







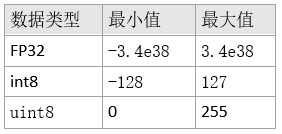
量化是将数值 x 映射到 y 的过程,其中 x 的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)。8-bit 低精度推理,是将一个原本 FP32 的浮点张量转化成一个 int8/uint8 张量来处理。先看一下浮点数和 8-bit 整数的完整表示范围。
模型量化会带来如下两方面的好处:
-
减少内存带宽和存储空间
深度学习模型主要是记录每个 layer(比如卷积层/全连接层) 的 weights 和 bias, FP32 模型中,每个 weight /bias 数值原本需要 32-bit 的存储空间,量化之后只需要 8-bit 即可。因此,模型的大小将直接降为将近 1/4。
不仅模型大小明显降低, activation 采用 8-bit 之后也将明显减少对内存的使用,这也意味着低精度推理过程将明显减少内存的访问带宽需求,提高高速缓存命中率,尤其对于像 batch-norm, relu,elmentwise-sum 这种element-wise 算子来说,效果更为明显。
-
提高系统吞吐量(throughput),降低系统延时(latency)
直观理解,试想对于一个 专用寄存器宽度为 512 位的 SIMD 指令,当数据类型为 FP32 而言一条指令能一次处理 16 个数值,但是当我们采用 8-bit 表示数据时,一条指令一次可以处理 64 个数值。因此,在这种情况下,可以让芯片的理论计算峰值增加 4 倍。
02
量化方法
按照量化阶段的不同,一般有以下分类:
(1)Post Training Quantization
PTQ 直接对训练后的浮点模型进行量化,过程简单,不需要在训练阶段考虑量化问题。其中weight跟上述一样也是被提前量化好的,然后activation也会基于之前校准过程中记录下的固定的scale和zero_point进行量化,整个过程不存在量化参数(scale和zero_point)的再计算;
(2)Quantization Aware Training
于一些模型在浮点训练+量化过程中精度损失比较严重的情况,就需要进行量化感知训练,QAT 需要在训练阶段就对量化误差进行建模,这种方法一般能够获得较低的精度损失。
本文接下来介绍的主要方法是针对 PTQ 。
03
PTQ
简单的说,量化算法是将一个原本 FP32 的浮点张量转化成一个 int8/uint8 张量来处理,那么我们只要将 FP32 张量的最大值(max)和最小值(min)来转换到 int8/uint8 就可以了。具体的,PTQ 分为对称算法和非对称算法,下面我们主要介绍这两种算法的详细内容及其区别。
3.1 非对称算法 (asymmetric)
如下图所示,非对称算法的基本思想是通过 收缩因子(scale) 和 零点(zero point) 将 FP32 张量 的 min/max 映射分别映射到 8-bit 数据的 min/max。
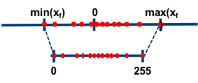
如果我们用 x_f 表示 原始浮点数张量, 用 x_q 表示量化张量, 用 q_x 表示 scale,用 zp_x 表示 zero_point, n 表示量化数值的 bit数,这里 n=8, 那么非对称算法的量化公式如下:
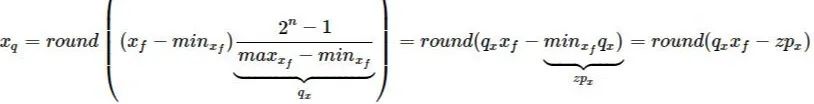
