







文章来源:AAAI 2021
文章地址:https://arxiv.org/pdf/2012.01775.pdf
摘要
最近的预训练模型极大的改进了基于神经网络的回复生成。然而现有的方法通常将对话上下文看作是一个线性的Token序列,这样的字符及编码方式阻碍了探寻对话建的篇章连贯性。文本提出DialogBERT,一种新型的对话回复生成模型来增强之前的PLM对话模型。DialogBERT使用一个层次化的Transformer架构。为了更有效的捕获篇章级连贯性,我们提出两个训练目标,包括对话掩码回归和分布式对话顺序排序在原始的BERT训练中。实验结果显示我们在3个多轮对话数据集中相较于基准系统都有了显著的提升,例如BART和DialogGPT等。人工评估显示DialogBERT能生成更连贯、更有丰富信息量和更受人类喜欢的回复。
引言
多轮开放式对话建模是自然语言处理中活跃的研究话题。然而如何生成连贯的、有丰富信息量的反馈目前仍然是一个挑战。其中一个挑战是如何学习更加丰富和鲁棒的上下文表示,也就是编码对话上下文信息到一个向量中的挑战。
大规模与预训练模型使用Transformer架构最近取得显著性成果。同样的,也有大量研究使用预训练模型来进行对话建模。例如DialogGPT以及Meena等。
然而现有的方法都是将对话上下文看作是线性序列,学习到的是字符级的自注意力。这种方法的一个问题是对话间的高层关系没有办法通过字符级的语义来捕获。例如一个例子。而且,这种成对的注意力是无效的因为他需要上下文中的每一个字词。
为了缓解以上问题,我们构建了DialogBERT,一种新型的对话回复生成模型。DialogBERT使用一种层次化的Transformer架构来表示对话的上下文。它首先编码每个对话通过一个Transformer编码器然后编码对话的结果向量使用一个篇章级的Transformer来捕获整个对话的上下文。为了更有效的捕获对话间篇章级连贯性,我们提出两个训练目标:1)上下文掩码回归,也就是随机掩码一个对话然后预测这个编码向量。2)分布式对话顺序排序,这会组织随机的对话顺序到一个连贯性对话上下文通过一个学习排序的神经网络。
我们在3个流行的对话数据集上进行了评估。实验显示我们的模型显著由于基准系统。人工评估也显示我们的方法能够捕获篇章级的语义并生成更加友好的对话回复。
相关工作
这个工作与预训练模型、适用于对话的预训练模型以及使用多任务改善预训练模型相关。
- 预训练模型.预训练模型从向量到模型建模,最近又开始了基于Transformers的大规模预训练模型。最近也有使用去噪的自动编码框架来进行。
- 对话的预训练模型。有很多预训练模型,包括DialogGPT,Meena和Blender等。
- 预训练的多任务学习。
方法
给定一个对话序列,我们想达成的目标有以下2个:学习对话的上下文C以及根据C条件生成对话Ut。
层次化的Transformer编码器
为了获得一个更好的C表示,我们使用一个层次化的Transformer编码器架构。如图1 所示,一层编码器为编码每一个对话,一个上下文编码器用于学习对话的上下文信息。
对于每一个对话u,使用和BERT一样的编码方式,放置[CLS]和[SEP]在开始和结束位置。然后,使用一个嵌入层映射u到一个连续的空间:
e
i
=
(
w
1
i
+
p
1
,
w
2
i
+
p
2
,
.
.
.
