







【OVERLORD】使用Paddle实现MRI医学图像超分辨率项目
一、项目背景
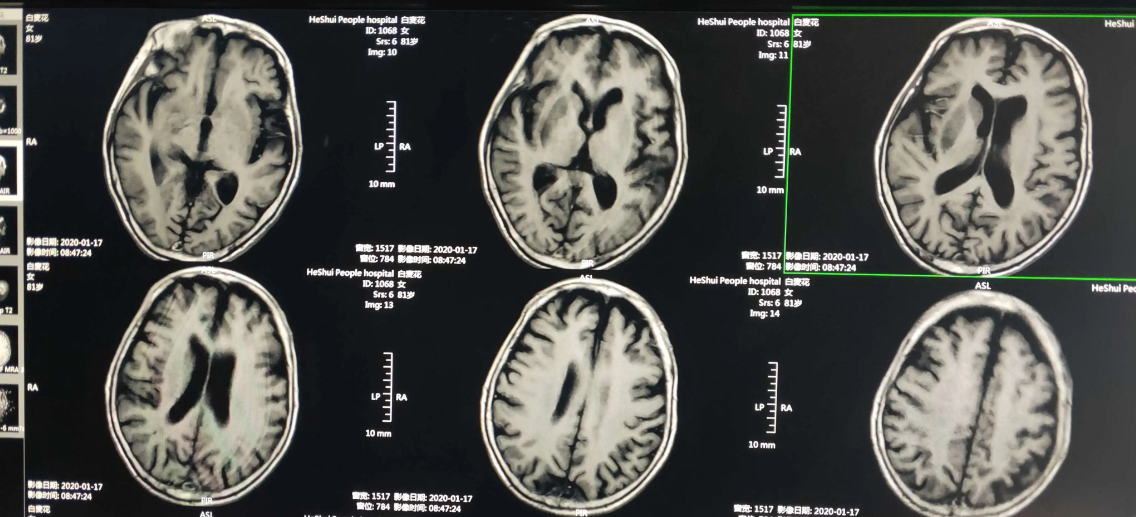
1、核磁共振图像(MRI)
核磁共振成像(Magnetic Resonance Imaging, MRI)是一种非侵入式的活体成像技术,科学将其定义为处于静磁场中的原子核在另一交变电磁场作用下发生的物理现象。通常人们所说的核磁共振就是利用核磁共振现象获取分子结构,以及人体内部结构信息的技术。共振成像的基本原理,是将人体置于特殊的磁场中,用无线电射频脉冲激发人体内氢原子核,引起氢原子核共振并吸收能量,在停止射频脉冲后,氢原子核按特定频率发出射电信号,并将吸收的能量释放出来,被体外的接受器收录,经电子计算机处理获得图像。
核磁共振成像技术提供的信息量不但大于医学影像学中的其他许多成像术,而且不同于已有的成像术。因此,它对疾病的诊断具有很大的潜在优越性。它可以直接作出横断面、矢状面、冠状面和各种斜面的体层图像,并且不会产生CT检测中的伪影;不需注射造影剂;无电离辐射,对机体不良影响较小。共振成像对检测脑内血肿、脑外血肿、脑肿瘤、颅内动脉瘤、动静脉血管畸形、脑缺血、椎管内肿瘤、脊髓空洞症和脊髓积水等疾病非常有效。同时,对腰椎椎间盘后突、原发性肝癌等疾病的诊断也很有效。
当然,共振成像也存在不足之处。它的速度相对较慢,空间分辨率不及CT,且存在运动伪影等。图像重建和超分辨率是MRI中的两项关键技术。前者通过降低空间采样率来加速MRI(但其中涉及到下采样伪影,运动伪影等等处理)相关算法比如并行成像技术,压缩感知成像等等,后者通过恢复单个退化的低分辨率(LR)图像来实现高分辨率(HR)图像,相关算法比如双三次插值等等。
2、核磁共振图像超分辨率重建
高分辨率磁共振 (MR) 成像在许多临床应用中是可取的,因为它的体素尺寸更小,可以为医生提供更加精确的结构和纹理细节,有助于更准确的后续分析和早期临床诊断。然而高分辨率核磁共振图像的生成往往受到许多因素影响,例如硬件设备、成像时间、人身体的运动、环境噪声的影响等等。这些影响因素往往是混合出现的,因此无法只针对其一进行优化。因此为了将磁共振获得到的低分辨率图像进行有效的高分辨率还原,图像超分辨率是一种有效且具有成本效益的优秀技术,可提高 MR 图像的空间分辨率。此技术为低分辨率MRI图像的高信噪比和高分辨率重建提供了可行性。
3、医学图像超分辨率技术的发展
传统的超分辨率算法包括基于插值、基于重建以及基于样例的方法,这些方法普遍难以重建得到图像的高频细节信息,计算较为复杂,重建所需时间较长,并且无法满足X4等尺度的需求。为了解决这些问题,近年来学者们将深度学习应用于超分辨率重建中,并取得了很多的突破,如今,基于深度学习的超分辨率算法已经占据了超分辨率算法研究的主流位置。在医学图像领域中,基于深度学习的超分辨率算法可以从医学影像训练集数据中获取先验知识,并根据这些信息,通过神经网络将低分辨率图像重建为高分辨率图像。
近年来,深度学习尤其是深度卷积神经网络(Convolutional Neural Network,CNN)[1-3] 在MRI重建领域得到了广泛的应用。基于深度学习的MRI成像方法在保证图像精度的同时提高重建速度。Dong[4] 使用超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network, SRCNN)进行图像重建,具有结构简单、容易实现等优点。由于存在采用的卷积层数少、感受野小、泛化能力差等缺陷,使SRCNN因无法提取图像深层次特征而导致重建图像纹理不够清晰。基于参考图像的超分辨率重建(Reference-based Super-Resolution,RefSR)技术在图像重建过程中,通过引入与低分辨率图像具有相似纹理或内容结构的参考图像,将参考图像的高频细节迁移到低分辨率图像(low-resolution,LR)中,从而获得高分辨率图像。
二、项目难点
- 【清晰重建MRI图像细节与边缘】
- 【提升重建MRI图像的高频细节丰富度】
- 【有效减少伪影及噪声】
三、项目方案及数据说明
为了获取更高分辨率的MR图像,我们使用此数据集,和5个简单的模型进行超分辨率重建。
- 数据集及数据加载方法详情:【OVERLORD】IXISR医学图像超分数据集读取实践
1、项目使用的数据集
IXISR dataset[5]是作者Zhao X通过对IXI dataset[6] 进行进一步处理从而构建的。原IXI数据包含三种类型的 MR 图像:581 个 T1 数据、578 个 T2 数据和 578 个 PD 数据。作者取这三个子集的交集,为每种类型的 MR 图像生成 576 个 3D 体积。然后将这些 3D 体积裁剪为 240×240×96(高×宽×深)的大小,以适应 3 个缩放因子(×2、×3 和 ×4)。

- HR图像:为原图像数据。
- LR图像:根据双三次下采样和k空间截断(HR 图像首先通过离散傅里叶变换 (DFT) 转换为 k 空间,然后沿高度和宽度方向进行截断)生成的。
IXISR数据集的维度如下:
训练集LR图像:(500, 120, 120, 96)
训练集HR图像:(500, 240, 240, 96)
验证集LR图像:(6, 120, 120, 96)
验证集HR图像:(6, 240, 240, 96)
测试集LR图像:(70, 120, 120, 96)
测试集HR图像:(70, 240, 240, 96)
2、项目使用的模型
- 模型及模型结构详情:【OVERLORD】使用Paddle实现MRI医学图像超分辨率的模型介绍
| Module | Year |
|---|---|
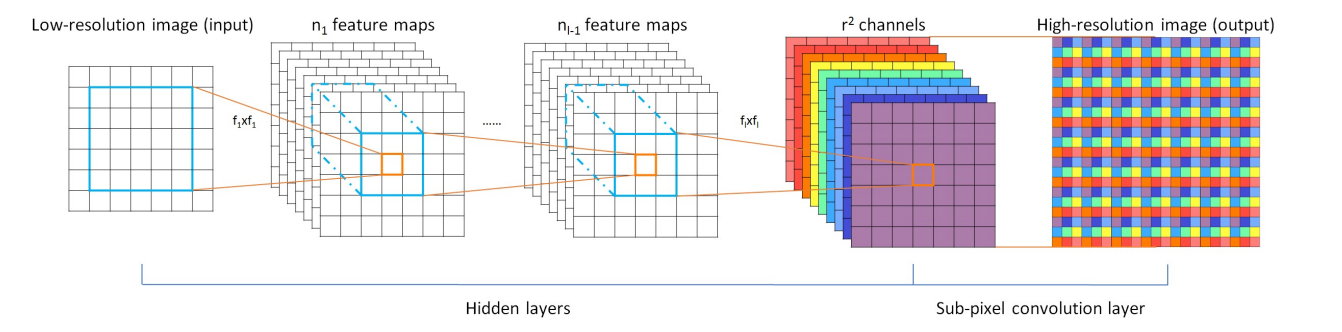
| Sub-Pixel | 2016 |
| Module | Year |
|---|---|
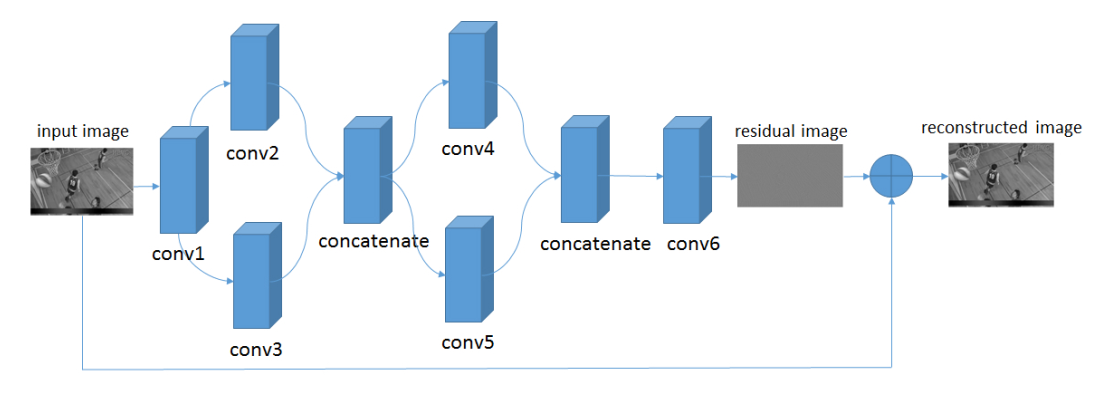
| VRCNN | 2017 |
| Module | Year |
|---|---|
| EDSR | 2017 |
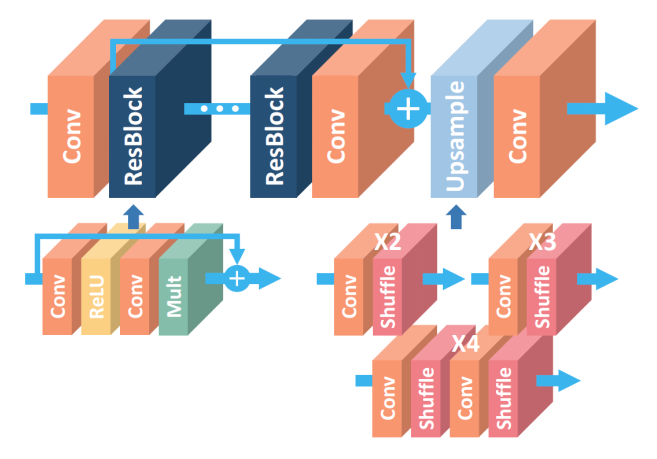
| Module | Year |
|---|---|
| SRResNet | 2017 |
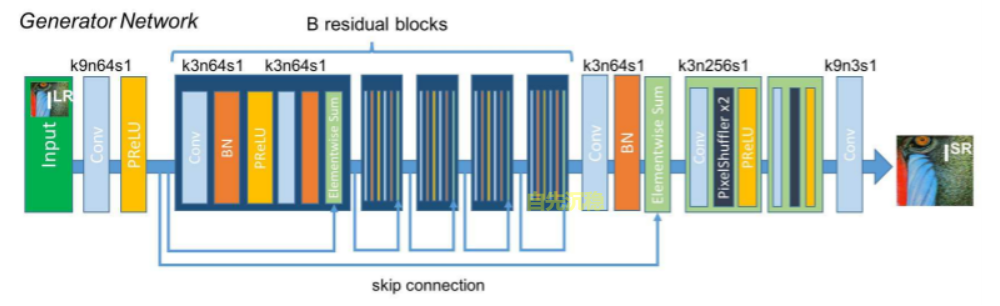
3、其他方法
大家也可以直接使用PaddleHub的预训练模型
| Module | PaddleHub link |
|---|---|
| DCSCN | https://www.paddlepaddle.org.cn/hubdetail?name=dcscn |
| Module | PaddleHub link |
|---|---|
| DCSCN | https://www.paddlepaddle.org.cn/hubdetail?name=dcscn |
| FALSR_A | https://www.paddlepaddle.org.cn/hubdetail?name=falsr_a |
| FALSR_B | https://www.paddlepaddle.org.cn/hubdetail?name=falsr_b |
| FALSR_C | https://www.paddlepaddle.org.cn/hubdetail?name=falsr_c |
大家还可以直接使用PaddleGAN
| Module |
|---|
| RealSR |
| ESRGAN |
| LESRCNN |
| PAN |
| DRN |
四、项目过程
1、解压数据集
In [1]
# 1. 由于压缩包分包了,所以我们需要将它放在一个压缩包内,随后再解压 -q 执行时不显示任何信息
!zip -q -s 0 ./data/data155555/IXISR.zip --out ./data/data155555/IXI.zip
# 2. 随后解压IXISR数据集
!unzip -q -o ./data/data155555/IXI.zip -d ./data/data155555/
!echo "unzip finish!!"unzip finish!!
