







论文链接:https://arxiv.org/pdf/2103.02548.pdf
摘要
在这篇论文中,我们提出了一个中文多轮主题驱动对话数据集——NaturalConv,参与者可以自由聊天,只要话题中的任何一个元素被提及且话题转换平滑。我们的语料库包含来自六个领域的19.9K个对话和400K个话语,平均每轮对话有20.1个话语。这些对话包含了对相关话题的深入讨论,或者多个话题之间的自然过渡。我们认为这两种方式在人类对话中都是正常的。为了促进对该语料库的研究,我们提供了几个基准模型的结果。比较结果显示,在这个数据集上,通过引入背景知识/话题,我们目前的模型无法提供显著的改进。因此,我们提出的数据集应该是进一步研究、评估多轮对话系统的有效性和自然性的良好基准。我们的数据集可以在https://ai.tencent.com/ailab/nlp/dialogue/#datasets上获取。
引言
最近,由于大量对话数据的可用性和神经方法的最新进展(Huang、Zhu和Gao,2019),对开放领域对话系统的开发再次引起了人们的兴趣。然而,构建能够像人类一样在各种话题上进行对话的开放领域对话系统仍然极具挑战性,大多数当前的开放领域对话系统只擅长生成缺乏太多有意义信息的通用回复(Gao等,2019年)。
因此,越来越多的研究工作开始考虑如何整合各种信息以提高开放领域对话的质量。这些信息包括但不限于个性(Qian等,2018年)、常识(Zhou等,2018b年)、推理(Zhou、Huang和Zhu,2018年)、情感(Zhou等,2018a年)、以及与知识图谱相关的额外知识(Moon等,2019年;Wu等,2019年;Zhou等,2020年)等。尤其是,已经发布了各种基于知识/话题的对话语料库(Zhu等,2017年;Dinan等,2019年;Liu等,2018年;Moghe等,2018年;Zhou、Prabhumoye和Black,2018年;Moon等,2019年;Qin等,2019年;Tuan、Chen和Lee,2019年;Wu等,2019年;Zhou等,2020年),以展示生成与话题相关的信息性回复的尝试。
知识/话题驱动的对话是一种新型对话形式。一方面,与开放领域对话不同,它涉及一些需要在生成回复过程中使用额外知识的特定话题。另一方面,它还与话题有各种间接信息相关,例如闲聊、讲笑话、表达个人经验等。因此,我们认为这种话题驱动的对话在自然性和流行度方面比开放领域对话更接近人类对话。
然而,我们发现当前可用的基于话题的对话语料库存在两个共同的缺点:一是几乎所有提到的工作都要求参与者只能在给定的话题范围内进行对话,并假设参与者通过阅读提供的文档或知识图谱熟悉该话题。但在现实生活中,如果人们非常熟悉某个话题,他们可以轻松扩展该话题,如果对话伙伴开始一个不熟悉的话题,他们也可以轻松转换到其他话题。另一个缺点是大多数先前的工作鼓励注释者在开始对话后直接谈论话题。有的工作(Moghe等,2018年)甚至明确禁止在注释阶段进行闲聊。然而,现实情况恰恰相反。人们在开始任何正式或非正式的对话之前总是会打招呼。