,
w
∣
u
i
∣
i
+
p
∣
u
i
∣
)
e_i=(w^i_1+p_1, w^i_2+p_2,...,w^i_{|u_i|}+p_{|u_i|})
ei=(w1i+p1,w2i+p2,...,w∣ui∣i+p∣ui∣)
然后对话会被送入一个编码器
f
θ
f_{\theta}
fθ中获得一系列隐藏表示。我们使用第一个隐藏向量用来表示这个对话,与单词表示一样,最终的对话表示也是
u
i
=
u
1
i
+
p
i
u_i=u^i_1+p_i
ui=u1i+pi。
类似于对话编码器,上下文编码器是另一个transformer编码器。如图1所示。经过这个编码器后,对话表示被表示为上下文敏感的对话表示。
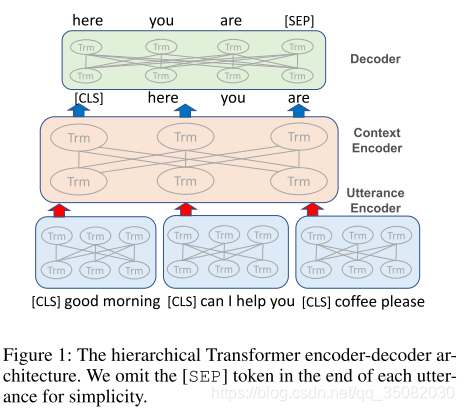
层次化的transformer架构来源于HIBERT。虽然两个方法都是层次化编码,但是有显著的不同。DialogBERT有两个新的损失部分用于对话的连贯性建模,也就是对话回归以及对话的排序。
接下来介绍我们的无监督的学习目标在DialogBERT的训练中。
训练目标
为了捕获篇章级的连贯性在对话上下文中,受到BERT的启发,在最大化解码单词概率外,我们提出两种新型目标。
下一句生成
作为最重要的目标,第一个训练目标是给定对话上下文,生成下一个回复。如图1所示,我们首先使用层次化的编码器来编码上下文C并获得其语义表示H。然后,我们使用Transformer解码器来生成下一句对话。解码器预测每一个单词序列并且遵循下面的概率分布。最后该任务最小化交叉熵损失如下:
L
dec
(
θ
,
ϕ
,
ψ
∣
w
1
T
,
…
,
w
N
T
,
C
)
=
−
∑
i
=
1
N
log
p
ψ
(
w
i
T
∣
w
<
i
T
,
H
)
\mathcal{L}_{\operatorname{dec}}\left(\theta, \phi, \psi \mid w_{1}^{T}, \ldots, w_{N}^{T}, \mathcal{C}\right)=-\sum_{i=1}^{N} \log p_{\psi}\left(w_{i}^{T} \mid w_{<i}^{T}, \mathbf{H}\right)
Ldec(θ,ϕ,ψ∣w1T,…,wNT,C)=−i=1∑Nlogpψ(wiT∣w<iT,H)
对话掩码回归
与MLM类似,我们设计了对话掩码回归作为辅助任务来增强上下文表示学习。给定一个对话上下文C,我们随机选择一个对话,80%替换为MASK掩码,10%不替换,10%替换为随机的一个对话。然后我们尝试重建这个掩码对话的向量。
获得掩码上下文C后,我们预测了原始的对话向量。我们首先应用了层次编码来获得上下文影响的对话向量。然后我们讲这些表示送入到原始的对话向量,使用全连接层。最后,我们通过在预测的向量表示和原始向量之间的最小化均方误差来优化模型。
L
m
u
r
(
θ
,
ϕ
,
W
,
b
∣
u
~
1
,
…
,
u
~
∣
C
∣
,
C
,
C
~
,
)
=
1
∣
C
~
\
C
∣
∑
u
i
∈
C
~
\
C
∥
u
^
i
−
u
i
∥
2
2
\mathcal{L}_{m u r}\left(\theta, \phi, \mathbf{W}, \mathbf{b} \mid \tilde{\mathbf{u}}_{1}, \ldots, \tilde{\mathbf{u}}_{|\mathcal{C}|}, \mathcal{C}, \tilde{\mathcal{C}},\right)=\frac{1}{|\tilde{\mathcal{C}} \backslash \mathcal{C}|} \sum_{u_{i} \in \tilde{\mathcal{C}} \backslash \mathcal{C}}\left\|\hat{\mathbf{u}}_{i}-\mathbf{u}_{i}\right\|_{2}^{2}
