









首先总结一下过拟合(高方差、低偏差)的几种解决方法:
- 减少变量选取,即降低特征维度,但这种方法减少了变量的获取。
- 正则化:保留所有特征,但是减少量级或参数theta的值
- 增加数据丰富度,如果是图像问题就可以进行数据增强
- 交叉验证:做十折交叉,选择最好的模型。
- 归一化数据:
测试集的归一化的均值和标准偏差应该来源于训练集。如果你熟悉Python的sklearn的话, 你就应该知道应该先对训练集数据fit,得到包含均值和标准偏差的scaler,然后再分别对训练集和验证集transform。 这个问题其实很好,很多人不注意,最容易犯的错误就是先归一化,再划分训练测试集。
正则化logistic回归:
在实现了logistic回归后,更深一步的想到,logistic回归对线性分类问题能够达到较好的效果,那么对非线性呢?
就需要对logistic回归中样本的特征进行升维,然后为防止过拟合,进行正则化。
代码实现notebook版:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 本次我们使用工具库来计算theta,scipy中的函数能够返回最优的结果
import scipy.optimize as opt
# 数据可视化
path = '~/condaProject/WUENDA/work2/ex2data2.txt'
data = pd.read_csv(path, header=None, names=['Test 1', 'Test 2', 'Accepted'])
data.head()

positive = data[data['Accepted'].isin([1])]
negtive = data[data['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negtive['Test 1'], negtive['Test 2'], s=50, c='r', marker='x', label='UnAccepted')
ax.legend()
ax.set_xlabel('Test 1 score')
ax.set_ylabel('Test 2 score')
plt.show()
# 能够从图像中看出这个数据集并不是是一个线性可分的数据
# 所以不能直接使用logistic回归
data2 = data
x1 = data2['Test 1']
x2 = data2['Test 2']
data2.insert(3, 'Ones', 1)
# 由于两个特征只能线性分割(即两个未知数只能划分一条直线),不能很好的形容此模型,所以要升维
# 所以把x1、x2两个特征从1次幂增到6次幂,然后组合起来,形成多个特征
for i in range(1, 7):
for j in range(0, i+1):
data2['F' + str(i-j) + str(j)] = np.power(x1, i-j) * np.power(x2, j)
# a = [1, 2, 3]
# np.power(a, 2)
# data2.columns
data2.drop('Test 1', axis=1, inplace=True)
data2.drop('Test 2', axis=1, inplace=True)
print(data2)
以上就是数据处理部分的内容,那么接下来,要实现代价函数。代价函数公式为:
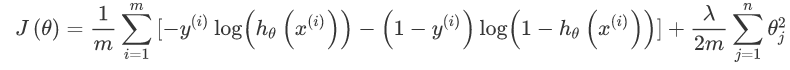
但是 theta0 不需要正则化,从 theta1 开始,使用梯度下降后的公式为:
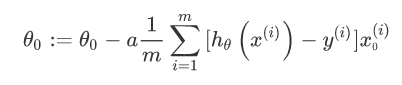
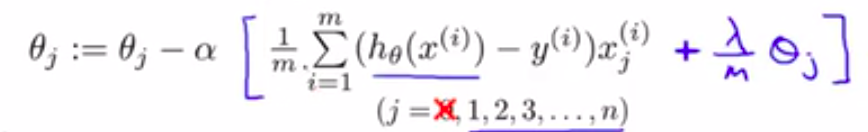
第二个式子可以整理为:

其中,lambda为正则化率,增加lambda的值将会增强正则化效果。
做个课外补充:
<insert>
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
- 如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。
- 如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
- 将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
理想的 lambda 值生成的模型可以很好地泛化到以前未见过的新数据。 遗憾的是,理想的 lambda 值取决于数据,因此您需要手动或自动进行一些调整。
</ insert>
把初始化的theta带入到,结果应为0.693。
# 实现正则化的代价函数
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T))) # 对应位置相乘
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / (2 * len(X))) * np.sum(np.power(theta[:, 1:theta.shape[1]], 2)) # 正则项,learningRate就是公式中的lambda
return np.sum(first - second) / len(X) + reg
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 实现正则化的梯度函数
def gradientReg2(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1]) # 获取列数
grad = np.zeros(parameters)
# print(sigmoid(X * theta.T).shape)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:, i]) # 误差跟样本第i列对应位置相乘
if(i == 0): # 如果是theta0则不用加正则项
