用Cache后的访存流程
Ps
- 替换Cache中的块信息时,整个过程全部由硬件自动完成。
- 某些计算机中采用Cache与主存同时访问策略。若Cache命中,则对主存的访问终止;若不命中,则继续访问主存并替换Cache。
- 当CPU发出写命令时,若Cache命中,可能会遇到Cache块中的内容与主存中的不一致的情况(脏数据),此时就需要采用写策略进行处理。(详情见第5部分)
Cache命中率 = Cache总命中次数 / (Cache总命中次数 + 访问主存总次数)。
Cache-主存系统的平均访存时间 = Cache命中率 × Cache访问时间 + (1 - Cache命中率) × 主存访问时间。
3.Cache和主存的映射方式
2.1 概述
地址映射:把主存地址空间映射到Cache地址空间。
2.2 分类
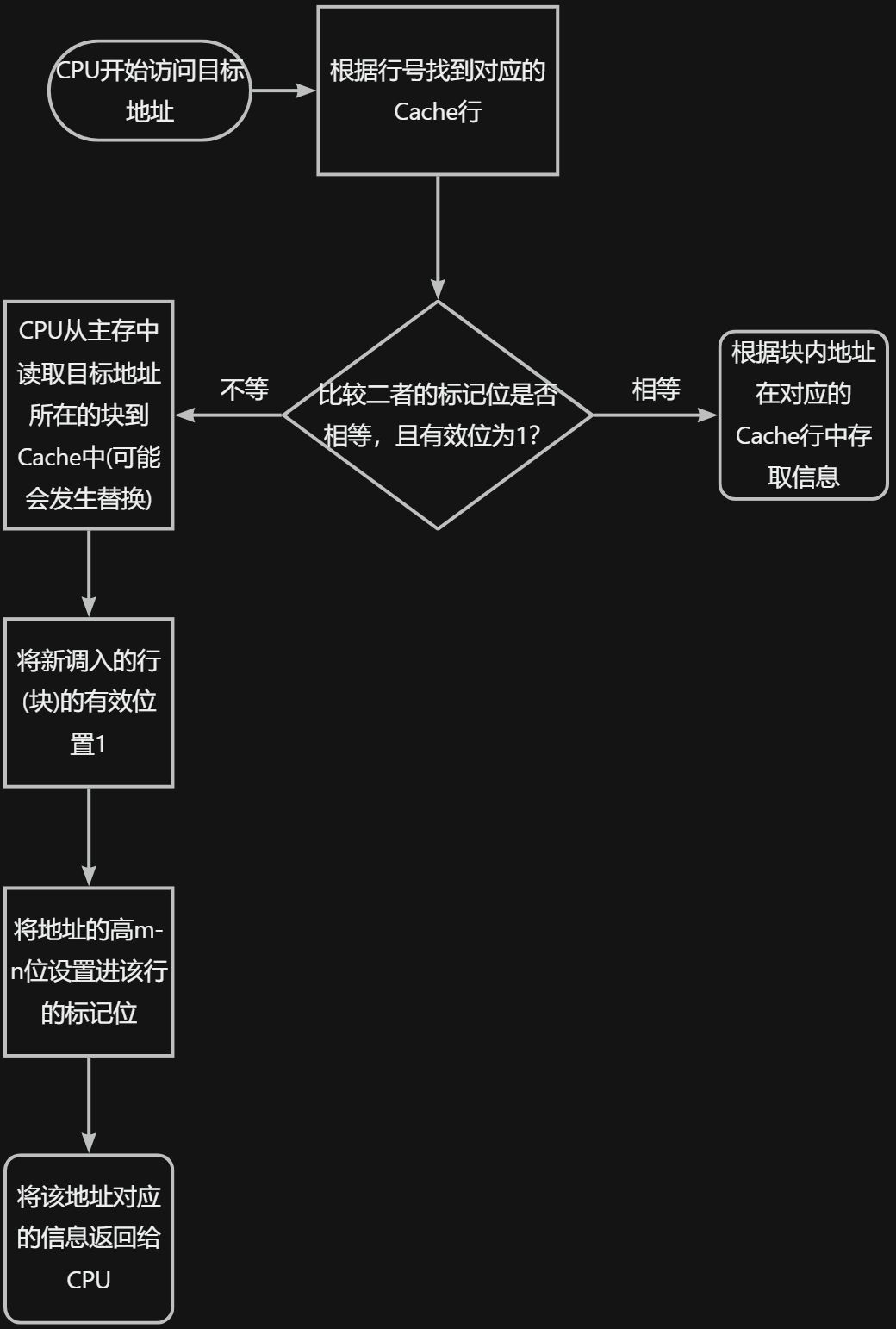
2.2.1 直接映射
2.2.1.1 特点
- 主存中的每一个块只能装入到Cache中的某个固定的位置。若原位置处已有内容,则无条件将其替换出去(无需使用替换算法)。
- Cache行号 = 主存块号 % Cache行数。
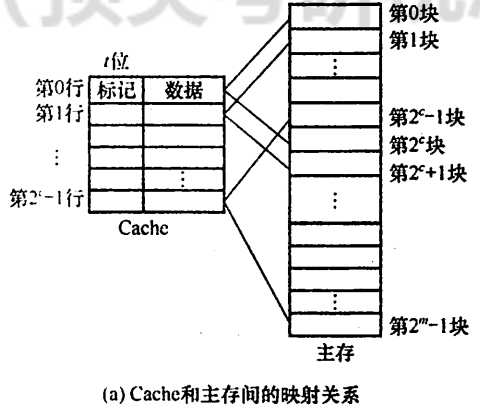
2.2.1.2 地址结构
设Cache共有2n个行(块),主存共有2m个块。
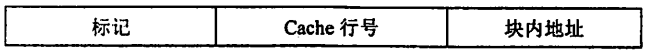
说明
Cache行号位为原主存块编号的低n位,标记位则为原主存块变化的高m - n位。
2.2.1.3 访问过程

2.2.2 全相联映射
2.2.2.1 特点
- 主存中每一个块都可以装入Cache中的任何位置。
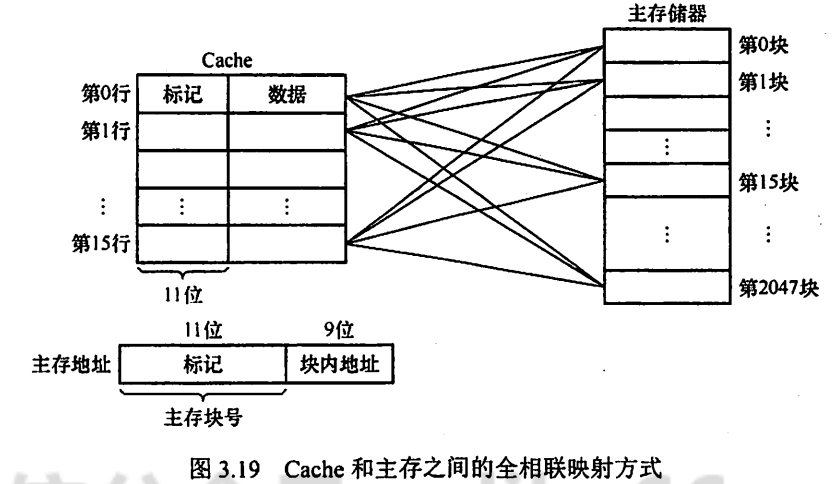
2.2.2.2 地址结构

- 标记位用于存储该行(块)的主存块号。
- CPU访存时,只需要比较标记位。
2.2.2.3 优缺点
2.2.2.3.1 优点
- 比较灵活,Cache块的冲突率低。
- 空间利用率高。
- 命中率高。
