






目录
- 项目背景
- 测试环境说明
- 各显卡测试结果
- 性能对比分析
- 结论与建议
一、项目背景
NVIDIA GeForce RTX 4090、RTX 5090 以及 NVIDIA A100 - PCIE - 40GB ,4090和5090是高端消费卡,A100是高性能显卡,都是市场上具有代表性的高端显卡,本次测试旨在通过科学的实验方法,对比这三款显卡在相同任务下的性能表现,在选择合适的计算硬件时提供参考依据。
二、测试环境说明
2.1 硬件环境
本次测试使用了三种不同型号的显卡,每种显卡均采用双卡配置,具体信息如下:
| 显卡型号 | 显存大小 | 数量 | 计算能力 | VMM 支持 |
| NVIDIA GeForce RTX 4090 | 24GB | 2 | 8.9 | 是 |
| NVIDIA GeForce RTX 5090 | 32GB | 2 | 12.0 | 是 |
| NVIDIA A100 - PCIE - 40GB | 40GB | 2 | 8.0 | 是 |
2.2 软件环境
- 操作系统:Linux 系统,具备稳定的计算环境和高效的资源管理能力。
- 计算后端:采用 CUDA 作为计算加速框架,充分发挥显卡的并行计算能力。
- 测试模型:使用 DeepSeek - R1 - Distill - Qwen - 14B - F16.gguf 模型,其具体参数为:
- 模型名称:qwen2 14B F16
- 模型大小:27.51 GiB
- 参数量:14.77 B
- 测试参数设置:
- 线程数:设置为 32 个线程,以平衡计算资源的利用和任务的并行处理能力。
- 批量大小:固定为 32768,确保在相同的数据处理规模下进行测试。
- 加载到 GPU 的层数(ngl):设置为 66 层,使模型的大部分计算任务在 GPU 上完成。
三、各显卡测试结果
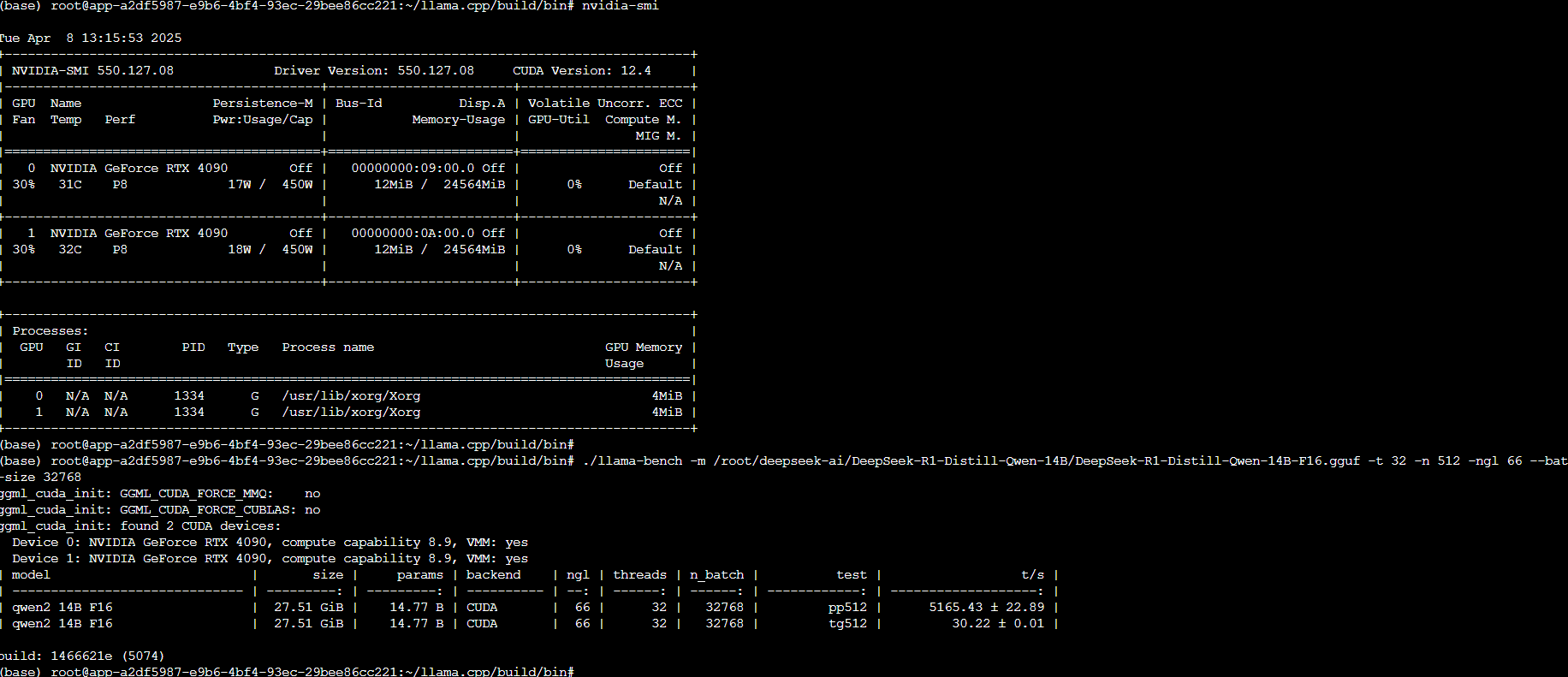
3.1 NVIDIA GeForce RTX 4090 测试结果
| model | size | params | backend | ngl | threads | n_batch | test | t/s |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | pp512 | 5165.43 ± 22.89 |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | tg512 | 30.22 ± 0.01 |
3.2 NVIDIA GeForce RTX 5090 测试结果
| model | size | params | backend | ngl | threads | n_batch | test | t/s |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | pp512 | 7173.34 ± 2.16 |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | tg512 | 45.52 ± 0.02 |
3.3 NVIDIA A100 - PCIE - 40GB 测试结果