为了克服这些问题,我们提出了NaturalConv,这是一个面向多轮主题驱动对话的中文对话数据集,并带有情景信息。它非常适合对多轮自然人类对话中的主题交互进行建模。与先前的语料库相同的是,所提出的数据集也是基于主题的,并由注释者根据给定的新闻文章以一定的话题为基础进行对话。但最大的不同特点如下:首先,对话不一定只限于新闻文章中的内容,只要提及了新闻文章中的任何信息,并且话题之间的过渡自然,参与者可以自由地谈论任何他们想谈论的内容;其次,我们要求两个参与者为他们的对话设定一个情景。这意味着注释者像扮演角色一样进行对话任务。只要对话遵循正常逻辑,他们可以假设对话发生在任何情景中;第三,我们允许对话中包含闲聊/问候。表1展示了一个例子。顶部是两个参与者都可以访问的新闻文章。从对话中,我们可以猜测这个对话发生在两个学生在早上第一节课前。其次,我们发现在20个话语中,只有2个(A4、A-5)明确提到了新闻的具体信息。其他话语包括闲聊(A-1、B-1)、关于情景的查询/回复(A-9、B-9、A-10、B-10)以及与话题相关的个人经验(A-7、A-8、B-8)等。但我们可以观察到整个对话比大多数先前的多轮对话更自然、更接近人类对话,而先前的对话更像是问答式的信息交流。通过上述显著不同的特点,我们还发现将文档/知识纳入对话生成过程并不是一件容易的事情。我们在论文的方法部分讨论了如何将文档/知识纳入对话生成的方法,但在我们的数据集上并没有带来显著的性能提升。
总之,本文的贡献如下:
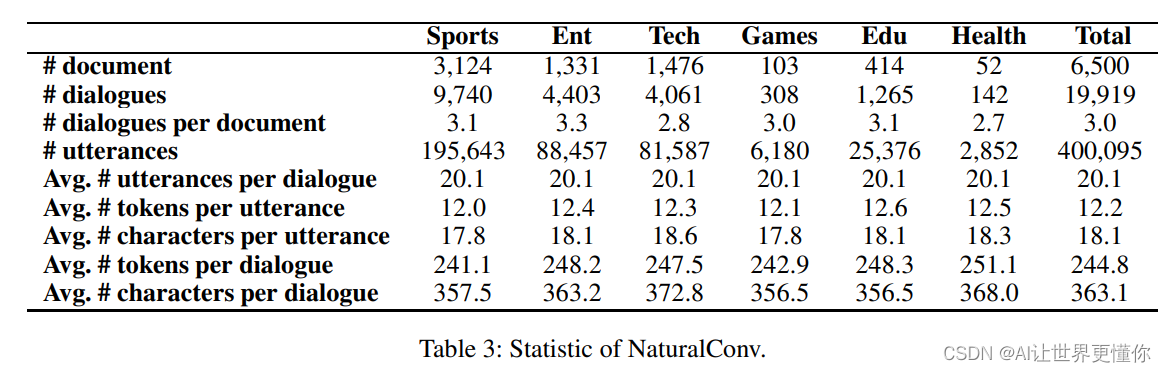
• 我们收集了一个新的数据集NaturalConv,基于中文的主题驱动对话生成。它更接近于具有自然属性的人类对话,包括完整而自然的设置,例如情景假设、自由话题扩展、问候等。它包含约400K个话语和19.9K个多领域对话(包括但不限于体育、娱乐和技术)。平均对话轮数为20,明显长于其他语料库中的对话轮数。
• NaturalConv提供了一个用于评估在自然环境中生成对话能力的基准。该语料库可以为未来的研究提供支持,不仅可以进行基于文档的对话生成,还可以从不同情景中学习对话风格和策略。
• 我们还在该语料库上进行了广泛的实验,以促进未来的研究。结果表明,在我们的数据集上,将文档知识纳入对话生成过程仍然非常具有挑战性。我们仍然需要深入的研究工作来改进系统,以处理这种自然而生动的对话。
2. 相关工作
随着越来越多的对话数据可用以及巨大的计算资源的可用性,基于神经网络的开放领域对话生成近年来取得了很大的进展(Adiwardana等,2020年;Roller等,2020年)。然而,大多数针对开放领域对话系统开发的神经响应生成模型并没有与现实世界联系起来,这使得这些系统无法有效地进行有意义的对话。知识基础对于系统提供实用的回复至关重要。否则,系统会倾向于提供平淡和重复的回复。
为了加快知识驱动对话的研究,提出了几个知识驱动的语料库。一些语料库(Ghazvininejad等,2018年;Liu等,2018年;Tuan、Chen和Lee,2019年;Qin等,2019年)通过自动方法(如NER和字符串匹配)获取知识。而更多的语料库(Zhou、Prabhumoye和Black,2018年;Dinan等,2019年;Gopalakrishnan等,2019年;Moon等,2019年;Wu等,2019年;Zhou等,2020年)在注释过程中从注释者那里收集知识。这些语料库之间也存在差异。从参与者是否可以访问知识的角度来看,Dinan等(2019年)假设一个注释者是可以访问维基百科资源的专业人士,而另一个注释者是一个寻求信息并对该主题一无所知的学徒。