2、安装并导入包
In [2]
# 安装必要的包
!pip install scikit-image -U -i https://pypi.tuna.tsinghua.edu.cn/simpleLooking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting scikit-image
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/2d/ba/63ce953b7d593bd493e80be158f2d9f82936582380aee0998315510633aa/scikit_image-0.19.3-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (13.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.5/13.5 MB 10.4 MB/s eta 0:00:0000:0100:01
Collecting tifffile>=2019.7.26
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d8/38/85ae5ed77598ca90558c17a2f79ddaba33173b31cf8d8f545d34d9134f0d/tifffile-2021.11.2-py3-none-any.whl (178 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 178.9/178.9 kB 8.8 MB/s eta 0:00:00
Requirement already satisfied: imageio>=2.4.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (2.6.1)
Requirement already satisfied: numpy>=1.17.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (1.19.5)
Requirement already satisfied: networkx>=2.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (2.4)
Requirement already satisfied: packaging>=20.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (21.3)
Collecting PyWavelets>=1.1.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ae/56/4441877073d8a5266dbf7b04c7f3dc66f1149c8efb9323e0ef987a9bb1ce/PyWavelets-1.3.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (6.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.4/6.4 MB 10.7 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: pillow!=7.1.0,!=7.1.1,!=8.3.0,>=6.1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (8.2.0)
Requirement already satisfied: scipy>=1.4.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image) (1.6.3)
Requirement already satisfied: decorator>=4.3.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from networkx>=2.2->scikit-image) (4.4.2)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from packaging>=20.0->scikit-image) (3.0.9)
Installing collected packages: tifffile, PyWavelets, scikit-image
Successfully installed PyWavelets-1.3.0 scikit-image-0.19.3 tifffile-2021.11.2
[notice] A new release of pip available: 22.1.2 -> 22.2
[notice] To update, run: pip install --upgrade pip
In [3]
# 导入包
import math
import skimage
import numpy as np
import matplotlib.pyplot as plt
import os
from PIL import Image
import paddle
import paddle as P
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import ParamAttr
from paddle.distributed import ParallelEnv
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout, AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
nn.initializer.set_global_initializer(nn.initializer.Normal(mean=0.0,std=0.01), nn.initializer.Constant())3、超参数及路径配置
In [4]
# 3. 设置一下各种文件地址
data_mode_index = 0
data_type_index = 0
data_mode = ['bicubic_2x','bicubic_3x','bicubic_4x','truncation_2x','truncation_3x','truncation_4x']
data_type = ['PD','T1','T2']
SCALE = 2
EPOCH = 20
# ./data/data155555/IXI/IXI_LR/bicubic_2x/PD/train
train_LR_path = './data/data155555/IXI/IXI_LR/{}/{}/train'.format(data_mode[data_mode_index],data_type[data_type_index])
train_HR_path = './data/data155555/IXI/IXI_HR/{}/train'.format(data_type[data_type_index])
valid_LR_path = './data/data155555/IXI/IXI_LR/{}/{}/valid'.format(data_mode[data_mode_index],data_type[data_type_index])
valid_HR_path = './data/data155555/IXI/IXI_HR/{}/valid'.format(data_type[data_type_index])
test_LR_path = './data/data155555/IXI/IXI_LR/{}/{}/test'.format(data_mode[data_mode_index],data_type[data_type_index])
test_HR_path = './data/data155555/IXI/IXI_HR/{}/test'.format(data_type[data_type_index])4、加载数据集
In [5]
# 加载所有的npy文件
from glob import glob
import os
import numpy as np
train_LR_paths = sorted(glob(os.path.join(train_LR_path,"*_*.npy")))
train_LR_data = np.array([np.load(fname) for fname in train_LR_paths], dtype='float32')
train_HR_paths = sorted(glob(os.path.join(train_HR_path,"*_*.npy")))
# print(train_HR_paths)
train_HR_data = np.array([np.load(fname) for fname in train_HR_paths], dtype='float32')
valid_LR_paths = sorted(glob(os.path.join(valid_LR_path,"*_*.npy")))
valid_LR_data = np.array([np.load(fname) for fname in valid_LR_paths], dtype='float32')
valid_HR_paths = sorted(glob(os.path.join(valid_HR_path,"*_*.npy")))
valid_HR_data = np.array([np.load(fname) for fname in valid_HR_paths], dtype='float32')
test_LR_paths = sorted(glob(os.path.join(test_LR_path,"*_*.npy")))
test_LR_data = np.array([np.load(fname) for fname in test_LR_paths], dtype='float32')
test_HR_paths = sorted(glob(os.path.join(test_HR_path,"*_*.npy")))
test_HR_data = np.array([np.load(fname) for fname in test_HR_paths], dtype='float32')
# 查看数据维度为多少
print(train_LR_data.shape)
print(train_HR_data.shape)
print(valid_LR_data.shape)
print(valid_HR_data.shape)
print(test_LR_data.shape)
print(test_HR_data.shape)(500, 120, 120, 96) (500, 240, 240, 96) (6, 120, 120, 96) (6, 240, 240, 96) (70, 120, 120, 96) (70, 240, 240, 96)
5、数据转化2D并可视化
In [6]
#将3D切片数据集转化为2D切片数据方便训练
train_LR_data = train_LR_data.transpose([0,3,1,2])
train_HR_data = train_HR_data.transpose([0,3,1,2])
valid_LR_data = valid_LR_data.transpose([0,3,1,2])
valid_HR_data = valid_HR_data.transpose([0,3,1,2])
test_LR_data = test_LR_data .transpose([0,3,1,2])
test_HR_data = test_HR_data .transpose([0,3,1,2])
train_LR_data = train_LR_data.reshape(-1,train_LR_data.shape[2],train_LR_data.shape[3])
train_HR_data = train_HR_data.reshape(-1,train_HR_data.shape[2],train_HR_data.shape[3])
valid_LR_data = valid_LR_data.reshape(-1,valid_LR_data.shape[2],valid_LR_data.shape[3])
valid_HR_data = valid_HR_data.reshape(-1,valid_HR_data.shape[2],valid_HR_data.shape[3])
test_LR_data = test_LR_data .reshape(-1,test_LR_data .shape[2],test_LR_data .shape[3])
test_HR_data = test_HR_data .reshape(-1,test_HR_data .shape[2],test_HR_data .shape[3])
print(train_LR_data.shape)
print(train_HR_data.shape)
print(valid_LR_data.shape)
print(valid_HR_data.shape)
print(test_LR_data.shape)
print(test_HR_data.shape)(48000, 120, 120) (48000, 240, 240) (576, 120, 120) (576, 240, 240) (6720, 120, 120) (6720, 240, 240)
In [8]
# 查看MRI图像
import matplotlib.pyplot as plt
aa = train_LR_data[0,:,:]
bb = train_HR_data[0,:,:]
# 归一化
aa = (aa-aa.min())/(aa.max()-aa.min())
bb = (bb-bb.min())/(bb.max()-bb.min())
fig = plt.figure(figsize=(10,10))
plt.subplot(2,3,1)
plt.imshow(aa,cmap='gray')
plt.subplot(2,3,2)
plt.imshow(bb,cmap='gray')
print(aa.min(),aa.max())
print(aa.min(),bb.max())
plt.show()0.0 1.0 0.0 1.0
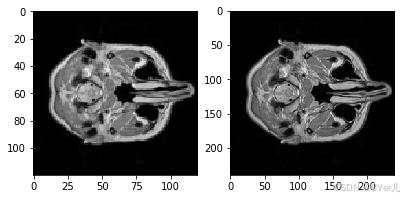
<Figure size 720x720 with 2 Axes>
6、自定义数据加载类 MyDataset
In [13]
# 没有进行patch分割成小块训练的
from paddle.io import Dataset # 导入类库 Dataset
from paddle.vision.transforms import ToTensor
class MyDataset(Dataset): # 定义Dataset的子类MyDataset
def __init__(self, mode='train',transform=ToTensor()):
super(MyDataset, self).__init__()
self.mode = mode
if mode == 'train':
self.LR_data = train_LR_data
self.HR_data = train_HR_data
elif mode == 'valid':
self.LR_data = valid_LR_data
self.HR_data = valid_HR_data
else:
self.LR_data = test_LR_data
self.HR_data = test_HR_data
self.transform = transform
def data_augmentation(self,LR, HR): # 数据增强:随机翻转、旋转
if np.random.randint(2) == 1:
LR = LR[:,::-1]
HR = HR[:,::-1]
n = np.random.randint(4)
if n == 1:
LR = LR[::-1,:].transpose([1,0])
HR = HR[::-1,:].transpose([1,0])
if n == 2:
LR = LR[::-1,::-1]
HR = HR[::-1,::-1]
if n == 3:
LR = LR[:,::-1].transpose([1,0])
HR = HR[:,::-1].transpose([1,0])
return LR, HR
def __getitem__(self, index):
LR = self.LR_data[index]
HR = self.HR_data[index]
LR = (LR-LR.min())/(LR.max()-LR.min())
HR = (HR-HR.min())/(HR.max()-HR.min())
# 修改归一化
if(self.mode=='train'):
LR,HR = self.data_augmentation(LR,HR)
LR = self.transform(LR)
HR = self.transform(HR)
return LR, HR
def __len__(self):
return self.LR_data.shape[0]
# 以下是我测试时写的,没太大用
# if __name__ == '__main__':
# import cv2
# from tqdm import tqdm_notebook
# test_dataset = MyDataset(mode='test')
# psnr_list = []
# ssim_list = []
# psnr = PSNR()
# ssim = SSIM()
# for i in tqdm_notebook(range(len(test_dataset))):
# lr,hr = test_dataset[i]
# hrr = lr[0,:,:].numpy()
# hrr = cv2.resize(hrr,(hrr.shape[0]*2,hrr.shape[1]*2),interpolation=cv2.INTER_CUBIC)
# hrr = paddle.Tensor(hrr)
# ssim.update(hrr.unsqueeze(0).unsqueeze(0),hr.unsqueeze(0))
# psnr.update(hrr.unsqueeze(0).unsqueeze(0),hr.unsqueeze(0))
# psnr_list.append(psnr.psnr)
# ssim_list.append(ssim.ssim)
# plt.figure(figsize=(10,10))
# plt.subplot(1,3,1)
# plt.imshow(lr[0],cmap='gray')
# plt.subplot(1,3,2)
# plt.imshow(hr[0],cmap='gray')
# plt.subplot(1,3,3)
# plt.imshow(hrr,cmap='gray')
# plt.show()
# print(psnr.accumulate())
# print(ssim.accumulate())
# psnr_list = np.array(psnr_list)
# ssim_list = np.array(ssim_list)
# print(psnr_list.mean())
# print(ssim_list.mean())
if __name__ == '__main__':
test_dataset = MyDataset(mode='train')
lr,hr = test_dataset[0]
print(np.array(lr).min(),np.array(lr).max())
print(np.array(hr).min(),np.array(hr).max())
plt.subplot(1,2,1)
plt.imshow(lr[0],cmap='gray')
plt.subplot(1,2,2)
plt.imshow(hr[0],cmap='gray')
plt.show()
0.0 1.0 0.0 1.0
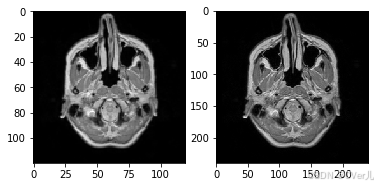
<Figure size 432x288 with 2 Axes>
In [15]
# 进行patch分割成小块训练的
from paddle.io import Dataset # 导入类库 Dataset
from paddle.vision.transforms import ToTensor
class MyDataset(Dataset): # 定义Dataset的子类MyDataset
def __init__(self, mode='train',transform=ToTensor(),scale=2,patchsize=[24,24]):
super(MyDataset, self).__init__()
self.scale = scale
self.patchsize = patchsize
self.mode = mode
if mode == 'train':
self.LR_data = train_LR_data
self.HR_data = train_HR_data
elif mode == 'valid':
self.LR_data = valid_LR_data
self.HR_data = valid_HR_data
else:
self.LR_data = test_LR_data
self.HR_data = test_HR_data
self.transform = transform
def data_augmentation(self,LR, HR): #数据增强:随机翻转、旋转
if np.random.randint(2) == 1:
LR = LR[:,::-1]
HR = HR[:,::-1]
n = np.random.randint(4)
if n == 1:
LR = LR[::-1,:].transpose([1,0])
HR = HR[::-1,:].transpose([1,0])
if n == 2:
LR = LR[::-1,::-1]
HR = HR[::-1,::-1]
if n == 3:
LR = LR[:,::-1].transpose([1,0])
HR = HR[:,::-1].transpose([1,0])
return LR, HR
def getPatch(self,LR, HR):
sz = LR.shape
##对图片进行裁剪
sz_row = sz[1] // (self.patchsize[0]*self.scale) * self.patchsize[0]*self.scale
sz_col = sz[0] // (self.patchsize[1]*self.scale) * self.patchsize[1]*self.scale
dif_row = sz[1] - sz_row
dif_col = sz[0] - sz_col
row_min = np.random.randint(dif_row + 1) #设置随机裁剪行的起点
col_min = np.random.randint(dif_col + 1) #设置随机裁剪列的起点
LRP = LR[row_min:row_min+self.patchsize[0],col_min:col_min+self.patchsize[1]]
HRP = HR[row_min*self.scale:(row_min+self.patchsize[0])*self.scale,col_min*self.scale:(col_min+self.patchsize[1])*self.scale]
return LRP,HRP
def __getitem__(self, index):
LR = self.LR_data[index]
HR = self.HR_data[index]
LR = (LR-LR.min())/(LR.max()-LR.min())
HR = (HR-HR.min())/(HR.max()-HR.min())
if(self.mode=='train'):
LR,HR = self.getPatch(LR,HR)
LR,HR = self.data_augmentation(LR,HR)
LR = self.transform(LR)
HR = self.transform(HR)
return LR , HR
def __len__(self):
return self.LR_data.shape[0]
if __name__ == '__main__':
test_dataset = MyDataset(mode='train')
lr,hr = test_dataset[0]
print(np.array(lr).min(),np.array(lr).max())
print(np.array(hr).min(),np.array(hr).max())
plt.subplot(1,2,1)
plt.imshow(lr[0],cmap='gray')
plt.subplot(1,2,2)
plt.imshow(hr[0],cmap='gray')
plt.show()
0.0 1.0 0.0 1.0
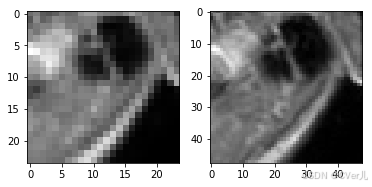
<Figure size 432x288 with 2 Axes>
7、自定义评估函数 MyMetrics
In [16]
from paddle.metric import Metric
##########################################
#
# PSNR 评估指标(峰值信噪比)
#
##########################################
class PSNR(Metric):
def __init__(self, name='psnr', *args, **kwargs):
super(PSNR, self).__init__(*args, **kwargs)
self.psnr = 0
self._name = name
self.count = 0
def _is_numpy_(self,var):
return isinstance(var, (np.ndarray, np.generic))
def update(self, preds, labels):
if isinstance(preds, paddle.Tensor):
# preds = paddle.nn.functional.sigmoid(preds)
preds = preds.numpy()
elif not self._is_numpy_(preds):
raise ValueError("The 'preds' must be a numpy ndarray or Tensor.")
if isinstance(labels, paddle.Tensor):
labels = labels.numpy()
elif not self._is_numpy_(labels):
raise ValueError("The 'labels' must be a numpy ndarray or Tensor.")