| model | size | params | backend | ngl | threads | n_batch | test | t/s |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | pp512 | 4711.67 ± 8.35 |
| qwen2 14B F16 | 27.51 GiB | 14.77 B | CUDA | 66 | 32 | 32768 | tg512 | 37.57 ± 0.11 |
四、性能对比分析
4.1 pp512 测试对比
| 显卡型号 | 每秒处理速度(t/s) | 波动范围(±) | 相较于 4090 速度提升率 | 相较于 A100 速度提升率 |
| NVIDIA GeForce RTX 4090 | 5165.43 | 22.89 | - | - |
| NVIDIA GeForce RTX 5090 | 7173.34 | 2.16 | [(7173.34 - 5165.43)/ 5165.43]×100% ≈ 38.87% | [(7173.34 - 4711.67)/ 4711.67]×100% ≈ 52.24% |
| NVIDIA A100 - PCIE - 40GB | 4711.67 | 8.35 | - | - |
在 pp512 测试中,RTX 5090 的每秒处理速度优势明显。其速度达到 7173.34 t/s,远高于 RTX 4090 的 5165.43 t/s 和 A100 的 4711.67 t/s。与 RTX 4090 相比,速度提升约 38.87%;与 A100 相比,速度提升约 52.24%。而且,RTX 5090 的波动范围仅为 2.16,是三款显卡中最小的,说明其性能稳定性最佳。
4.2 tg512 测试对比
| 显卡型号 | 每秒处理速度(t/s) | 波动范围(±) | 相较于 4090 速度提升率 | 相较于 A100 速度提升率 |
| NVIDIA GeForce RTX 4090 | 30.22 | 0.01 | - | - |
| NVIDIA GeForce RTX 5090 | 45.52 | 0.02 | [(45.52 - 30.22)/ 30.22]×100% ≈ 50.63% | [(45.52 - 37.57)/ 37.57]×100% ≈ 21.16% |
| NVIDIA A100 - PCIE - 40GB | 37.57 | 0.11 | - | - |
在 tg512 测试中,RTX 5090 同样表现出色。其每秒处理速度为 45.52 t/s,领先于 RTX 4090 的 30.22 t/s 和 A100 的 37.57 t/s。相较于 RTX 4090,速度提升约 50.63%;相较于 A100,速度提升约 21.16%。虽然三款显卡的波动范围都较小,但 RTX 5090 的速度提升优势显著。
五、结论与建议
5.1 结论
综合 pp512 和 tg512 两项测试结果,NVIDIA GeForce RTX 5090 在性能上全面超越 NVIDIA GeForce RTX 4090 和 NVIDIA A100 - PCIE - 40GB。其较高的计算能力(12.0)使得在处理大规模模型时具有更高的效率,并且在性能稳定性方面表现突出,波动范围小,能够为计算任务提供持续稳定的支持。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









