







关键词
high-resolution高分辨率
non-saturating非饱和
a variant of的变体
make essential use of 基本使用
augment增强
fully-segmented 完全分割的
immense极大
compensate 补偿
depth and breadth深度和宽度
stationarity of statistics统计数据的平稳性
locality of pixel dependencies像素位置的依赖性
two GTX 580 3GB GPUs
ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)
validation验证集(不等于测试集)
customary习惯性地
pre-process预处理
delineation 轮廓图
solid line实线
Rectified Linear Units 修正线性单元
adjacent相邻的
arbitrary任意的
Local Response Normalization局部响应归一化
overlapping重叠的
overall全面的
inter-dependent相互依存
eigenvalues特征值
intensity强度
co-adaptations协同适应
subsets子集
momentum variable动态变量
dense稠密的
要点
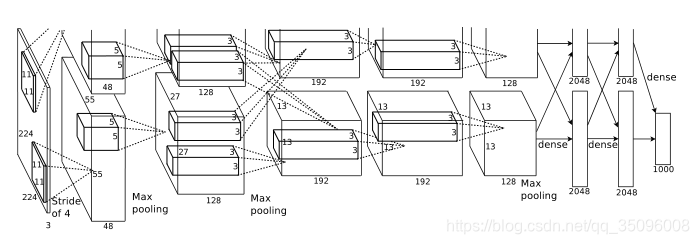
1 网路层数更深,识别率取得突破性进展,一些卷积层后面采用最大池化的操作,采用非饱和神经元,用GPU处理卷积操作速度更快,采用弃权的方法减缓过拟合,随机丢弃掉一部分神经元(实验证明这种方法很有效)
2 Alex认为gpu的速度,数据量的大小这两者在未来会逐步提高,训练的模型可以解决越来越复杂的问题
3 relu函数是非线性函数,相比于会饱和的tanh和sigmoid它的收敛速度更快,这使得它在大量数据训练的模型上表现的很好,这启示我们面面俱到不放过每一个数据不一定最好,较好的解决了梯度消失的问题
4 GPU具有高度并行化的特点,它们不需要经过主机可以彼此之间直接读写,使用两个GPU,一个放置一半的神经元,两个GPU只在一些层之间交流,这影响了交叉验证,却减小了计算量
5 局部响应归一化(LRN):对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。但是VGG模型的paper认为这个操作多此一举。。。
6 tanh函数和sigmoid函数需要归一化,这样做的目的是使它们在0附近工作以避免饱和,从它们的曲线函数就可以看出来了,而relu函数不需要,它的导数一直是1,不会出现梯度消失那些情况,所以relu甚至不需要归一化
7 池化操作时,之前一般让步长和池化单元格子长度相同,而这篇文章认为步长比格子长度小更好,这样池化出来的每个数据之间的关联性更强,或者说池化后的数据之间都有血缘关系。
8 正则化,弃权,增大数据集可以有效缓解过拟合,参数过多会导致过拟合,需要想办法让更多的参数趋近于0,正则化其实就是在损失函数后面加上参数向量的泛数,正则化并不会降低模型的表达力,相反它会使得更多的参数接近0,减少正则化














 2183
2183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