2.2.2.3.2 缺点
- 标记位比较时的速度较慢。
- 实现成本较高,通常采用按内容寻址的相联存储器进行地址映射。
2.2.3 组相联映射
2.2.3.1 特点
- 是直接映射和全相联映射的折中方案。
- 将Cache分为多个组,每个主存块可以存入固定组中的任意一行。
- 组间采用直接映射,组内采用全相联映射。
- 当分组数量 = 1时,此时变为全相联映射;当分组数量 = Cache行数 时,此时变为直接映射。
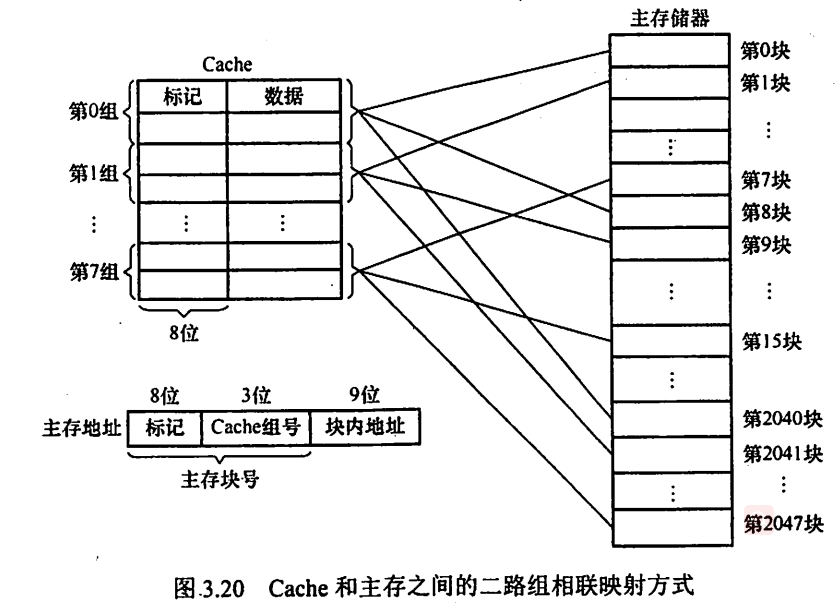
根据每个组包含Cache行的数量r,可称之为r路组相联。上图中,每个组包含2个Cache行,因此称为二路组相联。
2.2.3.2 地址结构

- 组号 = 主存块号 % Cache组数。
- 路数越大,发生块冲突的概率就越低。
- 标记位的比较操作是通过比较器来完成的。
- 比较器数 = 组数。
- 比较器的位数 = 标记位的位数。
2.2.3.3 访存过程

Ps
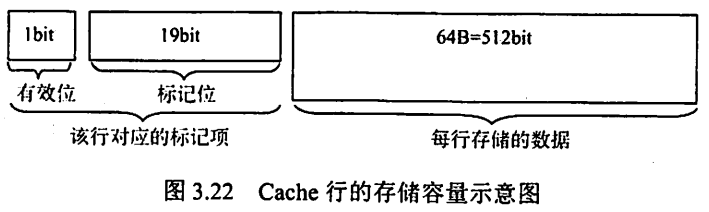
- 每一个Cache行都对应一个标记项,查找Cache时就是查找Cache的标记阵列。
- Cache行对应的标记项由有效位、标记位、一致性维护位、替换算法控制位组成。
- Cache行的存储容量 = 该行对应的标记项 + 该行存储的块数据。
- Cache总容量 = Cache行数 ✖️ Cache行的存储容量。
2.3 三种映射方式的比较
| 项目 | 直接映射 | 全相联映射 | 组相联映射 |
|---|---|---|---|
| 命中率 | 最低 | 最高 | 中等 |
| 判断开销/判断所需时间 | 最少 | 最多 | 中等 |
| 标记项占用的额外空间 | 最小 | 最大 | 中等 |
4.Cache中主存块的替换算法
4.1 概述
当采用全相联映射或组相联映射的方式的时候,当需要从主存中调入一个新块到Cache中时,此时可能会遇到Cache满或Cache固定组满的情况,此时就需要考虑移除一个旧块;采用直接映射的时候,由于每个块所调入的位置固定,因此可以毫无顾虑的移除目标位置上的旧块,而无需考虑使用什么替换算法。