grad[i] = np.sum(term) / len(X)
else: # 出theta0以外加正则项
grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:, i])
return grad
# 初始化X,y,theta
cols = data2.shape[1]
X2 = data2.iloc[:, 1:cols]
y2 = data2.iloc[:, 0:1]
# print(X2)
# print(y2)
theta2 = np.zeros(cols - 1)
# 数据类型转换
X2 = np.array(X2.values)
y2 = np.array(y2.values)
# lambda 设置为 1
learningRate = 1
# 计算初始代价
costReg(theta2, X2, y2, learningRate)
![]()
result2 = opt.fmin_tnc(func = costReg, x0 = theta2, fprime = gradientReg2, args=(X2, y2, learningRate))
result2
# 使用预测函数查看准确度
# 定义预测函数
def predict(theta, X):
probability = sigmoid(X * theta.T)
# print(len(probability))
return [1 if x >= 0.5 else 0 for x in probability]
theta_final = np.matrix(result2[0])
predictions = predict(theta_final, X2)
correct = [1 if (a == 1 and b == 1) or (a == 0 and b == 0) else 0 for (a, b) in zip(predictions, y2)]
accuracy = sum(map(int, correct)) % len(correct)
print("acc = {0} %".format(accuracy))![]()
# 画出决策曲线
# 把测试集的x1、x2用theta计算预测值
def hfunc2(theta, x1, x2):
temp = theta[0][0]
place = 0
for i in range(1, 7):
for j in range(0, i+1):
temp += np.power(x1, i-j) * np.power(x2, j) * theta[0][place + 1]
# 这里使用将x1、x2升维的手段,然后在后面乘每个特征的系数theta
place += 1
return temp
def find_decision_boundary(theta):
t1 = np.linspace(-1, 1.5, 1000) # 因为训练数据的值处于这个区间
t2 = np.linspace(-1, 1.5, 1000)
cordinate = [(x, y) for x in t1 for y in t2] # t1、t2组合生成1000,000个点
x_cord, y_cord = zip(*cordinate) # 获得1000,000个点的x值和y值
h_val = pd.DataFrame({'x1':x_cord, 'x2':y_cord}) # 将1000,000个点存成pandas数据
h_val['hval'] = hfunc2(theta, h_val['x1'], h_val['x2']) # 用result2迭代计算出的theta值带入,算出预测值
# print(h_val.iloc[139530]) # 取第139530行
decision = h_val[np.abs(h_val['hval']) < 2 * 10**-3] # Dataframe条件筛选,筛选出预测值小于0.002的
return decision.x1, decision.x2 # 返回满足条件的x1,x2的值
# 画图
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negtive['Test 1'], negtive['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
x, y = find_decision_boundary(result2)
plt.scatter(x, y, c='y', s=10, label='Prediction')
ax.legend()
plt.show()
改变λ,观察决策曲线
在λ=0时,出现过拟合现象
learningRate2 = 0
result3 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg2, args=(X2, y2, learningRate2))
result3
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negtive['Test 1'], negtive['Test 2'], s=50, c='r', marker='x',label='Rejected')
ax.set_xlabel('Test 1 score')
ax.set_ylabel('Test 2 score')
x, y = find_decision_boundary(result3)
plt.scatter(x, y, c='y', s = 10, label='Predict')
ax.legend()
plt.show()
在λ=100时,出现欠拟合现象
learningRate3 = 100
result4 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg2, args=(X2, y2, learningRate3))
