







寻找合适的人类反馈数据
想要得这样的机器人,首先需要通过合适的数据了解人类的偏好。这样的数据应该是一对多的聊天形式,即在同一个聊天场景下有多条回复,每个回复有反应其受欢迎程度的指标,表示该回复所收到的反馈的热烈程度。
然而,直接收集一对多的聊天数据并雇佣人类进行标注费时耗力。况且反馈热烈程度的标注不是一位标注者就可以的,而需要多人进行投票。同时,其他常规的可以自动计算的质量评测指标,如词语多样性等,也并不能反映人类的偏好程度。
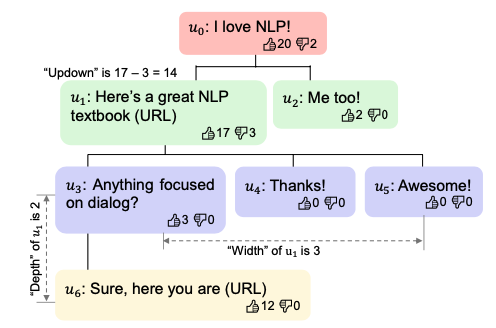
图1:社交媒体中帖子的回复的树状结构。
有三个可以衡量的人类反馈程度的指标:Updown=点赞数-反对数;Depth:深度,后续回复的轮数。Width:宽度,直接回复该评论的评论数目。
因此,研究者从社交网络寻找合适的人类反馈数据。
如图1所示,社交网络上的帖子和回复评论可以组成一个树状结构。每个节点表示一条评论,包含它的内容,点赞/反对数目信息。每个节点的父节点是它所回复的评论,每个节点的子节点是回复它的评论。对一个节点来说,从根节点到其父节点的路径定义它产生的语境C(上文信息),这条评论也就是针对该语境C的回复r。在这样的设定下,就可以得到一条对话数据(C, r)。由于一条评论可以获得多条回复,即一个父节点可以拥有多个子节点,正是一对多形式的对话数据。
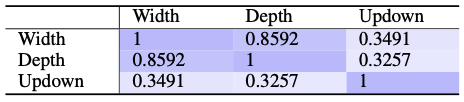
图2: 不同人类反馈指标的Spearman系数,数值越大表示两个指标的相关性越高。
每一条评论的反馈数据包含三种:(1)宽度:获得评论的数目,即子节点的数目。(2)深度:在此之后评论回复的轮数,即子孙节点的最大深度。(3)赞同数,包含点赞数和反对数。作者利用Reddit网站上的数据对这三个指标进行根据相关性研究。
结果如图2所示,宽度和深度具有较强的相关性,但与点赞数的相关性却比较弱。作者猜测可能的原因是人们点赞表示赞同后就不再评论了。值得注意的是,此处的Updown指标为点赞数和反对数的差值。也许有争议的帖子更能激起人们的讨论,那么点赞数和反对数都比较多或者差距较小的帖子反而会引起激烈的讨论,宽度和深度更大。
这三个指标均可以从一些方面反映人类反馈的热烈程度。但根据相关研究,尽管点赞数和受欢迎程度大体相关,但也受许多其他因素的影响。首先,这些指标均表现出长尾分布的特性,少量的回复收到了绝大多数的回复和点赞。此外,这些指标还与帖子所在的板块,评论发布的时间和发布者在社交网络的影响力有关。因此在使用这些数据训练模型时,需要仔细进行规范化。
DIALOGRPT:基于GPT2的12层transformer模型
接下来,研究者利用这些数据将人类的对回复的偏好信息注入模型。给定一个聊天场景C和一系列回复,模型需要根据这些回复收到的反馈的热烈程度,即宽度、深度、点赞数三个指标,分别对它们进行排序。
现存的聊天系统主要回复相关性(如困惑度perplexity和互信息)或人工设计的特征来衡量候选集中回复的合适程度。这种方式无法以端到端的形式直接利用现实世界中的人类反馈数据进行训练。
