







众所周知,HashMap是一个散列桶,它存储的内容是键值对(key-value)映射
版本差异
| 版本 | 结构 | 优点 | 结构图 |
|---|---|---|---|
| 1.7 | 数组+链表 | 集成了数组快速查询和链表的快速增删的优点 | 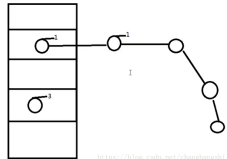 |
| 1.8 | 数组+链表+红黑树 | 继承了1.7的优点,并加快查询的速度 | 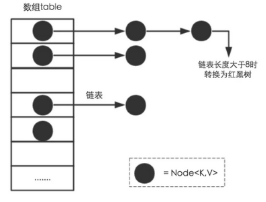 |
数组和链表的区别:
针对这个问题,我们引入ArrayList 和 LinkedList 的底层实现原理
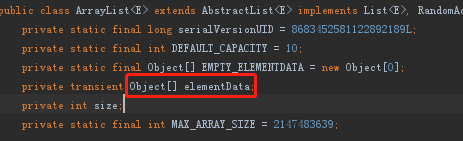
- ArrayList 内部实现原理采用的是数组结构,代码如下
- LinkedList 内部实现原理采用的是链表结构

总结:
浅显的说,一个是利用java的数组实现,一个采用的静态内部类实现。所以ArrayList利用 数组索引查询,效率高于链表的循环遍历查询。但是新增或者删除会改变原有数组的结构(删除新增会改变原数组的顺序,导致数组内部数据集体左移或者右移),而链表只需要改变类属性的指向,当然这个操作也是需要通过循环去找到需要修改的位置,代码如下
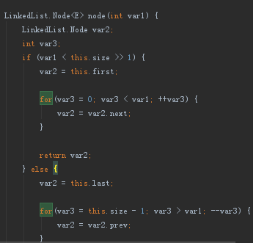 如右图可知,查询会先判断你需要查找的位置是否小于size的一半,故而选择从头还是从尾查询(优化查询速度,可知当位置位于中间位置,查询时间最长),至于ArrayList 在什么情况下插入和删除会优于LinkedList ,我们这边不做详细说明。
如右图可知,查询会先判断你需要查找的位置是否小于size的一半,故而选择从头还是从尾查询(优化查询速度,可知当位置位于中间位置,查询时间最长),至于ArrayList 在什么情况下插入和删除会优于LinkedList ,我们这边不做详细说明。
以上大致介绍了数组结构和链表结构的优点和区别,而HashMap巧妙的利用这两种结构,
根据hash值计算下标,将数据放入到数组下标指定位置。而放置数据的则是一个链表。方便数据的快速添加和删除。
特别的,当元素大于一个指定的阈值(负载因子控制 0.75),HashMap会和ArrayList 一样发生扩容,并重新放置元素。
如你所见,当链表内数据太多情况下会出现查询遍历时间复杂度增加(对添加和删除均有影响,理由可参照LinkedList),故而引入红黑树。红黑树的原理在此就不做说明。红黑树通过左旋右旋上色来保证树的基本平衡,从而不会导致树出现 左右严重失衡,因为这样极可能发生数据查询出现最大的时间差,故而 数组+链表+红黑树的结构 能最大化保证查询速度,当然会引发一些其他性能的问题,比如说红黑树的操作,各有利弊。
死循环
那么1.7中的HashMap 引发死循环的原因是什么呢。
我们在上面说过,当加入的元素超过一个阈值,会引发数组结构的扩容操作。会重新创建一个原数组2倍的数组,将原来的元素添加到新的数据里,但是在解析数组绑定的链表的时候,为了提高效率,会从链表头开始循环,从而导致数据被反向绑定到新数组里,代码如下
 所以原数组中的链表是a->b->c ,到新数组中会改变链表位置可能变成c->b->a,故而多线程情况下,可能线程1 调整好位置 , 线程2 还未调整,导致形成闭环。引发死锁。
所以原数组中的链表是a->b->c ,到新数组中会改变链表位置可能变成c->b->a,故而多线程情况下,可能线程1 调整好位置 , 线程2 还未调整,导致形成闭环。引发死锁。
因为1.8中结构发生变化,故而不会导致死循环。但是高并发的情况仍然会出现丢失数据,故而如果在多线程的情况下是不安全的。
以上观点如果对您有所帮助,劳烦点赞或者评论,感谢支持,如有错误,敬请指出,感谢。
有部分图片引自其他博主:
图片来源:
https://blog.csdn.net/changhangshi/article/details/82114727
https://my.oschina.net/u/2307589/blog/1800587
https://blog.csdn.net/xidiancoder/article/details/71056726?utm_source=app















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