B,C,H,W = preds.shape[0],preds.shape[1],preds.shape[2],preds.shape[3]
temp = 0
for b in range(B):
for c in range(C):
temp += skimage.metrics.peak_signal_noise_ratio(preds[b,c,:,:], labels[b,c,:,:], data_range=1)
temp = temp/(B*C)
self.psnr += temp
self.count += 1
def reset(self):
self.psnr = 0
self.count = 0
def accumulate(self):
return self.psnr/self.count
def name(self):
return self._name
##########################################
#
# SSIM 评估指标(结构相似性)
#
##########################################
class SSIM(Metric):
def __init__(self, name='ssim', *args, **kwargs):
super(SSIM, self).__init__(*args, **kwargs)
self.ssim = 0
self._name = name
self.count = 0
def _is_numpy_(self,var):
return isinstance(var, (np.ndarray, np.generic))
def update(self, preds, labels):
if isinstance(preds, paddle.Tensor):
# preds = paddle.nn.functional.sigmoid(preds)
preds = preds.numpy()
elif not self._is_numpy_(preds):
raise ValueError("The 'preds' must be a numpy ndarray or Tensor.")
if isinstance(labels, paddle.Tensor):
labels = labels.numpy()
elif not self._is_numpy_(labels):
raise ValueError("The 'labels' must be a numpy ndarray or Tensor.")
B,C,H,W = preds.shape[0],preds.shape[1],preds.shape[2],preds.shape[3]
temp = 0
for b in range(B):
for c in range(C):
temp += skimage.metrics.structural_similarity(preds[b,c,:,:], labels[b,c,:,:], data_range=1)
temp = temp/(B*C)
self.ssim += temp
self.count += 1
def reset(self):
self.ssim = 0
self.count = 0
def accumulate(self):
return self.ssim/self.count
def name(self):
return self._name
##########################################
#
# MSE 评估指标(均方误差)
#
##########################################
class MSE(Metric):
def __init__(self, name='mse', *args, **kwargs):
super(MSE, self).__init__(*args, **kwargs)
self.mse = 0
self._name = name
self.count = 0
def _is_numpy_(self,var):
return isinstance(var, (np.ndarray, np.generic))
def update(self, preds, labels):
if isinstance(preds, paddle.Tensor):
# preds = paddle.nn.functional.sigmoid(preds)
preds = preds.numpy()
elif not self._is_numpy_(preds):
raise ValueError("The 'preds' must be a numpy ndarray or Tensor.")
if isinstance(labels, paddle.Tensor):
labels = labels.numpy()
elif not self._is_numpy_(labels):
raise ValueError("The 'labels' must be a numpy ndarray or Tensor.")
B,C,H,W = preds.shape[0],preds.shape[1],preds.shape[2],preds.shape[3]
temp = 0
for b in range(B):
for c in range(C):
temp += skimage.metrics.mean_squared_error(preds[b,c,:,:], labels[b,c,:,:])
temp = temp/(B*C)
self.mse += temp
self.count += 1
def reset(self):
self.mse = 0
self.count = 0
def accumulate(self):
return self.mse/self.count
def name(self):
return self._name
##########################################
#
# RMSE 评估指标(均方根误差)
#
##########################################
class RMSE(Metric):
def __init__(self, name='rmse', *args, **kwargs):
super(RMSE, self).__init__(*args, **kwargs)
self.rmse = 0
self._name = name
self.count = 0
def _is_numpy_(self,var):
return isinstance(var, (np.ndarray, np.generic))
def update(self, preds, labels):
if isinstance(preds, paddle.Tensor):
# preds = paddle.nn.functional.sigmoid(preds)
preds = preds.numpy()
elif not self._is_numpy_(preds):
raise ValueError("The 'preds' must be a numpy ndarray or Tensor.")
if isinstance(labels, paddle.Tensor):
labels = labels.numpy()
elif not self._is_numpy_(labels):
raise ValueError("The 'labels' must be a numpy ndarray or Tensor.")
B,C,H,W = preds.shape[0],preds.shape[1],preds.shape[2],preds.shape[3]
temp = 0
for b in range(B):
for c in range(C):
temp += skimage.metrics.mean_squared_error(preds[b,c,:,:], labels[b,c,:,:])
temp = temp/(B*C)
temp = math.sqrt(temp)
self.rmse += temp
self.count += 1
def reset(self):
self.rmse = 0
self.count = 0
def accumulate(self):
return self.rmse/self.count
def name(self):
return self._name
##########################################
#
# NRMSE 评估指标(归一化均方根误差)
#
##########################################
class NRMSE(Metric):
def __init__(self, name='nrmse', *args, **kwargs):
super(NRMSE, self).__init__(*args, **kwargs)
self.nrmse = 0
self._name = name
self.count = 0
def _is_numpy_(self,var):
return isinstance(var, (np.ndarray, np.generic))
def update(self, preds, labels):
if isinstance(preds, paddle.Tensor):
# preds = paddle.nn.functional.sigmoid(preds)
preds = preds.numpy()
elif not self._is_numpy_(preds):
raise ValueError("The 'preds' must be a numpy ndarray or Tensor.")
if isinstance(labels, paddle.Tensor):
labels = labels.numpy()
elif not self._is_numpy_(labels):
raise ValueError("The 'labels' must be a numpy ndarray or Tensor.")
B,C,H,W = preds.shape[0],preds.shape[1],preds.shape[2],preds.shape[3]
temp = 0
for b in range(B):
for c in range(C):
temp += skimage.metrics.normalized_root_mse(preds[b,c,:,:], labels[b,c,:,:])
temp = temp/(B*C)
self.nrmse += temp
self.count += 1
def reset(self):
self.nrmse = 0
self.count = 0
def accumulate(self):
return self.nrmse/self.count
def name(self):
return self._name
8、自定义损失函数 MyLosses
In [18]
# 超分常用的loss参考:https://zhuanlan.zhihu.com/p/366274586
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import numpy as np
from math import exp
#from work.models.VGG import vgg19
# 计算一维的高斯分布向量
def gaussian(window_size, sigma):
gauss = paddle.to_tensor([exp(-(x - window_size/2)**2/float(2*sigma**2)) for x in range(window_size)])
return gauss/gauss.sum()
# 创建高斯核,通过两个一维高斯分布向量进行矩阵乘法得到
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).astype('float32').unsqueeze(0).unsqueeze(0)
window = paddle.to_tensor(_2D_window.expand([channel, 1, window_size, window_size]))
return window
# 计算SSIM
# 直接使用SSIM的公式,但是在计算均值时,不是直接求像素平均值,而是采用归一化的高斯核卷积来代替。
# 在计算方差和协方差时用到了公式Var(X)=E[X^2]-E[X]^2, cov(X,Y)=E[XY]-E[X]E[Y].
# 正如前面提到的,上面求期望的操作采用高斯核卷积代替
def _ssim(img1, img2, window, window_size, channel, size_average = True):
img1= paddle.to_tensor(img1)
img2= paddle.to_tensor(img2)
mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq #Var(X)=E[X^2]-E[X]^2
sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2 #cov(X,Y)=E[XY]-E[X]E[Y]
C1 = 0.01**2
C2 = 0.03**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
#类重用窗口
class SSIMLoss(nn.Layer):
def __init__(self, window_size = 11, size_average = True):
super(SSIMLoss, self).__init__() #对继承自父类的属性进行初始化。而且是用父类的初始化方法来初始化继承的属性。
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
self.l1=paddle.nn.L1Loss(reduction='mean')
def forward(self, img1, img2):
l1loss = self.l1(img1,img2)
(_, channel, _, _) = img1.shape
if channel == self.channel:
window = self.window
else:
window = create_window(self.window_size, channel)
self.window = window
self.channel = channel
return l1loss+0.2*(1 - _ssim(img1, img2, window, self.window_size, channel, self.size_average))
def ssim(img1, img2, window_size = 11, size_average = True):
(_, channel, _, _) = img1.shape
window = create_window(window_size, channel)
return _ssim(img1, img2, window, window_size, channel, size_average)
def expandedSobel(inputTensor,sobelFilter):
#this considers data_format = 'NCHW'
inputChannels = paddle.reshape(paddle.ones_like(inputTensor[0,:,0,0]),(1,1,-1,1))
return sobelFilter * inputChannels
class AdvSoberLoss(nn.Layer):
def __init__(self, alpha=0.25):
super(AdvSoberLoss, self).__init__()
self.sobelFilter = paddle.to_tensor([[[[0., 2.]], [[-1., 1.]],[[-2., 0.]]],
[[[1., 1.]], [[0., 0.]],[[-1., -1.]]],
[[[2., 0.]], [[1., -1.]],[[0., -2.]]]], dtype='float32').reshape(
(3,3, 1, 2))
#print(self.sobelFilter)
self.alpha=alpha
self.l1_loss = paddle.nn.L1Loss(reduction='mean')
def forward(self, logits1,label):
label.stop_gradient = True
filt = expandedSobel(label,self.sobelFilter)
total_loss=0
sobelLabel = F.conv2d(label,filt)
sobelPred = F.conv2d(logits1,filt)
sobelLoss = paddle.mean(paddle.abs(sobelLabel - sobelPred))
Loss= self.l1_loss(logits1,label)+self.alpha*sobelLoss
total_loss=Loss
return total_loss
from paddle.vision.models import vgg19
class LossVGG19(nn.Layer):
def __init__(self):
super(LossVGG19, self).__init__()
self.vgg_layers = vgg19(pretrained=True).features
self.layer_name_mapping = {
'3': "relu1",
'8': "relu2",
'13': "relu3",
'22': "relu4",
'31': "relu5", # 1_2 to 5_2
}
def forward(self, x):
output = {}
for name, module in self.vgg_layers._sub_layers.items():
x = module(x)
if name in self.layer_name_mapping:
output[self.layer_name_mapping[name]] = x
return output
def loss_textures(x, y, nc=3, alpha=1.2, margin=0):
xi = x.reshape([x.shape[0], -1, nc, x.shape[2], x.shape[3]])
yi = y.reshape([y.shape[0], -1, nc, y.shape[2], y.shape[3]])
xi2 = paddle.sum(xi * xi, axis=2)
yi2 = paddle.sum(yi * yi, axis=2)
out = paddle.nn.functional.relu(yi2 * alpha - xi2 + margin)
return paddle.mean(out)
class nTVLoss(nn.Layer):
def __init__(self, weight=1):
super(nTVLoss, self).__init__()
self.weight = weight
def forward(self, x, label):
batch_size = x.shape[0]
h_x = x.shape[2]
w_x = x.shape[3]
count_h = self._tensor_size(x[:, :, 1:, :])
count_w = self._tensor_size(x[:, :, :, 1:])
h_tv = paddle.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
w_tv = paddle.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
l_tv = paddle.pow((x[:, :, :h_x - 1, :w_x - 1] - x[:, :, 1:, 1:]), 2).sum()
r_tv = paddle.pow((x[:, :, :h_x - 1, 1:w_x] - x[:, :, 1:, :w_x - 1]), 2).sum()
return self.weight * 2 * (h_tv + l_tv + r_tv + w_tv ) / count_w / batch_size
def _tensor_size(self, t):
return t.shape[1] * t.shape[2] * t.shape[3]
class L1_Charbonnier_loss(nn.Layer):
"""L1 Charbonnierloss."""