前文提及过,众多因素均可能对一条评论的收到反馈的情况产生影响,因此作者将排序问题转换为比较问题。在训练过程中,模型不再单独预测一条评论的分数,而是每次比较两条具可比性的回复:训练模型对正例(获得的回复或点赞更多)赋予更高的分数。
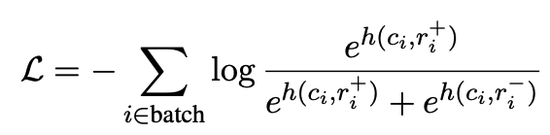
图3:DIALOGRPT目标函数,优化时同时最大化正例(+)的分值,最小化负例(-)的分值。
为了使正负例具有可比性,作者对数据对做了严格的限制:(1)正负例两条回复产生于同一聊天场景,即它们的C相同。也就是在社交网络回复树中,两条评论的父节点相同。(2)两条评论产生的时间间隔不超过确定的阈值(本文中为一小时)。避免时间差过大对反馈情况带来的影响。(3)正例的回复数需超出负例某一阈值以上,以减小噪声。由于三个衡量回复的指标具有长尾特性,作者同时使用了绝对值阈值和百分比阈值对数据进行筛选,同时去掉反对数大于点赞数的数据。在多指标训练过程中,为了防止只有某一个指标产生作用,模型对它们进行加权组合。
在考虑了人类喜好程度的基础上,模型仍要可以同时评价回复的和聊天场景的内容相关性。因此,研究者引入了human-vs-fake任务,即给定语境和评论,判断该评论是否来自此聊天场景。

图4: 模型从两个方面对回复进行测评:人类的偏好程度(3个指标)和评论的“类人”程度。两部分的训练数据情况如右图所示。
研究者从Reddit网站上爬取了2011-2012年的帖子和组成的1.47亿聊天数据(数据集已开源)。再学习人类偏爱信息的任务中,按照前文体积的处理方法共得到1.33亿对数据。
在学习内容相关性信息的任务中,负例通过两种途径得到:(1)检索式(Sampled):随机从训练集中抽取。(2)生成式(Generated):使用对话生成模型DialoGPT生成回复作为负例。由于DialoGPT模仿人类生成回复的能力非常强,因此作者只选择5.30万高反馈值的回复作为正例,以此和机器生成的结果进行区分。
利用这些数据,作者训练了基于GPT2的12层transformer模型DIALOGRPT(Dialog Ranking Pretrained Transformer),并使用DIaloGPT-medium初始化部分参数。作者将模型和BoW(词袋模型),Dialog perplexity(对话困惑度),BM2.5(关键词相似度衡量指标),ConvRT(Reddit数据上预训练的基于transformer模型)和长度等基准方法在不同实验设定下进行比较。

图4:实验结果样例。
从词袋模型的分析结果中可以发现,包含较少信息量的回复收到的回应和点赞数目也比较少。而问题形式的回复(what/who/why/how)引起的对话更长(更深),受众更广的评论(anyone,everyone)会收到更多的直接评论(更宽)。如图4所示,DIALOGRPT模型也捕捉到了这样的信息。
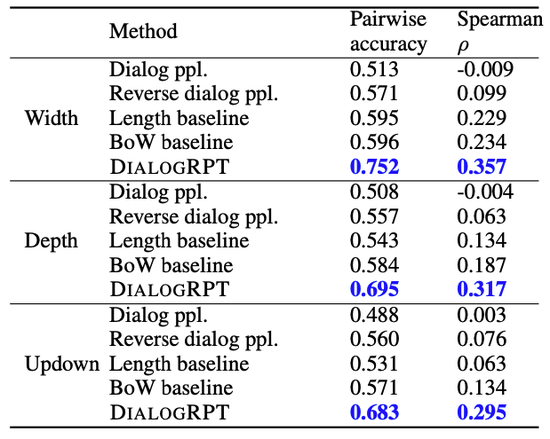