4.2 分类
4.2.1 随机算法(RAND)
4.2.1.1 说明
随机确定将要替换的块。
4.2.1.2 优缺点
优点
实现比较简单。
缺点
未依据程序局部性原理,可能导致命中率较低。
4.2.2 先进先出算法(FIFO)
4.2.2.1 说明
选择最早调入的块进行替换。
4.2.2.2 优缺点
缺点
未依据程序局部性原理,因为最早调入的块可能在未来会被经常使用到。
4.2.3 近期最少使用算法(LRU)
4.2.3.1 说明
- 选择近期长久未被访问过的块。
- 是堆栈类算法。
4.2.3.2 原理
- 为每个Cache行设置一个计数器,用于记录主存块的使用情况,同时依据该记录值来选择淘汰哪一个块。
- 采用组相联映射时,计数器位数 = 路数。
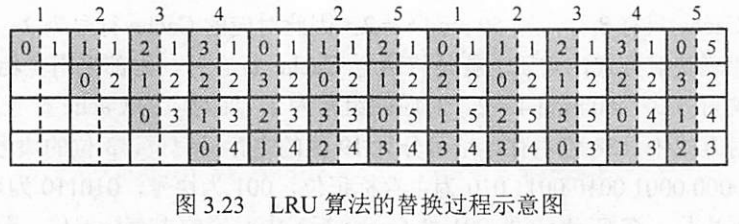
计数器变化规则
- 命中时,命中的行(块)清0,只有比其计数器记录值低的行计数值+1。
- 未命中,但有空闲行时,新装入的行计数值置0,其余行+1。
- 未命中,但无空闲行时,淘汰计数值最大的块,并以新调入的块填充,同时该行计数值置0,其余行+1。
4.2.3.3 优缺点
优点
- 依据了程序局部性原理。
- 平均命中率高于FIFO算法。(当采用组相联映射并集中访问的存储区超过Cache组大小时,命中率可能会变得很低)
4.2.4 最不经常使用算法(LFU)
4.2.4.1 说明
- 将一段时间内访问次数最少的行换出。
- 该算法与LRU类似,但不完全相同。
4.2.4.2 原理
每行设置一个计数器,每访问一次,计数值+1(新调入的行默认置0),需要换出时,则将计数值最小的行换出。
5.Cache写策略
5.1 概述
因为Cache存放的是 主存中的内容的副本,因此当对Cache中的内容进行写操作时,就需要考虑Cache与主存内容一致的问题。
5.2 分类
5.2.1 全写法/写直通法(写命中)
5.2.1.1 说明
当CPU对Cache写命中时,必须把数据同时写入Cache和主存。