def __init__(self):
super(L1_Charbonnier_loss, self).__init__()
self.eps = 1e-6
def forward(self, X, Y):
diff = P.add(X, -Y)
error = P.sqrt(diff * diff + self.eps)
loss = P.mean(error)
return loss
class MY_loss(nn.Layer):
def __init__(self):
super(MY_loss, self).__init__()
self.l1closs = L1_Charbonnier_loss()
self.mse = paddle.nn.MSELoss()
self.vggex = LossVGG19()
self.sobelloss = AdvSoberLoss()
def forward(self, X, Y):
loss1 = self.l1closs(X, Y)
loss2 = self.mse(X, Y)
NEW_X = paddle.concat([X,X,X],axis=1)
NEW_Y = paddle.concat([Y,Y,Y],axis=1)
loss4 = self.sobelloss(NEW_X, NEW_Y)
NEW_X = self.vggex(NEW_X)
NEW_Y = self.vggex(NEW_Y)
loss3 = self.mse(NEW_X["relu2"],NEW_Y["relu2"])
loss = loss1 + loss2 + 0.1 * loss3 + 0.1 * loss4
return loss
if __name__ == '__main__':
inp = P.randn((1, 1, 10, 10),dtype='float32')
net = MY_loss()
out = net(inp,inp)
print('inp',inp.shape)
print('out',out.shape)
# psnr_metric = PSNR()
# ssim_metric = SSIM()
# mse_metric = MSE()
# rmse_metric = RMSE()
# nrmse_metric = NRMSE()
# TV_criterion = nTVLoss() # 用于规范图像噪声
# ssim_criterion = SSIMLoss() # SSIM loss
# sobel_loss = AdvSoberLoss() # 梯度loss
# lossnet = LossVGG19() # 感知loss
# l1_loss = paddle.nn.L1Loss() # L1 loss
# Mse_loss = nn.MSELoss() # MSE lossinp [1, 1, 10, 10] out [1]
9、自定义回调函数 ModelCheckpoint
In [49]
class ModelCheckpoint(paddle.callbacks.Callback):
"""
继承paddle.callbacks.Callback,该类的功能是
训练模型时自动存储每轮训练得到的模型
"""
def __init__(self, save_freq=1, save_dir=None):
"""
构造函数实现
"""
self.save_freq = save_freq
self.save_dir = save_dir
self.max_psnr = 0
self.max_ssim = 0
def on_epoch_begin(self, epoch=None, logs=None):
"""
每轮训练开始前,获取当前轮数
"""
self.epoch = epoch
def _is_save(self):
return self.model and self.save_dir and ParallelEnv().local_rank == 0
def on_epoch_end(self, epoch, logs=None):
"""
每轮训练结束后,保存验证集最大psnr和ssim的checkpoint
"""
eval_result = self.model.evaluate(valid_dataset, verbose=1)
if self._is_save() and eval_result['psnr'] >= self.max_psnr and eval_result['ssim'] >= self.max_ssim:
self.max_psnr = eval_result['psnr']
self.max_ssim = eval_result['ssim']
path = '{}/{}_{}'.format(self.save_dir, self.max_psnr, self.max_ssim)
print('save checkpoint at {}'.format(os.path.abspath(path)))
self.model.save(path)
# def on_train_end(self, logs=None):
# """
# 训练结束后,保存最后一轮的checkpoint
# """
# if self._is_save():
# path = '{}/final'.format(self.save_dir)
# print('save checkpoint at {}'.format(os.path.abspath(path)))
# self.model.save(path)10、自定义模型
10.1、Sub_Pixel_CNN
In [23]
class Sub_Pixel_CNN(nn.Layer):
# Sub_Pixel_CNN(upscale_factor=2, channels=1)
def __init__(self, upscale_factor=2, channels=1):
super(Sub_Pixel_CNN, self).__init__()
self.conv1 = paddle.nn.Conv2D(channels,64,5,stride=1, padding=2)
self.conv2 = paddle.nn.Conv2D(64,64,3,stride=1, padding=1)
self.conv3 = paddle.nn.Conv2D(64,32,3,stride=1, padding=1)
self.conv4 = paddle.nn.Conv2D(32,channels * (upscale_factor ** 2),3,stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = paddle.nn.functional.pixel_shuffle(x,2)
return x10.2、VRCNN
In [24]
# 定义模型结构
class VRCNN(nn.Layer):
def __init__(self):
super(VRCNN, self).__init__()
self.conv1 = nn.Sequential(
# 定义一个卷积层conv1,输入通道是1,输出通道64,卷积核大小为5,步长为1,padding为2,使用relu激活函数
nn.Conv2D(1, 64, 5, stride=1, padding=2),
nn.BatchNorm(64),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
# 定义一个卷积层conv2,输入通道是64,输出通道16,卷积核大小为5,步长为1,padding为2,使用relu激活函数
nn.Conv2D(64, 16, 5, stride=1, padding=2),
nn.BatchNorm(16),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
# 定义一个卷积层conv3,输入通道是64,输出通道32,卷积核大小为3,步长为1,padding为1,使用relu激活函数
nn.Conv2D(64, 32, 3, stride=1, padding=1),
nn.BatchNorm(32),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
# 定义一个卷积层conv4,输入通道是48,输出通道16,卷积核大小为3,步长为1,padding为1,使用relu激活函数
nn.Conv2D(48, 16, 3, stride=1, padding=1),
nn.BatchNorm(16),
nn.ReLU(),
)
self.conv5 = nn.Sequential(
# 定义一个卷积层conv5,输入通道是48,输出通道32,卷积核大小为1,步长为1,padding为0,使用relu激活函数
nn.Conv2D(48, 32, 1, stride=1, padding=0),
nn.BatchNorm(32),
nn.ReLU(),
)
self.conv6 = nn.Sequential(
# 定义一个卷积层conv6,输入通道是48,输出通道1,卷积核大小为3,步长为1,padding为1,使用relu激活函数
nn.Conv2D(48, 1, 3, stride=1, padding=1),
nn.BatchNorm(1),
)
self.relu = nn.ReLU()
# 定义网络的前向计算过程
def forward(self, inputs):
inputs = F.interpolate(x=inputs, scale_factor=[2,2], mode="bilinear")
x = self.conv1(inputs)
x1 = self.conv2(x)
x2 = self.conv3(x)
x = paddle.concat(x=[x1, x2], axis=1)
x3 = self.conv4(x)
x4 = self.conv5(x)
x = paddle.concat(x=[x3, x4], axis=1)
x = self.conv6(x)
x = x + inputs
x = self.relu(x)
#print("x.shape = {}".format(x.shape))
return x
if __name__ == '__main__':
img_channel = 1
width = 64
net = VRCNN()
inp = P.randn((1, 1, 120, 120),dtype='float32')
out = net(inp)
print('inp',inp.shape)
print('out',out.shape)inp [1, 1, 120, 120] out [1, 1, 240, 240]
10.3、EDSR
In [25]
from paddle.nn import Layer
from paddle import nn
import math
n_feat = 64
kernel_size = 3
# 残差块 尺寸不变
class _Res_Block(nn.Layer):
def __init__(self):
super(_Res_Block, self).__init__()
self.res_conv = nn.Conv2D(n_feat, n_feat, kernel_size, padding=1)
self.relu = nn.ReLU()
def forward(self, x):
y = self.relu(self.res_conv(x))
y = self.res_conv(y)
y *= 0.1
# 残差加入
y = paddle.add(y, x)
return y
class EDSR(nn.Layer):
def __init__(self):
super(EDSR, self).__init__()
in_ch = 1
num_blocks = 32
self.conv1 = nn.Conv2D(in_ch, n_feat, kernel_size, padding=1)
# 扩大
self.conv_up = nn.Conv2D(n_feat, n_feat * 4, kernel_size, padding=1)
self.conv_out = nn.Conv2D(n_feat, in_ch, kernel_size, padding=1)
self.body = self.make_layer(_Res_Block, num_blocks)
# 上采样
self.upsample = nn.Sequential(self.conv_up, nn.PixelShuffle(2))
# 32个残差块
def make_layer(self, block, layers):
res_block = []
for _ in range(layers):
res_block.append(block())
return nn.Sequential(*res_block)
def forward(self, x):
out = self.conv1(x)
out = self.body(out)
out = self.upsample(out)
out = self.conv_out(out)
return out10.4、SRResNet
In [35]
from paddle.nn import Layer
from paddle import nn
import math
# 是可以保持w,h不变的
class ConvolutionalBlock(nn.Layer):
"""
卷积模块,由卷积层, BN归一化层, 激活层构成.
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, batch_norm=False, activation=None):
"""
:参数 in_channels: 输入通道数
:参数 out_channels: 输出通道数
:参数 kernel_size: 核大小
:参数 stride: 步长
:参数 batch_norm: 是否包含BN层
:参数 activation: 激活层类型; 如果没有则为None
"""
super(ConvolutionalBlock, self).__init__()
if activation is not None:
activation = activation.lower()
assert activation in {'prelu', 'leakyrelu', 'tanh'}
# 层列表
layers = list()
# 1个卷积层
layers.append(
nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2))
# 1个BN归一化层
if batch_norm is True:
layers.append(nn.BatchNorm2D(num_features=out_channels))
# 1个激活层
if activation == 'prelu':
layers.append(nn.PReLU())
elif activation == 'leakyrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'tanh':
layers.append(nn.Tanh())
# 合并层
self.conv_block = nn.Sequential(*layers)
def forward(self, input):
output = self.conv_block(input)
return output
# w,h放大
class SubPixelConvolutionalBlock(nn.Layer):
def __init__(self, kernel_size=3, n_channels=64, scaling_factor=2):
super(SubPixelConvolutionalBlock, self).__init__()
# 首先通过卷积将通道数扩展为 scaling factor^2 倍
self.conv = nn.Conv2D(in_channels=n_channels, out_channels=n_channels * (scaling_factor ** 2),
kernel_size=kernel_size, padding=kernel_size // 2)
# 进行像素清洗,合并相关通道数据 放大了图像
self.pixel_shuffle = nn.PixelShuffle(upscale_factor=scaling_factor)
# 最后添加激活层
self.prelu = nn.PReLU()
def forward(self, input):
output = self.conv(input)
output = self.pixel_shuffle(output)
output = self.prelu(output)
return output
class ResidualBlock(nn.Layer):
"""
残差模块, 包含两个卷积模块和一个跳连.
"""
def __init__(self, kernel_size=3, n_channels=64):
"""
:参数 kernel_size: 核大小
:参数 n_channels: 输入和输出通道数(由于是ResNet网络,需要做跳连,因此输入和输出通道数是一致的)
"""
super(ResidualBlock, self).__init__()
self.conv_block1 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation='PReLu')
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation=None)
def forward(self, input):
"""
前向传播.
:参数 input: 输入图像集,张量表示,大小为 (N, n_channels, w, h)
:返回: 输出图像集,张量表示,大小为 (N, n_channels, w, h)
"""
residual = input # (N, n_channels, w, h)
output = self.conv_block1(input) # (N, n_channels, w, h)
output = self.conv_block2(output) # (N, n_channels, w, h)
output = output + residual # (N, n_channels, w, h)
return output
class SRResNet(nn.Layer):
# SRResNet(scaling_factor=2)
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=2):
"""
:参数 large_kernel_size: 第一层卷积和最后一层卷积核大小
:参数 small_kernel_size: 中间层卷积核大小
:参数 n_channels: 中间层通道数
:参数 n_blocks: 残差模块数
:参数 scaling_factor: 放大比例
"""
super(SRResNet, self).__init__()
# 放大比例必须为 2、 4 或 8
scaling_factor = int(scaling_factor)
assert scaling_factor in {2, 4, 8}, "放大比例必须为 2、 4 或 8!"
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock(in_channels=1, out_channels=n_channels, kernel_size=large_kernel_size,
batch_norm=False, activation='PReLu')
# 一系列残差模块, 每个残差模块包含一个跳连接
self.residual_blocks = nn.Sequential(
*[ResidualBlock(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)])
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels,
kernel_size=small_kernel_size,
batch_norm=True, activation=None)
# 放大通过子像素卷积模块实现, 每个模块放大两倍 log2 2=1
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(
*[SubPixelConvolutionalBlock(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i
in range(n_subpixel_convolution_blocks)])
# 最后一个卷积模块
self.conv_block3 = ConvolutionalBlock(in_channels=n_channels, out_channels=1, kernel_size=large_kernel_size,
batch_norm=False, activation='Tanh')
def forward(self, lr_imgs):
"""
:参数 lr_imgs: 低分辨率输入图像集, 张量表示,大小为 (N, 3, w, h)
:返回: 高分辨率输出图像集, 张量表示, 大小为 (N, 3, w * scaling factor, h * scaling factor)
"""
output = self.conv_block1(lr_imgs) # (16, 3, 24, 24)
residual = output # (16, 64, 24, 24)
output = self.residual_blocks(output) # (16, 64, 24, 24)
output = self.conv_block2(output) # (16, 64, 24, 24)
output = output + residual # (16, 64, 24, 24)
output = self.subpixel_convolutional_blocks(output) # (16, 64, 24 * 2, 24 * 2)
sr_imgs = self.conv_block3(output) # (16, 3, 24 * 2, 24 * 2)
return sr_imgs
if __name__ == '__main__':
img_channel = 1
width = 64
net = SRResNet()
inp = P.randn((1, 1, 120, 120),dtype='float32')
out = net(inp)
print('inp',inp.shape)
print('out',out.shape)inp [1, 1, 120, 120] out [1, 1, 240, 240]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
10.5、修改的SRResNet
In [36]
# cite: https://aistudio.baidu.com/aistudio/projectdetail/2884850?channelType=0&channel=0
import paddle
from paddle.fluid.layers.nn import transpose
import paddle.nn as nn
import math
import paddle.nn.functional as F
class simam_module(nn.Layer):
def __init__(self, channels, e_lambda = 1e-4):
super(simam_module, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.shape
n = w * h - 1
x_minus_mu_square = (x - x.mean(axis=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(axis=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
# return x * y
if __name__ == '__main__':
x = paddle.randn(shape=[1, 16, 64, 64]) # b, c, h, w
simam = simam_module(16)
y = simam(x)
print(y.shape)[1, 16, 64, 64]
In [37]
class LayerNormFunction(P.autograd.PyLayer):
@staticmethod
def forward(ctx, x, weight, bias, eps):
ctx.eps = eps
N, C, H, W = x.shape[0],x.shape[1],x.shape[2],x.shape[3]
mu = x.mean(1, keepdim=True)
var = (x - mu).pow(2).mean(1, keepdim=True)
y = (x - mu) / (var + eps).sqrt()
ctx.save_for_backward(y, var, weight)
y = weight.reshape([1, C, 1, 1]) * y + bias.reshape([1, C, 1, 1])
return y
@staticmethod
def backward(ctx, grad_output):
eps = ctx.eps
N, C, H, W = grad_output.shape[0],grad_output.shape[1],grad_output.shape[2],grad_output.shape[3]
# y, var, weight = ctx.saved_variables
y, var, weight = ctx.saved_tensor()
g = grad_output * weight.reshape([1, C, 1, 1])
mean_g = g.mean(axis=1, keepdim=True)
mean_gy = (g * y).mean(axis=1, keepdim=True)
gx = 1. / P.sqrt(var + eps) * (g - y * mean_gy - mean_g)
return gx, (grad_output * y).sum(axis=3).sum(axis=2).sum(axis=0), grad_output.sum(axis=3).sum(axis=2).sum(
axis=0)In [38]
class LayerNorm2d(nn.Layer):
def __init__(self, channels, eps=1e-6):
super(LayerNorm2d, self).__init__()
weight = P.static.create_parameter([channels], dtype='float32')
bias = P.static.create_parameter([channels], dtype='float32')
self.add_parameter('weight',weight)
self.add_parameter('bias',bias)
self.eps = eps
def forward(self, x):
return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)
mylayer = LayerNorm2d(2)
for name, param in mylayer.named_parameters():
print(name, param) # will print w_tmp,_linear.weight,_linear.biasweight Parameter containing:
Tensor(shape=[2], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[-0.00963153, 0.00699809])
bias Parameter containing:
Tensor(shape=[2], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[-0.02439881, 0.00256911])
In [39]
from paddle.nn import Layer
from paddle import nn
import math
# 是可以保持w,h不变的
class ConvolutionalBlock2(nn.Layer):
"""
卷积模块,由卷积层, BN归一化层, 激活层构成.
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, batch_norm=False, activation=None):
"""
:参数 in_channels: 输入通道数
:参数 out_channels: 输出通道数
:参数 kernel_size: 核大小
:参数 stride: 步长
:参数 batch_norm: 是否包含BN层
:参数 activation: 激活层类型; 如果没有则为None
"""
super(ConvolutionalBlock2, self).__init__()
if activation is not None:
activation = activation.lower()
assert activation in {'prelu', 'leakyrelu', 'tanh'}
# 层列表
layers = list()
# 1个卷积层
layers.append(
nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2))
# 1个BN归一化层
if batch_norm is True:
# layers.append(nn.BatchNorm2D(num_features=out_channels))
layers.append(LayerNorm2d(out_channels)) # 添加了一个layernorm层 'psnr': 35.01214982299412, 'ssim': 0.9695686973520531
# 1个激活层
if activation == 'prelu':
layers.append(nn.PReLU())
elif activation == 'leakyrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'tanh':
layers.append(nn.Tanh())
# 合并层
self.conv_block = nn.Sequential(*layers)
def forward(self, input):
output = self.conv_block(input)
return output
# w,h放大
class SubPixelConvolutionalBlock2(nn.Layer):
def __init__(self, kernel_size=3, n_channels=64, scaling_factor=2):
super(SubPixelConvolutionalBlock2, self).__init__()
# 首先通过卷积将通道数扩展为 scaling factor^2 倍
self.conv = nn.Conv2D(in_channels=n_channels, out_channels=n_channels * (scaling_factor ** 2),
kernel_size=kernel_size, padding=kernel_size // 2)
# 进行像素清洗,合并相关通道数据 放大了图像
self.pixel_shuffle = nn.PixelShuffle(upscale_factor=scaling_factor)
# 最后添加激活层
self.prelu = nn.PReLU()
def forward(self, input):
output = self.conv(input)
output = self.pixel_shuffle(output)
output = self.prelu(output)
return output
class ResidualBlock2(nn.Layer):
"""
残差模块, 包含两个卷积模块和一个跳连.