result4
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negtive['Test 1'], negtive['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.set_xlabel('Test 1 score')
ax.set_ylabel('Test 2 score')
x, y = find_decision_boundary(result4)
plt.scatter(x, y, c='y', s=10, label='Prediction')
ax.legend()
plt.show()
数据集(保存为txt文件即可,118*3):
0.051267,0.69956,1
-0.092742,0.68494,1
-0.21371,0.69225,1
-0.375,0.50219,1
-0.51325,0.46564,1
-0.52477,0.2098,1
-0.39804,0.034357,1
-0.30588,-0.19225,1
0.016705,-0.40424,1
0.13191,-0.51389,1
0.38537,-0.56506,1
0.52938,-0.5212,1
0.63882,-0.24342,1
0.73675,-0.18494,1
0.54666,0.48757,1
0.322,0.5826,1
0.16647,0.53874,1
-0.046659,0.81652,1
-0.17339,0.69956,1
-0.47869,0.63377,1
-0.60541,0.59722,1
-0.62846,0.33406,1
-0.59389,0.005117,1
-0.42108,-0.27266,1
-0.11578,-0.39693,1
0.20104,-0.60161,1
0.46601,-0.53582,1
0.67339,-0.53582,1
-0.13882,0.54605,1
-0.29435,0.77997,1
-0.26555,0.96272,1
-0.16187,0.8019,1
-0.17339,0.64839,1
-0.28283,0.47295,1
-0.36348,0.31213,1
-0.30012,0.027047,1
-0.23675,-0.21418,1
-0.06394,-0.18494,1
0.062788,-0.16301,1
0.22984,-0.41155,1
0.2932,-0.2288,1
0.48329,-0.18494,1
0.64459,-0.14108,1
0.46025,0.012427,1
0.6273,0.15863,1
0.57546,0.26827,1
0.72523,0.44371,1
0.22408,0.52412,1
0.44297,0.67032,1
0.322,0.69225,1
0.13767,0.57529,1
-0.0063364,0.39985,1
-0.092742,0.55336,1
-0.20795,0.35599,1
-0.20795,0.17325,1
-0.43836,0.21711,1
-0.21947,-0.016813,1
-0.13882,-0.27266,1
0.18376,0.93348,0
0.22408,0.77997,0
0.29896,0.61915,0
0.50634,0.75804,0
0.61578,0.7288,0
0.60426,0.59722,0
0.76555,0.50219,0
0.92684,0.3633,0
0.82316,0.27558,0
0.96141,0.085526,0
0.93836,0.012427,0
0.86348,-0.082602,0
0.89804,-0.20687,0
0.85196,-0.36769,0
0.82892,-0.5212,0
0.79435,-0.55775,0
0.59274,-0.7405,0
0.51786,-0.5943,0
0.46601,-0.41886,0
0.35081,-0.57968,0
0.28744,-0.76974,0
0.085829,-0.75512,0
0.14919,-0.57968,0
-0.13306,-0.4481,0
-0.40956,-0.41155,0
-0.39228,-0.25804,0
-0.74366,-0.25804,0
-0.69758,0.041667,0
-0.75518,0.2902,0
-0.69758,0.68494,0
-0.4038,0.70687,0
-0.38076,0.91886,0
-0.50749,0.90424,0
-0.54781,0.70687,0
0.10311,0.77997,0
0.057028,0.91886,0
-0.10426,0.99196,0
-0.081221,1.1089,0
0.28744,1.087,0
0.39689,0.82383,0
0.63882,0.88962,0
0.82316,0.66301,0
0.67339,0.64108,0
1.0709,0.10015,0
-0.046659,-0.57968,0
-0.23675,-0.63816,0
-0.15035,-0.36769,0
-0.49021,-0.3019,0
-0.46717,-0.13377,0
-0.28859,-0.060673,0
-0.61118,-0.067982,0
-0.66302,-0.21418,0
-0.59965,-0.41886,0
-0.72638,-0.082602,0
-0.83007,0.31213,0
-0.72062,0.53874,0
-0.59389,0.49488,0
-0.48445,0.99927,0
-0.0063364,0.99927,0
0.63265,-0.030612,0















 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