另一方面,Moon等(2019年)、Wu等(2019年)和Zhou等(2020年)允许所有注释者访问知识。Zhou等(2018年)、Dinan等(2019年)和Gopalakrishnan等(2019年)提供的知识是非结构化的纯文本,而Moon等(2019年)、Wu等(2019年)和Zhou等(2020年)提供了结构化的知识图谱。Moon等(2019年)使用Freebase(Bast等,2014年)作为背景知识。
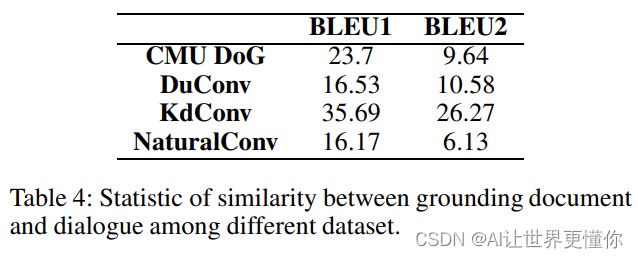
据我们所知,DuConv(Wu等,2019年)和KdConv(Zhou等,2020年)是目前唯一存在的两个中文人工标注的知识驱动对话数据集。DuConv利用非结构化文本(如短评论)和结构化知识图谱作为知识资源的组合。DuConv的一个局限性是它强烈假设对话必须在知识图谱内部从一个实体转移到另一个实体,而这在人类对话中并不总是成立。KdConv从多个资源构建其知识图谱。KdConv的一个缺陷是对话与提供的知识之间存在很高的重叠,这意味着注释者大量重复了知识图谱的内容,对话缺乏变化性。表2显示了与我们的数据集具有类似设置的语料库之间的统计信息。
3. 数据集
在这一部分,我们详细描述了NaturalConv数据集的创建过程。NaturalConv旨在收集一个基于多轮文档的对话数据集,具有情景和对话的自然属性。创建的对话预期包括三个关键点:有意义内容的对话、情景中的对话和自然的对话。接下来,我们将描述数据收集的设计过程。
对话收集
过滤文本:首先,我们认为只有有一个通用的话题,对话才能够具有有意义的聊天。因此,我们收集了很多新闻文档作为聊天背景。同时,我们为了避免内容太过专业,我们都是挑选了日常对话来了解每天都发生了什么。因此,我们挑选了2019年的6大类共计6500片新闻文档。而且,我们过滤了一些政治经济新闻由于敏感性,也删除了太短或者太长的新闻。
创建对话的背景文档:其次,我们通过阅读相关的新闻文档,让标注者进行一个多轮对话聊天。这一步中,我们的约束较少,不会出现一个显式的目标或者只能有一方获得咨询等。我们只有3个需求:
- 每位参与者必须说10句且必须提到新闻里的内容,哪怕是一丁点都行。
- 每次对话都必须发生在一个情景中。参与者可以根据自己的偏好选择情景,或者选择一个可以很容易引发初始话题的情景。
- 一旦参与者满足上述两个条件了,他们就可以自由的聊天了。
整个标注是外包给一个数据供应商了,大概花费5万块钱,但是我们也会人工检验对话的质量。同时,我们也没有要求任何句子级别的标注由于以下2个原因:
4. 在我们的语料库中,对话模式主要是口语化的,非常灵活,便于进行准确和高效的标注。
5. 在文档中的句子和对话中的话语之间没有明显的对应关系。然而,我们欢迎来自社区其他方面的额外标注。
数据集统计
下表是数据集的统计信息,并且我们还额外统计了3个指标,分别是:(1)文档和对话的相似程度,越低的相似程度显示出对话更加的自然且有信息量。(2)对话的多样性。我们选取了每个文档下3个对话进行了一个平均ROUGE值计算,越小则越显示出多样化。(3)人工检查自然度。我们随机挑选了100个会话进行了人工检验,我们的语料库自然性是2.8而其他两个数据集只有2.4和2.0。
方法