"""
def __init__(self, kernel_size=3, n_channels=64):
"""
:参数 kernel_size: 核大小
:参数 n_channels: 输入和输出通道数(由于是ResNet网络,需要做跳连,因此输入和输出通道数是一致的)
"""
super(ResidualBlock2, self).__init__()
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock2(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation='PReLu')
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock2(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation='PReLu')
def forward(self, input):
"""
前向传播.
:参数 input: 输入图像集,张量表示,大小为 (N, n_channels, w, h)
:返回: 输出图像集,张量表示,大小为 (N, n_channels, w, h)
"""
residual = input # (N, n_channels, w, h)
output = self.conv_block1(input) # (N, n_channels, w, h)
output = output + residual
output = self.conv_block2(output) # (N, n_channels, w, h)
output = output + residual # (N, n_channels, w, h)
return output
class SimpleGate(nn.Layer):
def __init__(self):
super(SimpleGate, self).__init__()
def forward(self, x):
x1, x2 = x.chunk(2, axis=1)
# 在通道上拆分x为两个数据块
return x1 , x2
class SRResNet2(nn.Layer):
# SRResNet(scaling_factor=2)
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=2):
"""
:参数 large_kernel_size: 第一层卷积和最后一层卷积核大小
:参数 small_kernel_size: 中间层卷积核大小
:参数 n_channels: 中间层通道数
:参数 n_blocks: 残差模块数
:参数 scaling_factor: 放大比例
"""
super(SRResNet2, self).__init__()
# 放大比例必须为 2、 4 或 8
scaling_factor = int(scaling_factor)
assert scaling_factor in {2, 4, 8}, "放大比例必须为 2、 4 或 8!"
self.sca = simam_module(n_channels // 2)
# SimpleGate
self.sg = SimpleGate()
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock2(in_channels=1, out_channels=n_channels, kernel_size=large_kernel_size,
batch_norm=False, activation='PReLu')
# 一系列残差模块, 每个残差模块包含一个跳连接
self.residual_blocks = nn.Sequential(
*[ResidualBlock2(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)])
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock2(in_channels=n_channels, out_channels=n_channels,
kernel_size=small_kernel_size,
batch_norm=True, activation=None)
# 放大通过子像素卷积模块实现, 每个模块放大两倍 log2 2=1
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(
*[SubPixelConvolutionalBlock2(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i
in range(n_subpixel_convolution_blocks)])
# 最后一个卷积模块
self.conv_block3 = ConvolutionalBlock2(in_channels=n_channels, out_channels=1, kernel_size=large_kernel_size,
batch_norm=False, activation='Tanh')
self.beta = P.create_parameter(shape=[1, n_channels, 1, 1], dtype='float32') # 加了这个 'psnr': 35.24633049966084, 'ssim': 0.9703385639920482
def forward(self, lr_imgs):
"""
:参数 lr_imgs: 低分辨率输入图像集, 张量表示,大小为 (N, 3, w, h)
:返回: 高分辨率输出图像集, 张量表示, 大小为 (N, 3, w * scaling factor, h * scaling factor)
"""
output = self.conv_block1(lr_imgs) # (16, 3, 24, 24)
residual = output # (16, 64, 24, 24)
output = self.residual_blocks(output) # (16, 64, 24, 24)
# 从这
x1 , x2 = self.sg(output)
x1 = self.sca(x1)
x2 = self.sca(x2)
output = paddle.concat((x1,x2),axis=1)
# 到这加了这个chunk 'psnr': 35.135550619006025, 'ssim': 0.9703396077881369
output = self.conv_block2(output) # (16, 64, 24, 24)
output = output + residual * self.beta # (16, 64, 24, 24)
output = self.subpixel_convolutional_blocks(output) # (16, 64, 24 * 2, 24 * 2)
sr_imgs = self.conv_block3(output) # (16, 3, 24 * 2, 24 * 2)
return sr_imgs
if __name__ == '__main__':
img_channel = 1
width = 64
net = SRResNet2()
inp = P.randn((1, 1, 120, 120),dtype='float32')
out = net(inp)
print('inp',inp.shape)
print('out',out.shape)inp [1, 1, 120, 120] out [1, 1, 240, 240]
11、模型训练
In [40]
train_dataset= MyDataset(mode='train')
valid_dataset= MyDataset(mode='valid')
test_dataset = MyDataset(mode='test')In [53]
model1 = paddle.Model(Sub_Pixel_CNN(upscale_factor=SCALE, channels=1))
model2 = paddle.Model(VRCNN())
model3 = paddle.Model(EDSR())
model4 = paddle.Model(SRResNet(scaling_factor=SCALE))
model5 = paddle.Model(SRResNet2(scaling_factor=SCALE))In [43]
Model_name = 'Sub_Pixel_CNN'
model = model1In [44]
#一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
%set_env FLAGS_eager_delete_tensor_gb=0.0
#启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
#该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
paddle.device.cuda.empty_cache()env: FLAGS_eager_delete_tensor_gb=0.0
In [45]
# https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/super_resolution_sub_pixel.html#sub-pixel
# L1_Charbonnier_loss
# 设置学习率
base_lr = 0.001
# lr = paddle.optimizer.lr.PolynomialDecay(base_lr, power=0.9, end_lr=0.0001,decay_steps=2000)
# lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=10000*5, verbose=False)
# optimizer = paddle.optimizer.Momentum(lr, parameters=model.parameters(), momentum=0.9, weight_decay=4.0e-5)
optimizer = paddle.optimizer.Adam(learning_rate=base_lr,parameters=model.parameters())
model.prepare(optimizer,
MY_loss(),
# L1_Charbonnier_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=EPOCH,
batch_size=64,
verbose=1,
callbacks=ModelCheckpoint(save_dir= Model_name+'_checkpoint'))
The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20 step 750/750 [==============================] - loss: 0.0188 - psnr: 33.3326 - ssim: 0.9398 - mse: 0.0020 - rmse: 0.0365 - nrmse: 3.0707 - 85ms/step Eval begin... step 576/576 [==============================] - loss: 0.0147 - psnr: 31.9830 - ssim: 0.9645 - mse: 7.3423e-04 - rmse: 0.0261 - nrmse: 0.0812 - 14ms/step Eval samples: 576 save checkpoint at /home/aistudio/Sub_Pixel_CNN_checkpoint/31.98302470744666_0.9644605700936759 Epoch 2/20 step 750/750 [==============================] - loss: 0.0226 - psnr: 36.3452 - ssim: 0.9795 - mse: 5.6515e-04 - rmse: 0.0237 - nrmse: 0.1389 - 82ms/step Eval begin... step 576/576 [==============================] - loss: 0.0218 - psnr: 31.6043 - ssim: 0.9624 - mse: 8.5735e-04 - rmse: 0.0277 - nrmse: 0.0821 - 14ms/step Eval samples: 576 Epoch 3/20 step 750/750 [==============================] - loss: 0.0208 - psnr: 36.5555 - ssim: 0.9799 - mse: 5.6817e-04 - rmse: 0.0237 - nrmse: 0.1330 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0206 - psnr: 31.8005 - ssim: 0.9645 - mse: 8.1238e-04 - rmse: 0.0270 - nrmse: 0.0806 - 14ms/step Eval samples: 576 Epoch 4/20 step 750/750 [==============================] - loss: 0.0206 - psnr: 36.5303 - ssim: 0.9757 - mse: 5.5912e-04 - rmse: 0.0235 - nrmse: 0.1345 - 84ms/step Eval begin... step 576/576 [==============================] - loss: 0.0143 - psnr: 31.7892 - ssim: 0.9513 - mse: 7.6651e-04 - rmse: 0.0267 - nrmse: 0.0839 - 14ms/step Eval samples: 576 Epoch 5/20 step 750/750 [==============================] - loss: 0.0212 - psnr: 36.7040 - ssim: 0.9761 - mse: 5.2895e-04 - rmse: 0.0229 - nrmse: 0.1345 - 81ms/step Eval begin... step 576/576 [==============================] - loss: 0.0173 - psnr: 32.0721 - ssim: 0.9627 - mse: 7.3212e-04 - rmse: 0.0259 - nrmse: 0.0791 - 14ms/step Eval samples: 576 Epoch 6/20 step 750/750 [==============================] - loss: 0.0204 - psnr: 36.8262 - ssim: 0.9789 - mse: 5.2370e-04 - rmse: 0.0228 - nrmse: 0.1307 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0187 - psnr: 31.9986 - ssim: 0.9637 - mse: 7.5658e-04 - rmse: 0.0263 - nrmse: 0.0793 - 14ms/step Eval samples: 576 Epoch 7/20 step 750/750 [==============================] - loss: 0.0198 - psnr: 36.8252 - ssim: 0.9792 - mse: 5.3055e-04 - rmse: 0.0229 - nrmse: 0.1290 - 82ms/step Eval begin... step 576/576 [==============================] - loss: 0.0139 - psnr: 31.8495 - ssim: 0.9636 - mse: 7.5649e-04 - rmse: 0.0265 - nrmse: 0.0832 - 14ms/step Eval samples: 576 Epoch 8/20 step 750/750 [==============================] - loss: 0.0220 - psnr: 36.8289 - ssim: 0.9784 - mse: 5.2432e-04 - rmse: 0.0228 - nrmse: 0.1298 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0136 - psnr: 31.0587 - ssim: 0.9589 - mse: 9.0438e-04 - rmse: 0.0290 - nrmse: 0.0927 - 14ms/step Eval samples: 576 Epoch 9/20 step 750/750 [==============================] - loss: 0.0207 - psnr: 36.8369 - ssim: 0.9789 - mse: 5.1670e-04 - rmse: 0.0227 - nrmse: 0.1292 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0134 - psnr: 31.7333 - ssim: 0.9627 - mse: 7.7820e-04 - rmse: 0.0269 - nrmse: 0.0848 - 14ms/step Eval samples: 576 Epoch 10/20 step 750/750 [==============================] - loss: 0.0216 - psnr: 36.7846 - ssim: 0.9789 - mse: 5.2375e-04 - rmse: 0.0228 - nrmse: 0.1284 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0173 - psnr: 32.0790 - ssim: 0.9627 - mse: 7.3081e-04 - rmse: 0.0259 - nrmse: 0.0791 - 14ms/step Eval samples: 576 Epoch 11/20 step 750/750 [==============================] - loss: 0.0173 - psnr: 36.8307 - ssim: 0.9789 - mse: 5.1593e-04 - rmse: 0.0226 - nrmse: 0.1285 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0165 - psnr: 32.0493 - ssim: 0.9611 - mse: 7.2736e-04 - rmse: 0.0260 - nrmse: 0.0798 - 14ms/step Eval samples: 576 Epoch 12/20 step 750/750 [==============================] - loss: 0.0247 - psnr: 36.9022 - ssim: 0.9792 - mse: 5.1575e-04 - rmse: 0.0226 - nrmse: 0.1288 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0145 - psnr: 31.9848 - ssim: 0.9633 - mse: 7.3438e-04 - rmse: 0.0261 - nrmse: 0.0813 - 15ms/step Eval samples: 576 Epoch 13/20 step 750/750 [==============================] - loss: 0.0209 - psnr: 36.9147 - ssim: 0.9791 - mse: 5.1594e-04 - rmse: 0.0226 - nrmse: 0.1293 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0160 - psnr: 32.0895 - ssim: 0.9639 - mse: 7.2153e-04 - rmse: 0.0258 - nrmse: 0.0796 - 14ms/step Eval samples: 576 Epoch 14/20 step 750/750 [==============================] - loss: 0.0220 - psnr: 36.8636 - ssim: 0.9793 - mse: 5.2195e-04 - rmse: 0.0228 - nrmse: 0.1284 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0178 - psnr: 32.0554 - ssim: 0.9638 - mse: 7.3901e-04 - rmse: 0.0260 - nrmse: 0.0791 - 15ms/step Eval samples: 576 Epoch 15/20 step 750/750 [==============================] - loss: 0.0207 - psnr: 36.9344 - ssim: 0.9795 - mse: 5.1049e-04 - rmse: 0.0225 - nrmse: 0.1277 - 85ms/step Eval begin... step 576/576 [==============================] - loss: 0.0138 - psnr: 31.8787 - ssim: 0.9624 - mse: 7.5277e-04 - rmse: 0.0265 - nrmse: 0.0829 - 15ms/step Eval samples: 576 Epoch 16/20 step 750/750 [==============================] - loss: 0.0194 - psnr: 36.9171 - ssim: 0.9793 - mse: 5.1491e-04 - rmse: 0.0226 - nrmse: 0.1280 - 85ms/step Eval begin... step 576/576 [==============================] - loss: 0.0149 - psnr: 32.0211 - ssim: 0.9640 - mse: 7.2881e-04 - rmse: 0.0260 - nrmse: 0.0808 - 15ms/step Eval samples: 576 Epoch 17/20 step 750/750 [==============================] - loss: 0.0226 - psnr: 36.8960 - ssim: 0.9788 - mse: 5.1591e-04 - rmse: 0.0226 - nrmse: 0.1294 - 85ms/step Eval begin... step 576/576 [==============================] - loss: 0.0190 - psnr: 31.9806 - ssim: 0.9621 - mse: 7.6248e-04 - rmse: 0.0263 - nrmse: 0.0794 - 15ms/step Eval samples: 576 Epoch 18/20 step 750/750 [==============================] - loss: 0.0187 - psnr: 36.9103 - ssim: 0.9793 - mse: 5.1296e-04 - rmse: 0.0226 - nrmse: 0.1272 - 85ms/step Eval begin... step 576/576 [==============================] - loss: 0.0186 - psnr: 32.0169 - ssim: 0.9636 - mse: 7.5189e-04 - rmse: 0.0262 - nrmse: 0.0792 - 14ms/step Eval samples: 576 Epoch 19/20 step 750/750 [==============================] - loss: 0.0183 - psnr: 37.0129 - ssim: 0.9794 - mse: 5.0388e-04 - rmse: 0.0224 - nrmse: 0.1282 - 84ms/step Eval begin... step 576/576 [==============================] - loss: 0.0142 - psnr: 31.8895 - ssim: 0.9607 - mse: 7.4967e-04 - rmse: 0.0264 - nrmse: 0.0826 - 14ms/step Eval samples: 576 Epoch 20/20 step 750/750 [==============================] - loss: 0.0203 - psnr: 36.9324 - ssim: 0.9794 - mse: 5.1734e-04 - rmse: 0.0227 - nrmse: 0.1280 - 83ms/step Eval begin... step 576/576 [==============================] - loss: 0.0168 - psnr: 32.1048 - ssim: 0.9643 - mse: 7.2450e-04 - rmse: 0.0258 - nrmse: 0.0790 - 14ms/step Eval samples: 576