Lmur(θ,ϕ,W,b∣u~1,…,u~∣C∣,C,C~,)=∣C~\C∣1ui∈C~\C∑∥u^i−ui∥22
分布式对话顺序排序
连贯性是对话建模的一个重要方面。在一个连贯的篇章中,对话中关系和逻辑应当遵循着特定的顺序。对话的顺序决定着对话的语义。因此我们假定学到无序的对话的顺序可以最大化对话的连贯性,这也能够明显影响学习对话的上下文表示。
对话重排序任务的母校是组织随机打乱的对话到一个连贯的对话上下文中。形式上讲,给定一个上下文C与一个顺序o,我们想学习一个特定的排序,这个排序拥有最连贯的对话上下文。
之前的工作建模句子间的顺序预测作为重排索引的分类任务。也就是说,每个排列都会有一个类别,然后将无序的句子直接分类到这个类别中。这样由于搜索空间复杂度的问题,导致性能不佳。
本文中,我们设计了一个分布式排序网络(DORN)。提待遇直接分类索引,DORN预测每个对话的顺序索引在一个分布式形式下。如图3所示,将打乱后的对话的隐向量状态作为输入送入编码器中,然后产生每个单独对话的分值。这些分支会被用来重排序这些对话。受到自注意力机制的启发,顺序预测网络计算这些隐状态间点积然后计算每个对话的分值S,通过平均所有与其他对话的内积:
s
i
=
1
∣
C
∣
∑
j
=
1
∣
C
∣
W
h
i
T
h
j
s_{i}=\frac{1}{|\mathcal{C}|} \sum_{j=1}^{|\mathcal{C}|} \mathbf{W h}_{i}^{T} \mathbf{h}_{j}
si=∣C∣1j=1∑∣C∣WhiThj
在训练阶段,我们使用学习排序框架。具体的,我们视预测分数为每个对话在上下文中排名第一的程度。给定这些分数,我们通过softmax来评估排名第一概率:
P
^
(
u
i
)
=
exp
(
s
i
)
∑
j
=
1
∣
C
∣
exp
(
s
j
)
\hat{P}\left(u_{i}\right)=\frac{\exp \left(s_{i}\right)}{\sum_{j=1}^{|\mathcal{C}|} \exp \left(s_{j}\right)}
P^(ui)=∑j=1∣C∣exp(sj)exp(si)
因此,我们通过赋予每个对话一个标准的目标值来指示真实的顺序。然后,排名第一的概率就会被给出:
P
(
u
i
)
=
exp
(
y
i
)
∑
j
=
1
∣
C
∣
exp
(
y
j
)
P\left(u_{i}\right)=\frac{\exp \left(y_{i}\right)}{\sum_{j=1}^{|\mathcal{C}|} \exp \left(y_{j}\right)}
P(ui)=∑j=1∣C∣exp(yj)exp(yi)
这里需要指出的是
y
i
=
i
∣
C
∣
y_i=\frac{i}{|C|}
yi=∣C∣i。我们的目标是最小化KL散度:
L
d
u
o
r
(
θ
,
ϕ
,
W
∣
P
,
C
)
=
K
L
(
P
^
(
u
)
∥
P
(
u
)
)
=
∑
k
=
1
∣
C
∣
P
^
(
u
k
)
log
(
P
^
(
u
k
)
P
(
u
k
)
)
