







 本文介绍了二分搜索树,它也叫二叉查找树等,满足特定条件。其插入、删除、查询操作高效,平均时间复杂度为O(log n),最差为O(n)。还阐述了节点的插入、查找、遍历、删除等操作,最后说明了二分搜索树具有顺序性,但在时间性能上有局限性,可能退化成链表。
本文介绍了二分搜索树,它也叫二叉查找树等,满足特定条件。其插入、删除、查询操作高效,平均时间复杂度为O(log n),最差为O(n)。还阐述了节点的插入、查找、遍历、删除等操作,最后说明了二分搜索树具有顺序性,但在时间性能上有局限性,可能退化成链表。
二分搜索树
一、概念及其介绍
二分搜索树(英语:Binary Search Tree),也称为 二叉查找树 、二叉搜索树 、有序二叉树或排序二叉树。满足以下几个条件:
- 若它的左子树不为空,左子树上所有节点的值都小于它的根节点。
- 若它的右子树不为空,右子树上所有的节点的值都大于它的根节点。
它的左、右子树也都是二分搜索树。
如下图所示:

二、适用说明
二分搜索树有着高效的插入、删除、查询操作。
平均时间的时间复杂度为 O(log n),最差情况为 O(n)。二分搜索树与堆不同,不一定是完全二叉树,底层不容易直接用数组表示故采用链表来实现二分搜索树。
| 查找元素 | 插入元素 | 删除元素 | |
|---|---|---|---|
| 普通数组 | O(n) | O(n) | O(n) |
| 顺序数组 | O(logn) | O(n) | O(n) |
| 二分搜索树 | O(logn) | O(logn) | O(logn) |
下面先介绍数组形式的二分查找法作为思想的借鉴,后面继续介绍二分搜索树的查找方式。
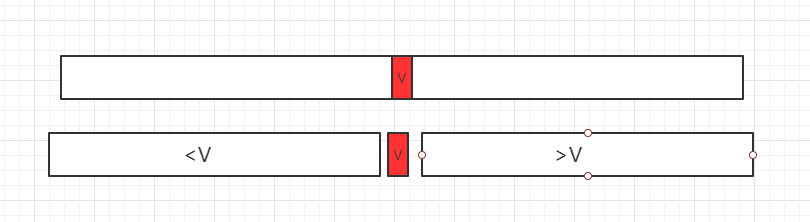
三、二分查找法过程图示
二分查找法的思想在 1946 年提出,查找问题是计算机中非常重要的基础问题,对于有序数列,才能使用二分查找法。如果我们要查找一元素,先看数组中间的值V和所需查找数据的大小关系,分三种情况:
- 1、等于所要查找的数据,直接找到
- 2、若小于 V,在小于 V 部分分组继续查询
- 2、若大于 V,在大于 V 部分分组继续查询
二分搜索树节点的插入
首先定义一个二分搜索树,Java 代码表示如下:
public class BST<Key extends Comparable<Key>, Value> {
// 树中的节点为私有的类, 外界不需要了解二分搜索树节点的具体实现
private class Node {
private Key key;
private Value value;
private Node left, right;
public Node(Key key, Value value) {
this.key = key;
this.value = value;
left = right = null;
}
}
// 根节点
private Node root;
// 树种的节点个数
private int count;
// 构造函数, 默认构造一棵空二分搜索树
public BST() {
root = null;
count = 0;
}
// 返回二分搜索树的节点个数
public int size() {
return count;
}
// 返回二分搜索树是否为空
public boolean isEmpty() {
return count == 0;
}
}Node 表示节点,count 代表节点的数量。
以下实例向如下二分搜索树中插入元素 61 的步骤:
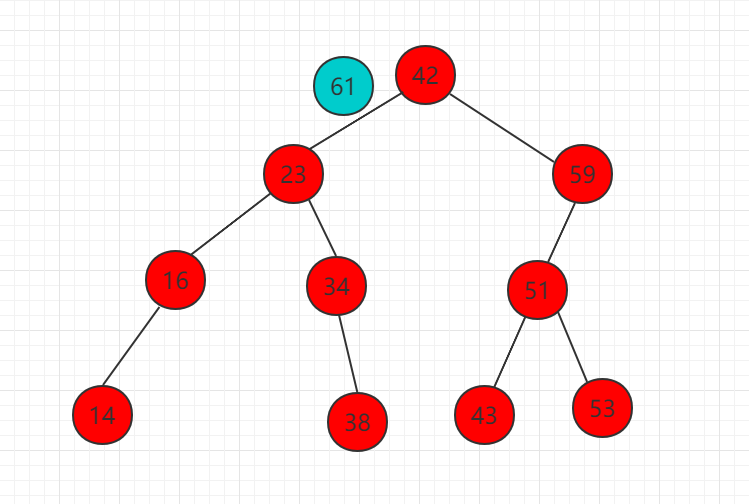
(1)需要插入的元素 61 比 42 大,比较 42 的右子树根节点。
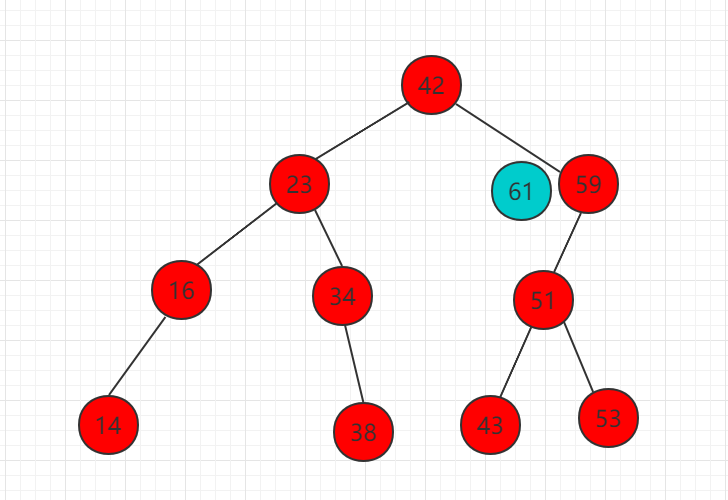
(2)61 比 59 大,所以需要把 61 移动到 59 右子树相应位置,而此时为空,直接插入作为 59 的右子节点。