In [54]
Model_name = 'VRCNN'
model = model2In [51]
#一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
!export FLAGS_eager_delete_tensor_gb=0.0
#启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
#该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
paddle.device.cuda.empty_cache()In [55]
# https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/super_resolution_sub_pixel.html#sub-pixel
# L1_Charbonnier_loss
model.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=EPOCH,
batch_size=64,
verbose=1,
callbacks=ModelCheckpoint(save_dir= Model_name+'_checkpoint'))
# inf 为 psnr 的上限,如果训练psnr出现inf,可能为过拟合
The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20 step 750/750 [==============================] - loss: 0.0171 - psnr: 37.4820 - ssim: 0.9806 - mse: 4.4347e-04 - rmse: 0.0209 - nrmse: inf - 91ms/step Eval begin... step 576/576 [==============================] - loss: 0.0162 - psnr: 32.4433 - ssim: 0.9547 - mse: 6.6323e-04 - rmse: 0.0248 - nrmse: 0.0773 - 16ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/32.44333199593464_0.9547390267609792 Epoch 2/20 step 750/750 [==============================] - loss: 0.0182 - psnr: 38.0040 - ssim: 0.9834 - mse: 3.9225e-04 - rmse: 0.0197 - nrmse: inf - 91ms/step Eval begin... step 576/576 [==============================] - loss: 0.0171 - psnr: 32.8099 - ssim: 0.9676 - mse: 6.2511e-04 - rmse: 0.0239 - nrmse: 0.0733 - 16ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/32.80992837231833_0.9676008685060784 Epoch 3/20 step 750/750 [==============================] - loss: 0.0144 - psnr: 38.2530 - ssim: 0.9842 - mse: 3.8080e-04 - rmse: 0.0194 - nrmse: inf - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0189 - psnr: 32.8775 - ssim: 0.9701 - mse: 6.3590e-04 - rmse: 0.0239 - nrmse: 0.0723 - 16ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/32.877518145528384_0.9701320131316061 Epoch 4/20 step 320/750 [===========>..................] - loss: 0.0130 - psnr: 38.2272 - ssim: 0.9845 - mse: 3.8439e-04 - rmse: 0.0195 - nrmse: inf - ETA: 39s - 93ms/step
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/skimage/metrics/simple_metrics.py:163: RuntimeWarning: divide by zero encountered in double_scalars return 10 * np.log10((data_range ** 2) / err) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/skimage/metrics/simple_metrics.py:108: RuntimeWarning: invalid value encountered in double_scalars return np.sqrt(mean_squared_error(image_true, image_test)) / denom
step 750/750 [==============================] - loss: 0.0187 - psnr: inf - ssim: 0.9845 - mse: 3.8136e-04 - rmse: 0.0195 - nrmse: nan - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0165 - psnr: 32.9356 - ssim: 0.9684 - mse: 6.0768e-04 - rmse: 0.0235 - nrmse: 0.0725 - 16ms/step Eval samples: 576 Epoch 5/20 step 750/750 [==============================] - loss: 0.0178 - psnr: inf - ssim: 0.9846 - mse: 3.7523e-04 - rmse: 0.0193 - nrmse: nan - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0164 - psnr: 32.9239 - ssim: 0.9610 - mse: 6.0525e-04 - rmse: 0.0235 - nrmse: 0.0728 - 17ms/step Eval samples: 576 Epoch 6/20 step 750/750 [==============================] - loss: 0.0152 - psnr: inf - ssim: 0.9847 - mse: 3.7455e-04 - rmse: 0.0193 - nrmse: nan - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0187 - psnr: 32.9502 - ssim: 0.9702 - mse: 6.2729e-04 - rmse: 0.0237 - nrmse: 0.0718 - 17ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/32.95022570538785_0.9701510339019462 Epoch 7/20 step 750/750 [==============================] - loss: 0.0133 - psnr: 38.3661 - ssim: 0.9849 - mse: 3.7249e-04 - rmse: 0.0192 - nrmse: inf - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0165 - psnr: 32.9293 - ssim: 0.9693 - mse: 6.0722e-04 - rmse: 0.0235 - nrmse: 0.0726 - 16ms/step Eval samples: 576 Epoch 8/20 step 750/750 [==============================] - loss: 0.0154 - psnr: inf - ssim: 0.9849 - mse: 3.6870e-04 - rmse: 0.0191 - nrmse: nan - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0169 - psnr: 33.0678 - ssim: 0.9720 - mse: 5.9982e-04 - rmse: 0.0233 - nrmse: 0.0713 - 17ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/33.06781992951538_0.9719527722045037 Epoch 9/20 step 750/750 [==============================] - loss: 0.0149 - psnr: inf - ssim: 0.9852 - mse: 3.7059e-04 - rmse: 0.0192 - nrmse: nan - 93ms/step Eval begin... step 576/576 [==============================] - loss: 0.0174 - psnr: 33.0383 - ssim: 0.9715 - mse: 6.0197e-04 - rmse: 0.0233 - nrmse: 0.0715 - 16ms/step Eval samples: 576 Epoch 10/20 step 750/750 [==============================] - loss: 0.0164 - psnr: inf - ssim: 0.9851 - mse: 3.6740e-04 - rmse: 0.0191 - nrmse: nan - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0188 - psnr: 33.0047 - ssim: 0.9719 - mse: 6.2588e-04 - rmse: 0.0236 - nrmse: 0.0714 - 16ms/step Eval samples: 576 Epoch 11/20 step 750/750 [==============================] - loss: 0.0153 - psnr: inf - ssim: 0.9854 - mse: 3.6741e-04 - rmse: 0.0191 - nrmse: nan - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0174 - psnr: 33.0564 - ssim: 0.9685 - mse: 6.0210e-04 - rmse: 0.0233 - nrmse: 0.0714 - 16ms/step Eval samples: 576 Epoch 12/20 step 750/750 [==============================] - loss: 0.0152 - psnr: inf - ssim: 0.9853 - mse: 3.6689e-04 - rmse: 0.0191 - nrmse: nan - 91ms/step Eval begin... step 576/576 [==============================] - loss: 0.0158 - psnr: 32.9805 - ssim: 0.9714 - mse: 5.9824e-04 - rmse: 0.0234 - nrmse: 0.0726 - 16ms/step Eval samples: 576 Epoch 13/20 step 750/750 [==============================] - loss: 0.0146 - psnr: inf - ssim: 0.9854 - mse: 3.6907e-04 - rmse: 0.0191 - nrmse: nan - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0162 - psnr: 33.0124 - ssim: 0.9711 - mse: 5.9812e-04 - rmse: 0.0233 - nrmse: 0.0721 - 16ms/step Eval samples: 576 Epoch 14/20 step 750/750 [==============================] - loss: 0.0155 - psnr: 38.4708 - ssim: 0.9855 - mse: 3.6684e-04 - rmse: 0.0191 - nrmse: inf - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0151 - psnr: 33.0312 - ssim: 0.9715 - mse: 5.9414e-04 - rmse: 0.0233 - nrmse: 0.0724 - 17ms/step Eval samples: 576 Epoch 15/20 step 750/750 [==============================] - loss: 0.0162 - psnr: 38.4990 - ssim: 0.9855 - mse: 3.6234e-04 - rmse: 0.0190 - nrmse: inf - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0165 - psnr: 33.1083 - ssim: 0.9721 - mse: 5.8937e-04 - rmse: 0.0231 - nrmse: 0.0712 - 16ms/step Eval samples: 576 save checkpoint at /home/aistudio/VRCNN_checkpoint/33.10830663734545_0.9720895701836922 Epoch 16/20 step 750/750 [==============================] - loss: 0.0151 - psnr: 38.5232 - ssim: 0.9855 - mse: 3.6299e-04 - rmse: 0.0190 - nrmse: 0.1170 - 94ms/step Eval begin... step 576/576 [==============================] - loss: 0.0179 - psnr: 33.1032 - ssim: 0.9711 - mse: 6.0184e-04 - rmse: 0.0232 - nrmse: 0.0708 - 17ms/step Eval samples: 576 Epoch 17/20 step 750/750 [==============================] - loss: 0.0141 - psnr: 38.4837 - ssim: 0.9855 - mse: 3.6383e-04 - rmse: 0.0190 - nrmse: inf - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0162 - psnr: 33.1232 - ssim: 0.9720 - mse: 5.8662e-04 - rmse: 0.0231 - nrmse: 0.0712 - 16ms/step Eval samples: 576 Epoch 18/20 step 750/750 [==============================] - loss: 0.0135 - psnr: 38.4911 - ssim: 0.9856 - mse: 3.6516e-04 - rmse: 0.0190 - nrmse: inf - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0166 - psnr: 33.1220 - ssim: 0.9718 - mse: 5.9188e-04 - rmse: 0.0231 - nrmse: 0.0710 - 16ms/step Eval samples: 576 Epoch 19/20 step 750/750 [==============================] - loss: 0.0156 - psnr: 38.5491 - ssim: 0.9857 - mse: 3.6243e-04 - rmse: 0.0190 - nrmse: inf - 93ms/step Eval begin... step 576/576 [==============================] - loss: 0.0169 - psnr: 33.0711 - ssim: 0.9707 - mse: 5.9627e-04 - rmse: 0.0232 - nrmse: 0.0713 - 16ms/step Eval samples: 576 Epoch 20/20 step 750/750 [==============================] - loss: 0.0188 - psnr: 38.5441 - ssim: 0.9856 - mse: 3.6220e-04 - rmse: 0.0190 - nrmse: inf - 92ms/step Eval begin... step 576/576 [==============================] - loss: 0.0158 - psnr: 33.0954 - ssim: 0.9718 - mse: 5.8672e-04 - rmse: 0.0231 - nrmse: 0.0715 - 16ms/step Eval samples: 576
In [56]
Model_name = 'EDSR'
model = model3In [57]
#一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
!export FLAGS_eager_delete_tensor_gb=0.0
#启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
#该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
paddle.device.cuda.empty_cache()In [58]
# https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/super_resolution_sub_pixel.html#sub-pixel
# L1_Charbonnier_loss
model.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=EPOCH,
batch_size=64,
verbose=1,
callbacks=ModelCheckpoint(save_dir= Model_name+'_checkpoint'))
The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20 step 750/750 [==============================] - loss: 0.0164 - psnr: 34.5783 - ssim: 0.9366 - mse: 0.0017 - rmse: 0.0314 - nrmse: 1.3829 - 139ms/step Eval begin... step 576/576 [==============================] - loss: 0.0136 - psnr: 32.5224 - ssim: 0.9653 - mse: 6.5820e-04 - rmse: 0.0246 - nrmse: 0.0775 - 28ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/32.522409477799705_0.9653072052545704 Epoch 2/20 step 750/750 [==============================] - loss: 0.0170 - psnr: 37.7480 - ssim: 0.9792 - mse: 4.1853e-04 - rmse: 0.0203 - nrmse: 0.1290 - 139ms/step Eval begin... step 576/576 [==============================] - loss: 0.0151 - psnr: 33.1964 - ssim: 0.9721 - mse: 5.7595e-04 - rmse: 0.0229 - nrmse: 0.0709 - 28ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.196403297747786_0.9721136249058921 Epoch 3/20 step 750/750 [==============================] - loss: 0.0120 - psnr: 38.1860 - ssim: 0.9817 - mse: 3.8562e-04 - rmse: 0.0195 - nrmse: 0.1210 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0177 - psnr: 33.4040 - ssim: 0.9715 - mse: 5.7129e-04 - rmse: 0.0225 - nrmse: 0.0686 - 29ms/step Eval samples: 576 Epoch 4/20 step 750/750 [==============================] - loss: 0.0121 - psnr: 38.4394 - ssim: 0.9835 - mse: 3.6319e-04 - rmse: 0.0190 - nrmse: 0.1160 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0198 - psnr: 33.3007 - ssim: 0.9684 - mse: 6.1046e-04 - rmse: 0.0230 - nrmse: 0.0692 - 28ms/step Eval samples: 576 Epoch 5/20 step 750/750 [==============================] - loss: 0.0152 - psnr: 38.4744 - ssim: 0.9823 - mse: 3.5832e-04 - rmse: 0.0188 - nrmse: 0.1176 - 140ms/step Eval begin... step 576/576 [==============================] - loss: 0.0176 - psnr: 33.5061 - ssim: 0.9726 - mse: 5.5933e-04 - rmse: 0.0223 - nrmse: 0.0679 - 29ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.50607907786202_0.9726489751718138 Epoch 6/20 step 750/750 [==============================] - loss: 0.0154 - psnr: 38.5837 - ssim: 0.9827 - mse: 3.5398e-04 - rmse: 0.0187 - nrmse: 0.1158 - 140ms/step Eval begin... step 576/576 [==============================] - loss: 0.0182 - psnr: 33.5877 - ssim: 0.9694 - mse: 5.5765e-04 - rmse: 0.0221 - nrmse: 0.0673 - 28ms/step Eval samples: 576 Epoch 7/20 step 750/750 [==============================] - loss: 0.0156 - psnr: 38.7371 - ssim: 0.9834 - mse: 3.4210e-04 - rmse: 0.0184 - nrmse: 0.1136 - 140ms/step Eval begin... step 576/576 [==============================] - loss: 0.0211 - psnr: 33.1981 - ssim: 0.9627 - mse: 6.4131e-04 - rmse: 0.0234 - nrmse: 0.0700 - 29ms/step Eval samples: 576 Epoch 8/20 step 750/750 [==============================] - loss: 0.0154 - psnr: 38.8637 - ssim: 0.9845 - mse: 