图5:排序测评结果。
Pairwise列:给定同一聊天场景下的一组正负例,模型赋予正例更高分值的比率。Spearman列:为同一聊天场景下的一组回复排序。
接下来,作者通过两种排序方式对模型的能力进行定量测评。(1)与训练阶段的目标相同,给定正负两个样例,测试模型能否赋予正例更高的分数。(2)给定一组相同聊天场景下的回复,通过Spearman系数衡量模型排序结果与人类实际喜好程度的差异。
在两种不同的设定下,DIALOGRPT的效果均显著超过其他方法。
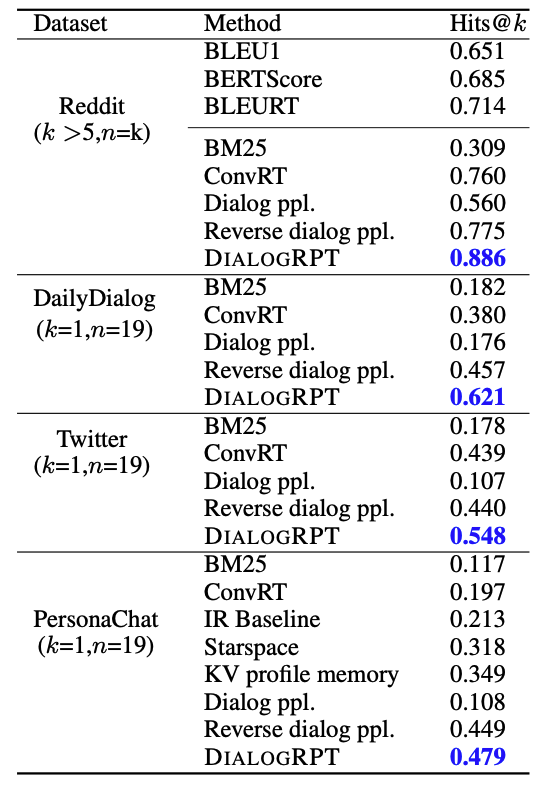
图6:不同数据集上的回复检索实验结果。
模型需要根据聊天场景信息检索合适的回复。Hits@k表示排列后的回复列表中,正确答案出现在前k个中的比率。K值代表K值代表对应数据集每个聊天场景下人类回复的个数,也就是正确答案的个数。
作者还将在Reddit上训练的模型直接应用于DailyDialog,Twitter,PersonaChat等数据集,根据聊天的场景检索合适的回复。如图6,该模型未曾在这些数据集上训练仍取得了最佳的结果。在Reddit数据集中,每个聊天场景下有多条正确的回复(k>5),因此作者引入了BLEU等基于参考的测评指标进行比较。DIALOGRPT模型并不能看到这些参考数据,但它显著超过了使用这些参考回复的方法。
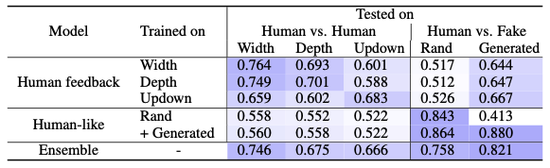
图7:数据对测评实验结果。
给定包含正例与负例的数据对,模型能否赋予正例更高的分值。Human vs。 Human: 正例负例均为人类回复,正例的相关指标更高。Human vs。 Fake:正例为该聊天场景下的人类回复,负例为随机选取的人类回复(Rand)或机器在该聊天场景下生成的回复(Generated)。
接下来,作者对模型生成与内容相关回复的能力进行测评。他将利用不同数据和任务训练的模型进行比较。结果如图7所示。左上的实验结果显示和前文三个指标的相关性研究结果一致。根据右上的实验结果,利用人类偏好信息训练的模型区分正例人类回复和随机抽取的人类回复的能力较弱,但是却可以更好的区分机器生成的结果。
这说明,尽管DialogGPT可以生成内容相关的类人回复,但并不能收获较多的人类反馈。结果也表明,类人和符合人类偏好这两个任务的目标间还存在着一定的差距,因此在最后一行,作者将两个任务融合在一起训练模型,最终获得在这两方面都取得出色的结果。这样,模型就可以在选择回复时同时权衡两个指标。
在聊天机器人说话越来越像人的今天,如何生成高质量的回复就成为了新的研究方向。本文提出的,回复获得反馈的激烈程度正是高质量的一种具体表现。该目标在许多应用方向上都很有价值。例如在人们寄予厚望的心理干预领域,聊天机器人不仅需要产生内容相符的回复,同样需要让对话者保持交流的意愿,同时引导他转变为积极的心理状态。















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