模型阶段,我们使用抽取和生成两种模型来进行评测。
抽取模型
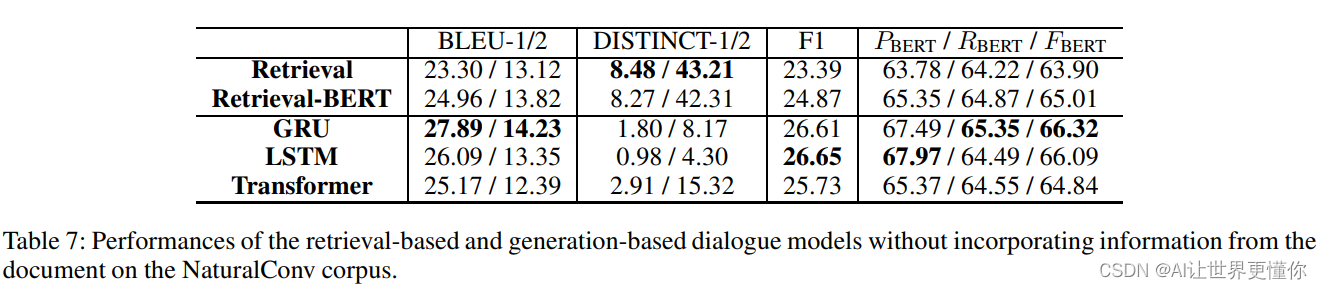
在给定对话上下文X的情况下,基于检索的对话系统通过从NaturalConv语料库中搜索最佳回复y来响应上下文。我们采用了一个信息检索模型,通过在检索语料库中找到最相似的查询,并将其回复作为结果。相似性是通过词袋之间的BM25指数进行衡量的。最近,基于BERT的检索对话模型(Whang等,2019)在对话系统中展现出了良好的性能。我们进一步将BERT模型纳入到BM25检索模型的输出重新排序中。这个Retrieval-BERT模型是在“bert-basechinese”骨干上进行微调,用于对训练数据进行序列分类,其中包括将地面真实回复标记为“1”,以及将BM25检索方法的前K-1个回复标记为“0”。在推理过程中,根据微调模型的序列分类得分,它重新对BM25检索方法给出的前K个回复进行排序。
生成模型
生成模型统一建模为Seq2Seq模型。
将文档信息纳入生成模型中
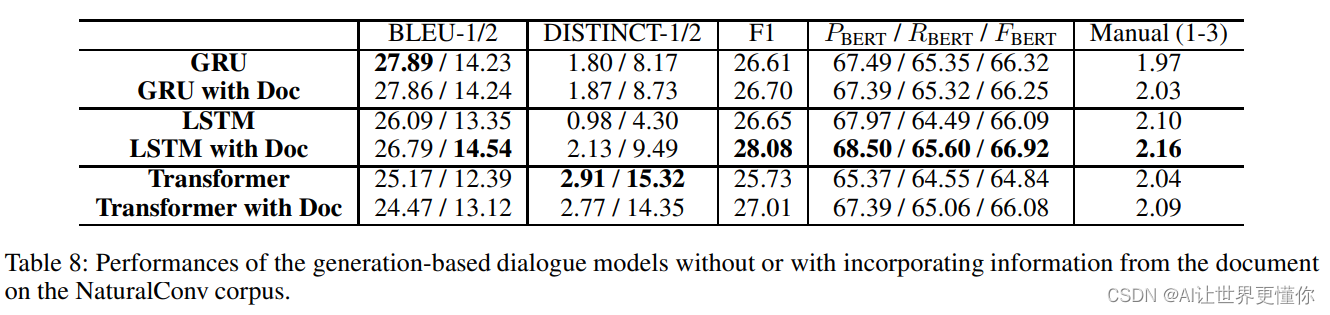
为了进一步将文档的基础信息纳入生成型模型中,我们将文档拆分为一个句子序列S={s1, s2,…, sm}。给定生成模型的对话上下文输入X={x1, x2,…, xk},其中包含k个上下文对话话语,我们从S中检索与最近的对话话语xk最相似的句子s∗。生成模型将以连接的(s∗, X)作为输入生成回复y。为了训练具有文档基础的模型,我们最小化损失函数L=PN i=1L i(Xi, y i, s i∗; θ),其中L i(Xi, y i, s i∗; θ)=−|y i X|t=1log P(y i t|Xi, s i∗, yi<t|θ)。我们将具有文档基础的模型实现为具有编码器-解码器结构的Seq2Seq模型。我们在GRU和LSTM模型中使用注意力机制,以确保文档信息s∗能够被纳入。Transformer编码器可以通过其自注意力机制将s∗纳入其中。我们将这些包含文档的生成模型称为“GRU with Doc”、“LSTM with Doc”和“Transformer with Doc”。
实验
实现细节
这里不赘述,看原文找细节。
评估准则
这里使用BLEU-1/2以及F1和DISTINCT-1/2和BERTScore进行评估。
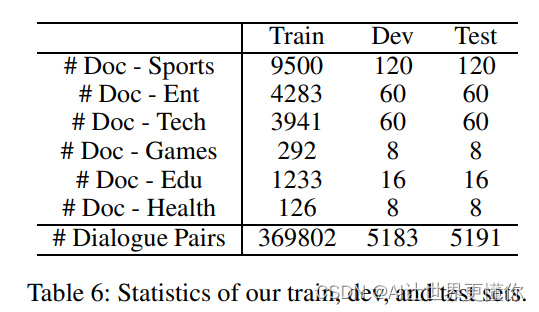
数据划分
实验结果
结论
本文提出了一个中文多轮主题驱动对话生成语料库,名为NaturalConv。它包含了40万个话语和1.99万个对话,平均每个对话有20.1轮。每个对话基于一个共享的主题,两个参与者可以自由地谈论任何事情,只要涉及到主题的某个具体方面即可。参与者还需要为对话设定一个情景。因此,对话包含了各种对话元素,如闲聊、关于主题的讨论、主题的可能延伸等等。我们相信这个数据集提供了一个很好的基准,用于评估模型建模主题驱动的自由风格对话的能力。此外,我们还提供了几个基准模型的结果,以促进进一步的研究。实验表明,通过引入文档知识,我们目前的模型无法提供显著的改进,因此在主题驱动对话建模方面还有很大的改进空间,需要进行进一步的研究。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