3.3725e-04 - rmse: 0.0183 - nrmse: 0.1122 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0174 - psnr: 33.6874 - ssim: 0.9733 - mse: 5.4544e-04 - rmse: 0.0219 - nrmse: 0.0668 - 29ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.687398153156074_0.9732660241394796 Epoch 9/20 step 750/750 [==============================] - loss: 0.0139 - psnr: 38.8114 - ssim: 0.9836 - mse: 3.3596e-04 - rmse: 0.0182 - nrmse: 0.1125 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0173 - psnr: 33.6940 - ssim: 0.9739 - mse: 5.4286e-04 - rmse: 0.0219 - nrmse: 0.0667 - 29ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.69395759094175_0.9738559643317893 Epoch 10/20 step 750/750 [==============================] - loss: 0.0159 - psnr: 38.8792 - ssim: 0.9845 - mse: 3.3178e-04 - rmse: 0.0181 - nrmse: 0.1101 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0152 - psnr: 33.7661 - ssim: 0.9752 - mse: 5.2357e-04 - rmse: 0.0216 - nrmse: 0.0668 - 28ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.766133769980684_0.9751510737579723 Epoch 11/20 step 750/750 [==============================] - loss: 0.0153 - psnr: 39.0017 - ssim: 0.9847 - mse: 3.3135e-04 - rmse: 0.0181 - nrmse: 0.1119 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0168 - psnr: 33.8127 - ssim: 0.9722 - mse: 5.3055e-04 - rmse: 0.0216 - nrmse: 0.0660 - 29ms/step Eval samples: 576 Epoch 12/20 step 750/750 [==============================] - loss: 0.0152 - psnr: 38.9846 - ssim: 0.9854 - mse: 3.2896e-04 - rmse: 0.0181 - nrmse: 0.1095 - 139ms/step Eval begin... step 576/576 [==============================] - loss: 0.0140 - psnr: 33.5944 - ssim: 0.9736 - mse: 5.3707e-04 - rmse: 0.0220 - nrmse: 0.0687 - 28ms/step Eval samples: 576 Epoch 13/20 step 750/750 [==============================] - loss: 0.0138 - psnr: 39.1354 - ssim: 0.9861 - mse: 3.2079e-04 - rmse: 0.0178 - nrmse: 0.1078 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0148 - psnr: 33.8552 - ssim: 0.9753 - mse: 5.1310e-04 - rmse: 0.0214 - nrmse: 0.0662 - 30ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.85520735559357_0.9752507509073234 Epoch 14/20 step 750/750 [==============================] - loss: 0.0133 - psnr: 39.1098 - ssim: 0.9863 - mse: 3.2090e-04 - rmse: 0.0178 - nrmse: 0.1068 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0150 - psnr: 33.8014 - ssim: 0.9705 - mse: 5.1891e-04 - rmse: 0.0215 - nrmse: 0.0667 - 29ms/step Eval samples: 576 Epoch 15/20 step 750/750 [==============================] - loss: 0.0130 - psnr: 39.1755 - ssim: 0.9863 - mse: 3.1540e-04 - rmse: 0.0177 - nrmse: 0.1070 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0158 - psnr: 33.8825 - ssim: 0.9762 - mse: 5.1805e-04 - rmse: 0.0214 - nrmse: 0.0659 - 30ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.88246823019576_0.9761552895152756 Epoch 16/20 step 750/750 [==============================] - loss: 0.0132 - psnr: 39.2000 - ssim: 0.9866 - mse: 3.1462e-04 - rmse: 0.0177 - nrmse: 0.1071 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0134 - psnr: 33.5892 - ssim: 0.9762 - mse: 5.4335e-04 - rmse: 0.0221 - nrmse: 0.0693 - 30ms/step Eval samples: 576 Epoch 17/20 step 750/750 [==============================] - loss: 0.0129 - psnr: 39.1715 - ssim: 0.9862 - mse: 3.1530e-04 - rmse: 0.0177 - nrmse: 0.1069 - 142ms/step Eval begin... step 576/576 [==============================] - loss: 0.0160 - psnr: 33.9239 - ssim: 0.9766 - mse: 5.1330e-04 - rmse: 0.0213 - nrmse: 0.0655 - 29ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.92393781328648_0.9765998669978802 Epoch 18/20 step 750/750 [==============================] - loss: 0.0139 - psnr: 39.2427 - ssim: 0.9866 - mse: 3.1327e-04 - rmse: 0.0176 - nrmse: 0.1060 - 141ms/step Eval begin... step 576/576 [==============================] - loss: 0.0167 - psnr: 33.9297 - ssim: 0.9768 - mse: 5.2138e-04 - rmse: 0.0214 - nrmse: 0.0653 - 29ms/step Eval samples: 576 save checkpoint at /home/aistudio/EDSR_checkpoint/33.929684575294715_0.9767564802913058 Epoch 19/20 step 750/750 [==============================] - loss: 0.0125 - psnr: 39.3000 - ssim: 0.9867 - mse: 3.1070e-04 - rmse: 0.0175 - nrmse: 0.1060 - 140ms/step Eval begin... step 576/576 [==============================] - loss: 0.0151 - psnr: 33.9346 - ssim: 0.9766 - mse: 5.1040e-04 - rmse: 0.0213 - nrmse: 0.0657 - 28ms/step Eval samples: 576 Epoch 20/20 step 750/750 [==============================] - loss: 0.0141 - psnr: 39.2491 - ssim: 0.9867 - mse: 3.1367e-04 - rmse: 0.0176 - nrmse: 0.1067 - 138ms/step Eval begin... step 576/576 [==============================] - loss: 0.0152 - psnr: 33.9263 - ssim: 0.9769 - mse: 5.1304e-04 - rmse: 0.0213 - nrmse: 0.0658 - 29ms/step Eval samples: 576
In [ ]
# # 无框架测试代码(无需关注测试用)
# from tqdm import tqdm_notebook
# train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# model = Sub_Pixel_CNN(upscale_factor=SCALE, channels=1)
# metric1,metric2 = PSNR(),SSIM()
# model.train()
# # 设置迭代次数
# epochs = 5
# # 设置优化器
# # scheduler = paddle.optimizer.lr.StepDecay(learning_rate=0.01, step_size=2, gamma=0.8, verbose=True)
# # optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
# optim = paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters())
# # 设置损失函数
# loss_fn = MY_loss()
# for epoch in range(epochs):
# psnr_list = []
# ssim_list = []
# for data in tqdm_notebook(train_loader()):
# x_data = data[0] # 训练数据
# y_data = data[1] # 训练数据标签
# predicts = model(x_data) # 预测结果
# psnr = metric1.update(predicts,y_data)
# ssim = metric2.update(predicts,y_data)
# psnr_list.append(psnr)
# ssim_list.append(ssim)
# # 计算损失 等价于 prepare 中loss的设置
# loss = loss_fn(predicts, y_data)
# # print("epoch: {}, loss is: {},PSNR is: {},SSIM is: {}".format(epoch, loss.numpy(),psnr,ssim))
# loss.backward()
# # 更新参数
# optim.step()
# # 梯度清零
# optim.clear_grad()
# print("epoch: {}, loss is: {},PSNR is: {},SSIM is: {}".format(epoch, loss.numpy(),np.array(psnr_list).mean(),np.array(ssim_list).mean()))
# scheduler.step()In [59]
Model_name = 'SRResNet'
model = model4In [60]
#一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
!export FLAGS_eager_delete_tensor_gb=0.0
#启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
#该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
paddle.device.cuda.empty_cache()In [ ]
# https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/super_resolution_sub_pixel.html#sub-pixel
# L1_Charbonnier_loss
model.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=EPOCH,
batch_size=64,
verbose=1,
callbacks=ModelCheckpoint(save_dir= Model_name+'_checkpoint'))
# 改成了密集快The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 120/750 [===>..........................] - loss: 0.0352 - psnr: 29.7729 - ssim: 0.8637 - mse: 0.0046 - rmse: 0.0552 - nrmse: 1.6184 - ETA: 1:19 - 126ms/step
In [86]
Model_name = 'SRResNet2'
model = model5In [87]
#一旦不再使用即释放内存垃圾,=1.0 垃圾占用内存大小达到10G时,释放内存垃圾
!export FLAGS_eager_delete_tensor_gb=0.0
#启用快速垃圾回收策略,不等待cuda kernel 结束,直接释放显存
!export FLAGS_fast_eager_deletion_mode=1
#该环境变量设置只占用0%的显存
!export FLAGS_fraction_of_gpu_memory_to_use=0
paddle.device.cuda.empty_cache()In [88]
# https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/super_resolution_sub_pixel.html#sub-pixel
# L1_Charbonnier_loss
model.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=EPOCH,
batch_size=64,
verbose=1,
callbacks=ModelCheckpoint(save_dir= Model_name+'_checkpoint'))
The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20 step 750/750 [==============================] - loss: 0.0116 - psnr: 39.2050 - ssim: 0.9876 - mse: 3.2088e-04 - rmse: 0.0178 - nrmse: 0.1045 - 253ms/step Eval begin... step 576/576 [==============================] - loss: 0.0170 - psnr: 33.8683 - ssim: 0.9766 - mse: 5.2619e-04 - rmse: 0.0215 - nrmse: 0.0656 - 78ms/step Eval samples: 576 save checkpoint at /home/aistudio/SRResNet2_checkpoint/33.868267961809195_0.9765500718201865 Epoch 2/20 step 750/750 [==============================] - loss: 0.0137 - psnr: 39.2000 - ssim: 0.9877 - mse: 3.1910e-04 - rmse: 0.0178 - nrmse: 0.1045 - 253ms/step Eval begin... step 576/576 [==============================] - loss: 0.0166 - psnr: 33.8632 - ssim: 0.9762 - mse: 5.2507e-04 - rmse: 0.0215 - nrmse: 0.0657 - 78ms/step Eval samples: 576 Epoch 3/20 step 750/750 [==============================] - loss: 0.0135 - psnr: 39.2364 - ssim: 0.9878 - mse: 3.1373e-04 - rmse: 0.0176 - nrmse: 0.1040 - 250ms/step Eval begin... step 576/576 [==============================] - loss: 0.0168 - psnr: 33.8945 - ssim: 0.9766 - mse: 5.1633e-04 - rmse: 0.0214 - nrmse: 0.0654 - 78ms/step Eval samples: 576 save checkpoint at /home/aistudio/SRResNet2_checkpoint/33.89448275822083_0.9766011765187849 Epoch 4/20 step 750/750 [==============================] - loss: 0.0136 - psnr: 39.1801 - ssim: 0.9877 - mse: 3.1825e-04 - rmse: 0.0178 - nrmse: 0.1037 - 249ms/step Eval begin... step 576/576 [==============================] - loss: 0.0148 - psnr: 33.7748 - ssim: 0.9768 - mse: 5.1942e-04 - rmse: 0.0216 - nrmse: 0.0670 - 79ms/step Eval samples: 576 Epoch 5/20 step 750/750 [==============================] - loss: 0.0119 - psnr: 39.2281 - ssim: 0.9878 - mse: 3.1613e-04 - rmse: 0.0177 - nrmse: 0.1037 - 252ms/step Eval begin... step 576/576 [==============================] - loss: 0.0159 - psnr: 33.9132 - ssim: 0.9768 - mse: 5.1460e-04 - rmse: 0.0213 - nrmse: 0.0654 - 79ms/step Eval samples: 576 save checkpoint at /home/aistudio/SRResNet2_checkpoint/33.913236316713224_0.9767686876188293 Epoch 6/20 step 750/750 [==============================] - loss: 0.0112 - psnr: 39.2594 - ssim: 0.9880 - mse: 3.1434e-04 - rmse: 0.0176 - nrmse: 0.1032 - 257ms/step Eval begin... step 576/576 [==============================] - loss: 0.0193 - psnr: 33.7560 - ssim: 0.9768 - mse: 5.6176e-04 - rmse: 0.0220 - nrmse: 0.0662 - 79ms/step Eval samples: 576 Epoch 7/20 step 750/750 [==============================] - loss: 0.0132 - psnr: 39.3006 - ssim: 0.9880 - mse: 3.1219e-04 - rmse: 0.0176 - nrmse: 0.1031 - 251ms/step Eval begin... step 576/576 [==============================] - loss: 0.0210 - psnr: 33.5138 - ssim: 0.9758 - mse: 5.9451e-04 - rmse: 0.0226 - nrmse: 0.0678 - 80ms/step Eval samples: 576 Epoch 8/20 step 750/750 [==============================] - loss: 0.0132 - psnr: 39.3411 - ssim: 0.9880 - mse: 3.1152e-04 - rmse: 0.0176 - nrmse: 0.1032 - 251ms/step Eval begin... step 576/576 [==============================] - loss: 0.0213 - psnr: 33.2307 - ssim: 0.9759 - mse: 6.4850e-04 - rmse: 0.0235 - nrmse: 0.0698 - 79ms/step Eval samples: 576 Epoch 9/20 step 750/750 [==============================] - loss: 0.0119 - psnr: 39.3361 - ssim: 0.9880 - mse: 3.1045e-04 - rmse: 0.0175 - nrmse: 0.1033 - 258ms/step Eval begin... step 576/576 [==============================] - loss: 0.0138 - psnr: 33.5155 - ssim: 0.9762 - mse: 5.4820e-04 - rmse: 0.0222 - nrmse: 0.0698 - 79ms/step Eval samples: 576 Epoch 10/20 step 750/750 [==============================] - loss: 0.0139 - psnr: 39.3417 - ssim: 0.9882 - mse: 3.0696e-04 - rmse: 0.0174 - nrmse: 0.1023 - 252ms/step Eval begin... step 576/576 [==============================] - loss: 0.0133 - psnr: 33.7013 - ssim: 0.9763 - mse: 5.2643e-04 - rmse: 0.0217 - nrmse: 0.0679 - 79ms/step Eval samples: 576 Epoch 11/20 step 750/750 [==============================] - loss: 0.0145 - psnr: 39.3512 - ssim: 0.9882 - mse: 3.0634e-04 - rmse: 0.0174 - nrmse: 0.1020 - 254ms/step Eval begin... step 576/576 [==============================] - loss: 0.0199 - psnr: 33.7080 - ssim: 0.9769 - mse: 5.7330e-04 - rmse: 0.0221 - nrmse: 0.0666 - 77ms/step Eval samples: 576 Epoch 12/20 step 750/750 [==============================] - loss: 0.0130 - psnr: 39.3783 - ssim: 0.9880 - mse: 