\mathcal{L}_{d u o r}(\theta, \phi, \mathbf{W} \mid P, \mathcal{C})=\mathrm{KL}(\hat{P}(u) \| P(u))=\sum_{k=1}^{|\mathcal{C}|} \hat{P}\left(u_{k}\right) \log \left(\frac{\hat{P}\left(u_{k}\right)}{P\left(u_{k}\right)}\right)
Lduor(θ,ϕ,W∣P,C)=KL(P^(u)∥P(u))=k=1∑∣C∣P^(uk)log(P(uk)P^(uk))
最后,我们的损失为三者之和:
L
total
=
L
dec
+
λ
0
×
L
mur
+
λ
1
×
L
duor
\mathcal{L}_{\text {total }}=\mathcal{L}_{\text {dec }}+\lambda_{0} \times \mathcal{L}_{\text {mur }}+\lambda_{1} \times \mathcal{L}_{\text {duor }}
Ltotal =Ldec +λ0×Lmur +λ1×Lduor
其中权重都为1。
实验设置
数据集
我们在下面数据集中评估DialogBERT。Weibo是一个大规模多轮对话基准,在NLPCC2018中引入。它使用的是新浪微博来训练对话模型。MultiWOZ是一个人与人对话的等多领域和多话题语料库。它包含10K的对话。尽管这是被设计与任务型对话,但是它的闲聊风格也适合训练开放领域对话。DailyDialog也是一个被广泛使用对话生成模型。这个数据集包含多轮日常对话。相比较Weibo和MultiWOZ, DailyDialog包含更多的日常对话。
实现和复现
我们使用Huggingface的transformer实现。我们训练了两个不同规格的模型来适应数据集。对于weibo数据集,我们使用的是标准的transformer(bert-base-chinese)的编码器和解码器。在MultiWOZ和DailyDialog这两个小规模的数据集上,使用了小模型,小模型参数减半(L=6,H=256,A=2)我们限制了上下文的对话数量为7每个对话长度为30。所有的实验都使用BERT的基础分词器。所有模型也都用AdamW优化,学习率为5e-5。我们使用适应学习率通过5000步热身。我们使用Pytorch实现所有模型。我们在一台Ubuntu16.04和Tesla P40的GPU机器上实验。
我们每两千步迭代Validation loss并选择最好的参数。测试结果从最好的检查点获得。我们实验了5词并汇报了平均结果。我们使用NSML寻找超参数。在生成回复中,我们使用top-1采样。
基准系统
我们与其他基于Transformer的模型进行比较:(1)BART;(2)DialoGPT;(3)ContextPretrain。评价指标上,我们使用BLEU和NIST。
评估结果
自动评价
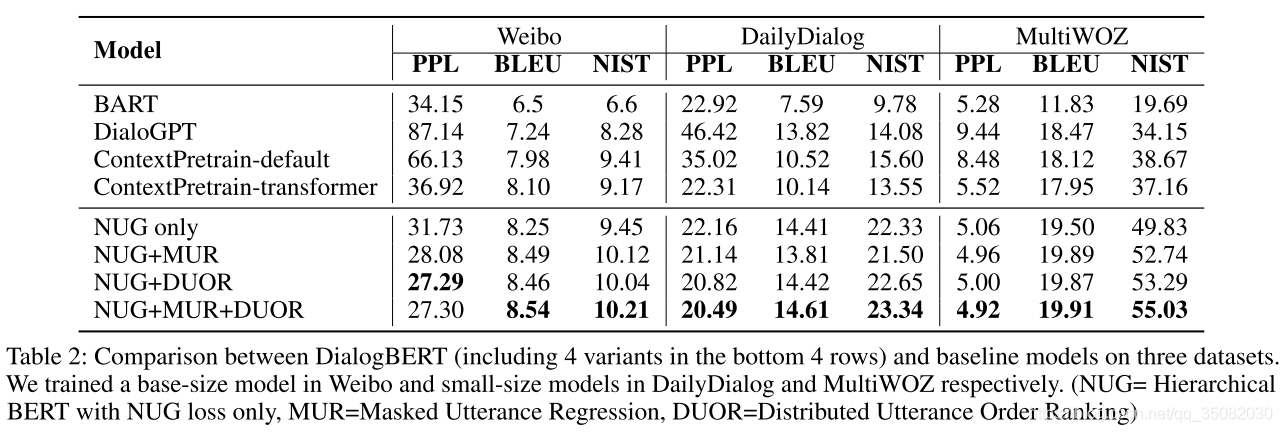
表2表明了我们自动指标。为了证明所提出的训练目标的有效性,我们展示了DialogBERT以及不同组合的消融模型的结果。一般来讲,DialogBERT在大多数指标中都取得了最优性能,尤其是在混乱度上。相比较BART或者DialoGPT等将上下文线性编码的模型,DilogBERT明显优于基准系统。这样的改进在3个数据集上均有所体现,证明了DialogBERT模型使用层次化Transformer架构的优越性。
结果显示,提出的两个训练目标在层次化的Transformer结构上都取得了改进。而且两者组合能够进一步增强性能。有趣的是,在Weibo数据集上性能的改进相当明显。我们推测其原因是丰富的数据,使得辅助训练目标有更高的上限。