上述公式中引入了 zero_point 的概念。它通常是一个整数,即 zp_x= rounding(q_x * min_x_f)。
当x_f 为 0 时,在量化之后,刚好对应这个整数 zero_point 。这也意味着 zero_point 可以无误差地量化浮点数中的数据 0,从而减少补零操作(比如卷积中的padding zero)在量化中产生额外的误差。
但是,从上述公式我们可以发现 x_q 的结果只能是一个非负数,这也意味着其无法合理地处理有符号的 int8 量化,Pytorch 的处理措施是将零点向左移动 -128,并限制其在 [-128,127] 之间。
3.2 对称算法(symmetric)
对称算法的基本思路是通过一个收缩因子(scale)将 FP32 tensor 中的最大绝对值映射到 8 bit数据的最大值,将最大绝对值的负值映射到 8-bit 数据的最小值。以 int8 为例,max(|x_f|)被映射到 127,-max(|x_f|)被映射到-128。如下图所示:
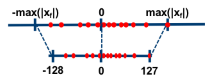
与非对称算法相比,对称算法一般不采用 zero_point, 其量化公式如下:
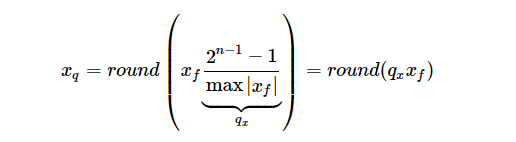
如果 FP32 张量的值能够大致均匀分布在 0 的左右,这种算法将数值映射到 int8 数据之后也能均匀的分布在 [-128, 127]之间。但是对于分布不均匀的 FP32 张量,量化之后将不能够充分利用 8-bit 的数据表示能力。
3.3 对称算法 VS 非对称的算法
非对称算法一般能够较好地处理数据分布不均匀的情况,为了验证这个问题,我们用 python 做了一个小实验。FP32 原始数据均匀分布在 [-20, 1000],这也意味着数据分布明显倾向于正数一方。下图展示了实验结果。
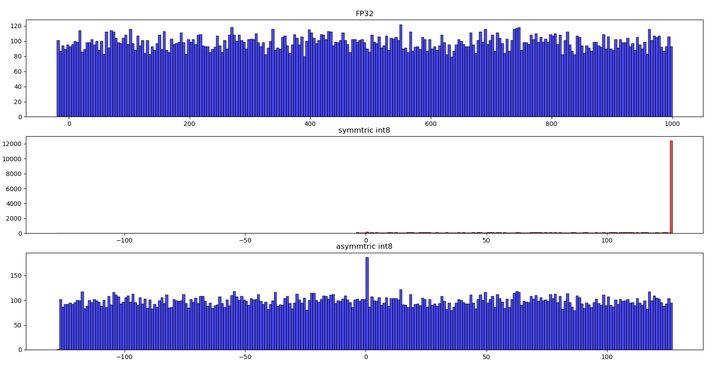
从图中可以看出,对于这种FP32 数据分布不均匀的情况下,对称算法的量化数据分布与原始数据分布相差很大。由对称算法(symmetric)产生的 量化数据绝大部分都位于[0,127] 这个表示范围内,而 0 的左侧有相当于一部分范围内没有任何的数据。int8 本来在数据的表示范围上就明显少于 FP32,现在又有一部分表示范围没发挥左右,这将进一步减弱量化数据的表示能力,影响量化模型的精度。与之相反,非对称算法(asymmetric)则能较好地解决 FP32 数据分布不明显倾向于一侧的问题,量化数据的分布与原始数据分布情况大致相似,较好地保留了 FP32 数据信息。
3.4 引入 zero-point 对算子的影响
卷积(convolution)和全连接(fully-connected)中的主要操作都是乘加。为了简化问题说明,我们这里将其具体实现形式简化成乘加。以 y_f 表示浮点数输出,y_q 表示量化输出, b_f 表示浮点数偏置。在低精度模式下,CPU 的计算过程中一般过程是两个量化数据乘加之后先还原到 FP32 高精度,然后再量化成低精度。
对称算法的计算过程如下:
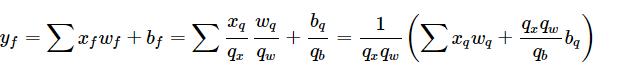
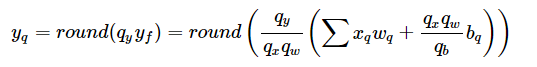
非对称算法的计算过程如下:
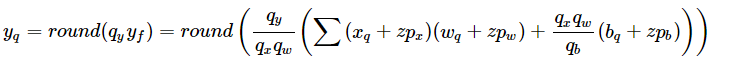
从上面的对比我们不难看出带有 zero_point 的非对称量化算法在计算的时候将会多出来如下三项计算:
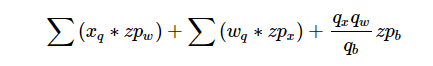
这也意味着多余的乘加操作将会降低 asymmetric 算法的性能。其中最后一项为常量,由于在推理的时候 weights 是常量,第二项也可以离线计算。为了优化这部分操作,很多加速库都做了不同的处理详情。
如果看过 Pytorch 量化算法实现,你一定很疑惑为什么它的的 symmtric 量化算法也采用了zero_point。这个其实也不难理解,我们回头看一下 symmtric 算法的量化公式,如果量化类型为 uint8,FP32数据均匀分布在零点左右,这个公式将会把很多原来为负值的 FP32 数据都量化成 0,只保留了原有FP32中非负数部分的量化数据。Pytorch 的操作相当于显示地利用 zero_point 将 rounding 之前的量化结果直接往右移动了 128,从而保留了FP32中负数部分的数据。
3.5 浮点数动态范围的选取
从上面对两种量化算法的介绍我们不难发现,为了计算 scale 和 zero_point 我们需要知道 FP32 weight/activiation 的实际动态范围。对于推理过程来说, weights 是一个常量张量,不需要额外数据集进行采样即可确定实际的动态范围。但是 activation 的实际动态范围则必须经过采样获取,一般把这个过程称为数据校准(calibration) 。
目前各个深度学习框架中,使用最多的有最大最小值(MinMax), 滑动平均最大最小值(MovingAverageMinMax) 和 KL 距离(Kullback–Leibler divergence) 三种。如果量化过程中的每一个 FP32 数值都在这个实际动态范围内,我们一般称这种为不饱和状态;反之如果出现某些 FP32 数值不在这个实际动态范围之内我们称之为饱和状态。
(1)最大最小值(MinMax)
这是最简单也是使用比较多的一种采样方法。它的基本思想是直接从 FP32 张量中选取最大值和最小值来确定实际的动态范围,如下公式所示。
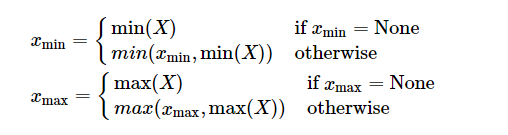
对 weights 而言,这种采样方法是不饱和的。对于 activation 而言,在采样数据部分是不饱和的,但是如果验证集中出现实际动态范围之外的数据,则会出现饱和现象。这种算法的优点是简单直接,但是对于 activation 而言,如果采样数据中出现离群点,则可能明显扩大实际的动态范围,比如实际计算时 99% 的数据都均匀分布在[-100, 100]之间,但是在采样时有一个离群点的数值为10000,这时候采样获得的动态范围就变成[-100, 10000]。
(2)滑动平均最大最小值(MovingAverageMinMax)
与 MinMax 算法直接替换不同,MovingAverageMinMax 会采用一个超参数 c (Pytorch 默认值为0.01)逐步更新动态范围。
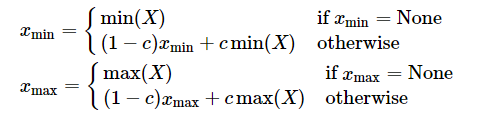
这种方法获得的动态范围一般要小于实际的动态范围。对于 weights 而言,由于不存在采样的迭代,因此 MovingAverageMinMax 与 MinMax 的效果是一样的。
(3)KL 距离采样方法(Kullback–Leibler divergence)
量化是对原始 FP32数据的一种重新编码。一般认为量化之后的数据分布与原始分布越相似,量化对原始数据信息的损失也就越小。KL 距离一般被用来度量两个分布之间的相似性。其基本公式如下:
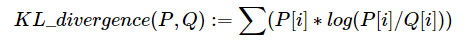
其中P,Q表示两个不同的分布。
动态范围的选取直接决定了量化数据的分布情况,处于动态范围之外的数据将被映射成量化数据的边界点。如下图所示,横坐标表示activation 的取值,纵坐标表示每个取值的归一化统计个数。从图可以看出绝大部分数值都分布在白色直线的左端。通过 KL 距离采样方法就会将动态范围限制在白线左侧的部分,白线右边的值将都会被映射成量化数据的最大值。
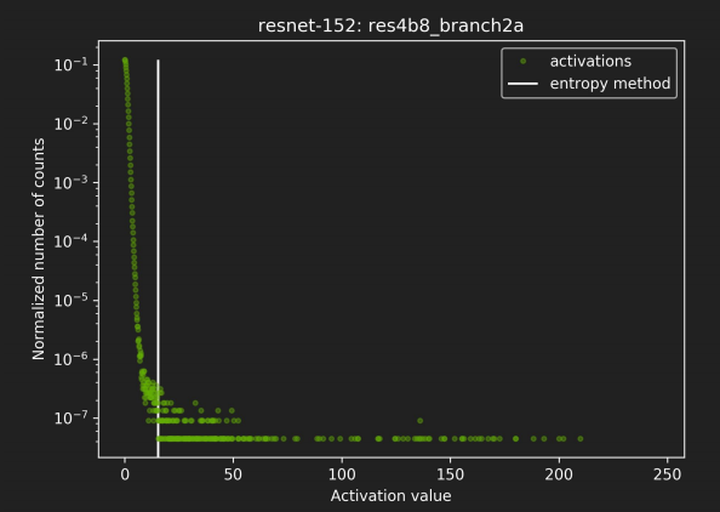
总结一下:从上面的复杂介绍中我们可以看出:KL 距离采样方法从理论上似乎很合理,但是也有几个缺点:
1)动态范围的选取相对耗时。
2)上述算法只是假设左侧动态范围不变的情况下对右边的边界进行选取,对于 RELU 这种数据分布的情况可能很合理,但是如果对于右侧数据明显存在长尾分布的情况可能并不友好。除了具有像RELU等这种具有明显数据分布特征的情况,其他情况我们并不清楚从左边还是从右边来确定动态范围的边界。
3)quantize/expand 方法也只是一定程度上模拟了量化的过程。
3.6 量化粒度
量化粒度一般分为 张量级量化(tensor-wise)和 通道级量化 (channel-wise)。Tensor-wise 量化为一个张量指定一个 scale,是一种粗粒度的量化方式。Channel-wise 量化为每一个通道指定一个 scale 属于一种细粒度的量化方式。
(1)张量级量化(tensor-wise/per_tensor/per_layer)
Activation 和 weights 都可以看做是一个张量,因此在这种量化方式,两者并没有区别。
(2)通道级量化(channel-wise/per_channel)
在深度学习中,张量的每一个通道通常代表一类特征,因此可能会出现不同的通道之间数据分布较大的情况。对于通道之间差异较大的情况仍然使用张量级的量化方式可能对精度产生一定的影响,因此通道级量化就显得格外重要。
对于 activation 而言,在卷积网络中其格式一般为 NCHW。其中 N 为 batch_size,C 为通道数,H 和W分别为高和宽。这时量化将会有C个 scale,即以通道为单位进行量化。
对于 weights 而言,在卷积网络中其格式一般为 OIHW,其中 O 为输出通道数, I 为输入通道数,H 和 W分别为卷积核高和宽。这时量化将会有 O 个scale,即以输出通道为单位进行量化。
3.7 对比分析
在卷积网络中,一般建议对 weights 进行通道级的量化会取得较好的实验结果。下图展示了在一些主流卷积网络上的实验结果,这里 activation 选择了张量级量化,实验对比了 weights 采用不同的量化方法时的精度情况。从对比结果可以看出 weights 采用非对称通道级量化时可以获得较低的精度损失。
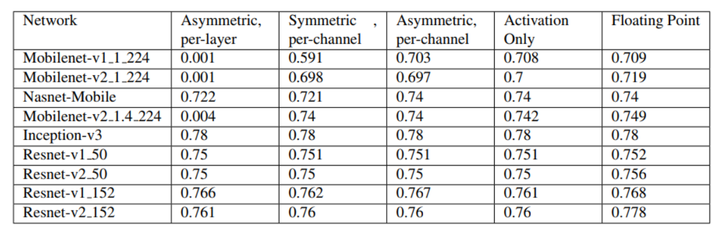
由于 8-bit 整数的动态表示范围明显低于 FP32 浮点数,在模型量化的时候可能会出现精度不达标的问题,但是为了速度也是可以考虑牺牲一些精度的。
上面介绍了各种量化的方法及其优缺点,希望大家对量化算法原理的理解有一些帮助。














 4059
4059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