3.0788e-04 - rmse: 0.0175 - nrmse: 0.1032 - 250ms/step Eval begin... step 576/576 [==============================] - loss: 0.0143 - psnr: 33.6335 - ssim: 0.9761 - mse: 5.3515e-04 - rmse: 0.0219 - nrmse: 0.0687 - 78ms/step Eval samples: 576 Epoch 13/20 step 750/750 [==============================] - loss: 0.0126 - psnr: 39.3804 - ssim: 0.9882 - mse: 3.0458e-04 - rmse: 0.0174 - nrmse: 0.1019 - 251ms/step Eval begin... step 576/576 [==============================] - loss: 0.0147 - psnr: 33.8845 - ssim: 0.9764 - mse: 5.1139e-04 - rmse: 0.0213 - nrmse: 0.0659 - 81ms/step Eval samples: 576 Epoch 14/20 step 750/750 [==============================] - loss: 0.0127 - psnr: 39.3958 - ssim: 0.9885 - mse: 3.0209e-04 - rmse: 0.0173 - nrmse: 0.1008 - 251ms/step Eval begin... step 576/576 [==============================] - loss: 0.0177 - psnr: 33.9112 - ssim: 0.9769 - mse: 5.2632e-04 - rmse: 0.0214 - nrmse: 0.0654 - 81ms/step Eval samples: 576 Epoch 15/20 step 750/750 [==============================] - loss: 0.0136 - psnr: 39.4180 - ssim: 0.9883 - mse: 3.0206e-04 - rmse: 0.0173 - nrmse: 0.1017 - 253ms/step Eval begin... step 576/576 [==============================] - loss: 0.0145 - psnr: 33.8235 - ssim: 0.9762 - mse: 5.1750e-04 - rmse: 0.0215 - nrmse: 0.0670 - 78ms/step Eval samples: 576 Epoch 16/20 step 750/750 [==============================] - loss: 0.0143 - psnr: 39.4749 - ssim: 0.9883 - mse: 3.0055e-04 - rmse: 0.0173 - nrmse: 0.1023 - 258ms/step Eval begin... step 576/576 [==============================] - loss: 0.0152 - psnr: 33.8273 - ssim: 0.9762 - mse: 5.2074e-04 - rmse: 0.0215 - nrmse: 0.0667 - 81ms/step Eval samples: 576 Epoch 17/20 step 750/750 [==============================] - loss: 0.0143 - psnr: 39.4085 - ssim: 0.9882 - mse: 3.0364e-04 - rmse: 0.0173 - nrmse: 0.1024 - 258ms/step Eval begin... step 576/576 [==============================] - loss: 0.0181 - psnr: 33.8912 - ssim: 0.9773 - mse: 5.3866e-04 - rmse: 0.0216 - nrmse: 0.0653 - 77ms/step Eval samples: 576 Epoch 18/20 step 750/750 [==============================] - loss: 0.0108 - psnr: 39.4916 - ssim: 0.9883 - mse: 2.9944e-04 - rmse: 0.0172 - nrmse: 0.1017 - 250ms/step Eval begin... step 576/576 [==============================] - loss: 0.0152 - psnr: 33.9995 - ssim: 0.9776 - mse: 5.0562e-04 - rmse: 0.0211 - nrmse: 0.0651 - 80ms/step Eval samples: 576 save checkpoint at /home/aistudio/SRResNet2_checkpoint/33.9994905972147_0.9776496272199799 Epoch 19/20 step 750/750 [==============================] - loss: 0.0123 - psnr: 39.4804 - ssim: 0.9884 - mse: 2.9989e-04 - rmse: 0.0172 - nrmse: 0.1020 - 250ms/step Eval begin... step 576/576 [==============================] - loss: 0.0188 - psnr: 33.7946 - ssim: 0.9766 - mse: 5.5110e-04 - rmse: 0.0218 - nrmse: 0.0660 - 78ms/step Eval samples: 576 Epoch 20/20 step 750/750 [==============================] - loss: 0.0116 - psnr: 39.4840 - ssim: 0.9885 - mse: 2.9784e-04 - rmse: 0.0172 - nrmse: 0.1014 - 252ms/step Eval begin... step 576/576 [==============================] - loss: 0.0138 - psnr: 33.7688 - ssim: 0.9761 - mse: 5.2588e-04 - rmse: 0.0217 - nrmse: 0.0677 - 80ms/step Eval samples: 576
12、模型评估
13、模型加载
这里需要自行修改路径为自己训练好的最优模型
In [89]
model1 = paddle.Model(Sub_Pixel_CNN(upscale_factor=SCALE, channels=1))
model2 = paddle.Model(VRCNN())
model3 = paddle.Model(EDSR())
model4 = paddle.Model(SRResNet(scaling_factor=SCALE))
model5 = paddle.Model(SRResNet2(scaling_factor=SCALE))
# 更改训练好的参数文件路径
path1 = './'+'Sub_Pixel_CNN'+'_checkpoint/31.98302470744666_0.9644605700936759.pdparams'
path2 = './'+'VRCNN'+'_checkpoint/33.10830663734545_0.9720895701836922.pdparams'
path3 = './'+'EDSR'+'_checkpoint/33.929684575294715_0.9767564802913058.pdparams'
path4 = './'+'SRResNet'+'_checkpoint/33.89847568592299_0.9767209457107034.pdparams'
path5 = './'+'SRResNet2'+'_checkpoint/33.9994905972147_0.9776496272199799.pdparams'
model1.load(path1)
model2.load(path2)
model3.load(path3)
model4.load(path4)
model5.load(path5)
model1.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
model2.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
model3.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
model4.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)
model5.prepare(paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
MY_loss(),
[PSNR(),SSIM(),MSE(),RMSE(),NRMSE()],
)In [90]
eval_result = model1.evaluate(valid_dataset, verbose=1)
print(eval_result)
eval_result = model2.evaluate(valid_dataset, verbose=1)
print(eval_result)
eval_result = model3.evaluate(valid_dataset, verbose=1)
print(eval_result)
eval_result = model4.evaluate(valid_dataset, verbose=1)
print(eval_result)
eval_result = model5.evaluate(valid_dataset, verbose=1)
print(eval_result)Eval begin...
step 576/576 [==============================] - loss: 0.0147 - psnr: 31.9830 - ssim: 0.9645 - mse: 7.3423e-04 - rmse: 0.0261 - nrmse: 0.0812 - 14ms/step
Eval samples: 576
{'loss': [0.014707196], 'psnr': 31.98302470744666, 'ssim': 0.9644605700936759, 'mse': 0.0007342252425683424, 'rmse': 0.02612549203576605, 'nrmse': 0.08117052404292784}
Eval begin...
step 576/576 [==============================] - loss: 0.0165 - psnr: 33.1083 - ssim: 0.9721 - mse: 5.8937e-04 - rmse: 0.0231 - nrmse: 0.0712 - 16ms/step
Eval samples: 576
{'loss': [0.016474213], 'psnr': 33.10830663734545, 'ssim': 0.9720895701836922, 'mse': 0.0005893742774346089, 'rmse': 0.02312634590329537, 'nrmse': 0.07122960735009874}
Eval begin...
step 576/576 [==============================] - loss: 0.0167 - psnr: 33.9297 - ssim: 0.9768 - mse: 5.2138e-04 - rmse: 0.0214 - nrmse: 0.0653 - 27ms/step
Eval samples: 576
{'loss': [0.016662793], 'psnr': 33.929684575294715, 'ssim': 0.9767564802913058, 'mse': 0.0005213828226175968, 'rmse': 0.02135797689015048, 'nrmse': 0.06531595643588545}
Eval begin...
step 576/576 [==============================] - loss: 0.0153 - psnr: 33.8985 - ssim: 0.9767 - mse: 5.1451e-04 - rmse: 0.0214 - nrmse: 0.0660 - 38ms/step
Eval samples: 576
{'loss': [0.0153331375], 'psnr': 33.89847568592299, 'ssim': 0.9767209457107034, 'mse': 0.000514511685700243, 'rmse': 0.02135927935492385, 'nrmse': 0.06596860818669356}
Eval begin...
step 576/576 [==============================] - loss: 0.0152 - psnr: 33.9995 - ssim: 0.9776 - mse: 5.0562e-04 - rmse: 0.0211 - nrmse: 0.0651 - 76ms/step
Eval samples: 576
{'loss': [0.015205394], 'psnr': 33.9994905972147, 'ssim': 0.9776496272199799, 'mse': 0.0005056197565617363, 'rmse': 0.021132341804293478, 'nrmse': 0.06514565318609317}
In [91]
eval_result = model1.evaluate(test_dataset, verbose=1)
print(eval_result)
eval_result = model2.evaluate(test_dataset, verbose=1)
print(eval_result)
eval_result = model3.evaluate(test_dataset, verbose=1)
print(eval_result)
eval_result = model4.evaluate(test_dataset, verbose=1)
print(eval_result)
eval_result = model5.evaluate(test_dataset, verbose=1)
print(eval_result)Eval begin...
step 6720/6720 [==============================] - loss: 0.0203 - psnr: 32.5398 - ssim: 0.9672 - mse: 6.5636e-04 - rmse: 0.0246 - nrmse: 0.0822 - 14ms/step
Eval samples: 6720
{'loss': [0.02031755], 'psnr': 32.539830427359284, 'ssim': 0.9672235772261067, 'mse': 0.0006563644741056527, 'rmse': 0.024589913496600217, 'nrmse': 0.08221971226273445}
Eval begin...
step 6720/6720 [==============================] - loss: 0.0191 - psnr: 33.6162 - ssim: 0.9739 - mse: 5.3276e-04 - rmse: 0.0219 - nrmse: 0.0726 - 16ms/step
Eval samples: 6720
{'loss': [0.019050946], 'psnr': 33.61619445508955, 'ssim': 0.9739401677411571, 'mse': 0.000532762757678194, 'rmse': 0.021890548139242714, 'nrmse': 0.07264575120908957}
Eval begin...
step 6720/6720 [==============================] - loss: 0.0172 - psnr: 34.4152 - ssim: 0.9782 - mse: 4.7115e-04 - rmse: 0.0202 - nrmse: 0.0668 - 28ms/step
Eval samples: 6720
{'loss': [0.017233543], 'psnr': 34.41523104272591, 'ssim': 0.9781520178389941, 'mse': 0.0004711522178964311, 'rmse': 0.020237316807270363, 'nrmse': 0.06675785031451771}
Eval begin...
step 6720/6720 [==============================] - loss: 0.0175 - psnr: 34.3540 - ssim: 0.9781 - mse: 4.6146e-04 - rmse: 0.0202 - nrmse: 0.0674 - 39ms/step
Eval samples: 6720
{'loss': [0.017528508], 'psnr': 34.35399189481974, 'ssim': 0.9781272275380789, 'mse': 0.00046146067341459147, 'rmse': 0.020233175209355865, 'nrmse': 0.06741320430217522}
Eval begin...
step 6720/6720 [==============================] - loss: 0.0179 - psnr: 34.4556 - ssim: 0.9789 - mse: 4.6035e-04 - rmse: 0.0201 - nrmse: 0.0668 - 77ms/step
Eval samples: 6720
{'loss': [0.017926415], 'psnr': 34.45561087813642, 'ssim': 0.9789484842036674, 'mse': 0.00046034884479273275, 'rmse': 0.0200975927738225, 'nrmse': 0.06680956141343233}
14、模型推断
In [92]
# 查看MRI图像
import matplotlib.pyplot as plt
import random
predict_results1 = model.predict(valid_dataset)[0]
predict_results2 = model.predict(valid_dataset)[0]
predict_results3 = model.predict(valid_dataset)[0]
predict_results4 = model.predict(valid_dataset)[0]
predict_results5 = model.predict(valid_dataset)[0]
Predict begin... step 576/576 [==============================] - 64ms/step Predict samples: 576 Predict begin... step 576/576 [==============================] - 64ms/step Predict samples: 576 Predict begin... step 576/576 [==============================] - 63ms/step Predict samples: 576 Predict begin... step 576/576 [==============================] - 64ms/step Predict samples: 576 Predict begin... step 576/576 [==============================] - 64ms/step Predict samples: 576
In [93]
# 从验证集中取出一张图片
index = random.randint(0,len(predict_results1))
img, label = valid_dataset[index]
predict1 = predict_results1[index]
predict2 = predict_results2[index]
predict3 = predict_results3[index]
predict4 = predict_results4[index]
predict5 = predict_results5[index]
fig = plt.figure(figsize=(100,100))
# plt.suptitle('Result',fontsize=60)
plt.subplot(1,7,1)
plt.imshow(img[0],cmap='gray')
plt.title('LR',fontsize=60)
plt.subplot(1,7,2)
plt.imshow(predict1[0][0],cmap='gray')
plt.title('Sub_Pixel_CNN',fontsize=60)
plt.subplot(1,7,3)
plt.imshow(predict2[0][0],cmap='gray')
plt.title('VRCNN',fontsize=60)
plt.subplot(1,7,4)
plt.imshow(predict3[0][0],cmap='gray')
plt.title('EDSR',fontsize=60)
plt.subplot(1,7,5)
plt.imshow(predict4[0][0],cmap='gray')
plt.title('SRResNet',fontsize=60)
plt.subplot(1,7,6)
plt.imshow(predict5[0][0],cmap='gray')
plt.title('SRResNet2',fontsize=60)
plt.subplot(1,7,7)
plt.imshow(label[0],cmap='gray')
plt.title('HR',fontsize=60)
plt.show()
<Figure size 7200x7200 with 7 Axes>
五、总结
-
本项目分析了多个超分辨率模型对MR图像超分的重建结果,我们发现模型很容易过拟合,由于MR图像颜色结构过于单一,即使ssim已经达到很高但psnr却无法接近40,提高训练次数也无法解决。针对此现象,需要提出一种新的结构或方法进一步解决此问题。
参考文献
[1] WANG Z, LIU D, YANG J, et al. Deep networks for image Super-Resolution with sparse prior[C]//2015 IEEE International Conference on Computer Vision (ICCV), Santiago, 2016: 370-378.
[2] WEI W, FENG G, ZHANG D, et al. Accurate single image super-resolution using cascading dense connections[J]. Electronics Letters, 2015, 55(13): 739-742.
[3]HONG X, ZAN Y, WANG W, et al. Enhancing the image quality via transferred deep residual learning of coarse PET sinograms[J]. IEEE Transactions on Medical Imaging, 2018, 37(10):2322-2332.
[4] DONG C, LOY C C, TANG X. Accelerating the Super-Resolution convolutional neural network[C]// 14th European Conference on Computer Vision. Amsterdam: Springer International Publishing. Amsterdam, 2016: 391-407.
[5] Zhao X , Zhang Y , Zhang T , et al. Channel Splitting Network for Single MR Image Super-Resolution[J]. IEEE Transactions on Image Processing, 2019, 28(99):5649-5662.
[6] http://brain-development.org/ixi-dataset/

















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