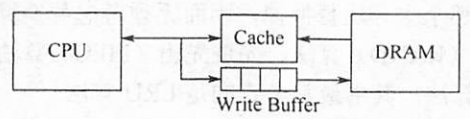
Write Buffer:写缓冲。用于解决使用全写法将数据直接写入主存组时所带来的时间消耗。如上图所示,CPU将数据同时写入到Cache和缓冲队列(Write Buffer)中,然后Write Buffer再控制将内容写回主存中。写缓冲是一个FIFO队列,因此,频繁进行数据的读写时,可能会出现写缓冲溢出的情况。
5.2.1.2 优缺点
优点
- 实现简单。
- 能够随时保持Cache与主存的内容一致性。
缺点
增加了访存次数,降低了Cache的效率。
5.2.2 回写法/写回法(写命中)
5.2.2.1 说明
- CPU对Cache写命中时,只把数据写入Cache,而不立即写入主存,只有在此块被换出时,才写回主存。
- 为减小写回主存的开销,每个Cache行会增设一个修改位(脏位)。如果修改位 = 1,则说明该块被修改过,被换出时需要回写;若该位 = 0,则说明该块未被修改过,换出时无需写回主存。
5.2.2.2 优缺点
优点
减少了访存次数。
缺点
存在数据不一致的隐患。
5.2.3 写分配法(写不命中)
5.2.3.1 说明
将缺失的块先调入Cache中,然后再去更新这个Cache块。
5.2.3.2 优缺点
缺点
每次不命中的时候都需要再去主存中读取一个块。
5.2.4 非写分配法(写不命中)
5.2.4.1 说明
直接写入主存块,而不进行调块。
现在计算机通常采用分离Cache结构来解决取指令与取数据时产生的冲突,这是充分利用指令和数据的不同局部性来优化性能的体现。

现代计算机通常采用多级Cache,按离CPU的远近可命名为L1 Cache、L2 Cache、L3 Cache。离CPU越远,速度越慢,容量越大。
L1 Cache通常用于将数据与指令分离,同时采用回写法+写分配法。
















 5059
5059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