在所有的3个数据集中,DialgGPT表现的都是相当的差。这可能是由于GPT-2的语言的自回归特性以及单轮设定。我们将会在样例分析中继续探讨。
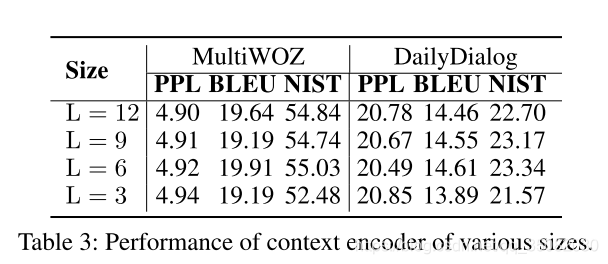
为了探寻上下文编码器的有效性,我们进行了编码器大小的消融实验。我们使用了不同数量的Transormer层在上下文编码器中。如表3所示,不同数量的层对于性能的影响不大,我们猜测可能是由于篇章级交互相比较字级别交互更容易被捕获到。
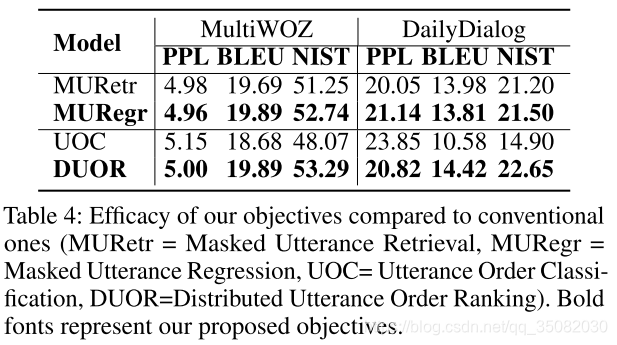
而且,我们我们还做了消融实验对于两个训练目标的影响,我们比较了两个对于段落的之前已经提出的学习目标,叫做掩盖对话抽取和对话顺序分类。如表4所示,已提出的MURegr已经表现和掩码对话抽取差不多的性能,支持了这个想法:MURegr对于对话的上下文表示是一个简单但是有效的组件。一个解释是MURegr提供了比负样本分类更细致的表示学习。因此对于丢失的对话重建来说,精确匹配(回归)比分类目标更有用。同时,DUOR的学习目标比现存的对话顺序分类目标更有用。
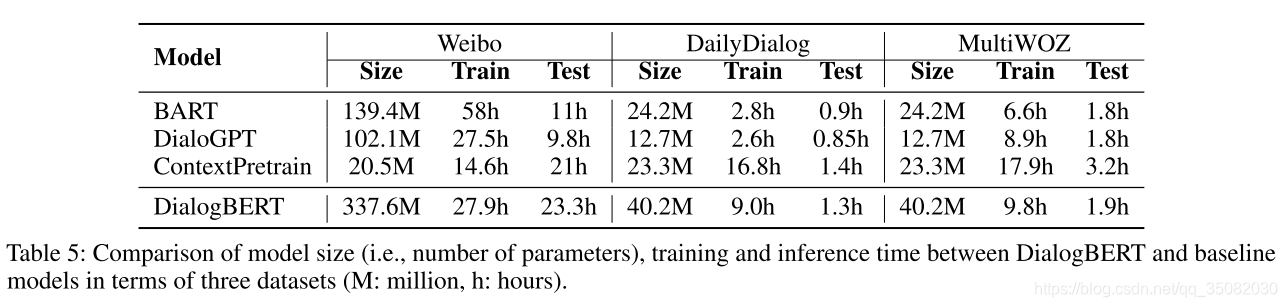
我们进行了时间复杂度的分析。表5显示模型大小,训练和测试时间复杂度。尽管DialogBERT拥有更大的模型由于增加了额外的上下文编码器,但是并没有显著的增长因为上下文的编码器通常很短。
人工评估

我们也使用了亚马逊众包平台进行人工评估。我们使用了DailyDialog作为评估语料库因为它的特点(日常对话)使得它对于标注者的评判更加容易。我们随机抽取了200个样例进行评价。对于每个样例,我们提供3个部分:(1)整个对话上下文;(2)通过我们的模型生成的回复;(3)其他竞争模型所生成的回复。对于每个样本回复,我们要求3个不同的标注者使用3个评估准则来盲评其质量,并使用3点式评价:赢(我们的模型更好),输(我们的模型更差),平局(同等性能)。我们过滤了一些低质量的回答。表6显示了答案的整体分布。总的来说,标注者比较倾向于我们的模型。
样例分析

我们提供了两个生成对话的样例在表7中。这两个样例都显示了,相较于基准系统,我们的DialogBERT可以生成更加连贯的回复,这与我们的自动和人工评估的结果一致。有趣的是,DialogBERT显示出它能够生成细节从而使得回复更像人类。例如第一个,DialogBERT生成了非常详细的回复,例如“98国王大街”和“邮编cb1ln”替代了其他模型中生成的模糊回复。
而且,在两个例子中,相比较其他模型,DialoGPT产生了更加不相关的结果。这和其单轮设定有关。具体来说DialoGPT将对话声称看作是一个单纯的自回归语言模型。整个上下文被看做是输入端的生成子序列,使得其很难处理多轮对话,尤其是在小样本集中。
我们的观察表明相比较传统的Transformer编码器,DialogBERT可以生成更好的多轮对话。
结论
本文中,我们提出了一个神经生成回复的模型称为DialogBERT。不同于将对话上下文看作是一个线性的字符序列,DialogBERT使用一个层次化的Transformer编码器架构。作为一个原始BERT训练的自然扩展,我们提出两个训练目标:掩码对话回归并且分布式的对话重排序。我们显示提出的训练模型能够使得对话模型捕获到多个层次的连贯性。另外,我们展示出DialogBERT在回复生成任务中可以显著强于基准系统。


















 3070
3070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