插入操作也是一个递归过程,分三种情况,等于、大于、小于。
二分搜索树节点的查找
二分搜索树没有下标, 所以针对二分搜索树的查找操作, 这里定义一个 contain 方法, 判断二分搜索树是否包含某个元素, 返回一个布尔型变量, 这个查找的操作一样是一个递归的过程, 具体代码实现如下:
...
// 查看以node为根的二分搜索树中是否包含键值为key的节点, 使用递归算法
private boolean contain(Node node, Key key){
if( node == null )
return false;
if( key.compareTo(node.key) == 0 )
return true;
else if( key.compareTo(node.key) < 0 )
return contain( node.left , key );
else // key > node->key
return contain( node.right , key );
}
...以下实例在二分搜索树中寻找 43 元素
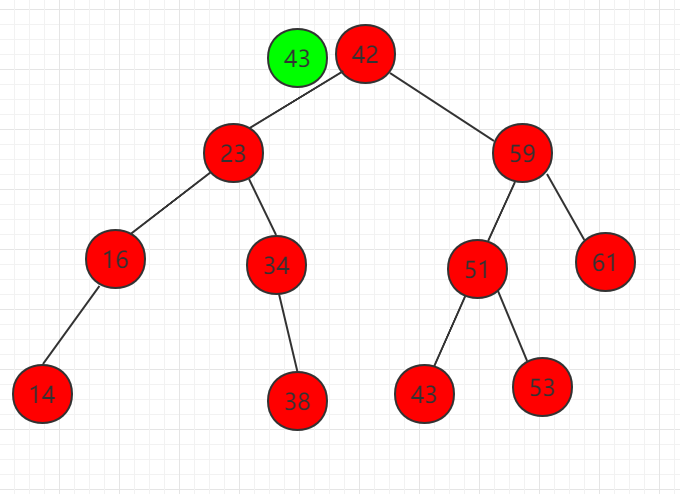
(1) 元素 43 比根节点 42 大,需要在右子节点继续比较。
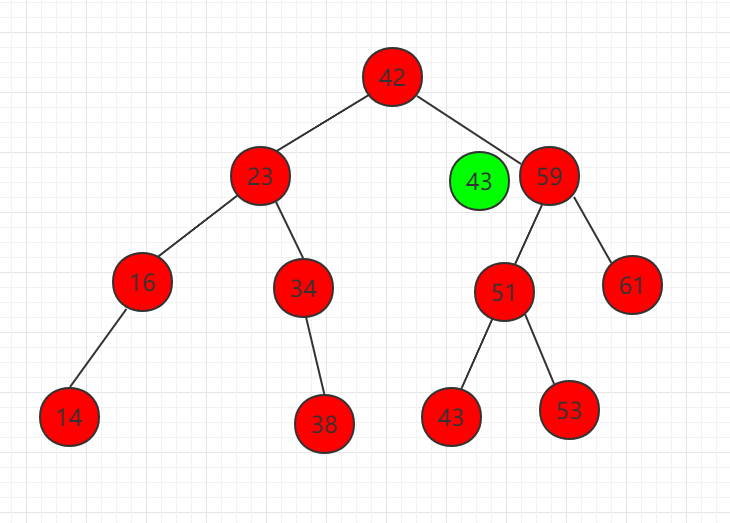
(2) 元素 43 比 59 小,需要在左子节点继续比较。
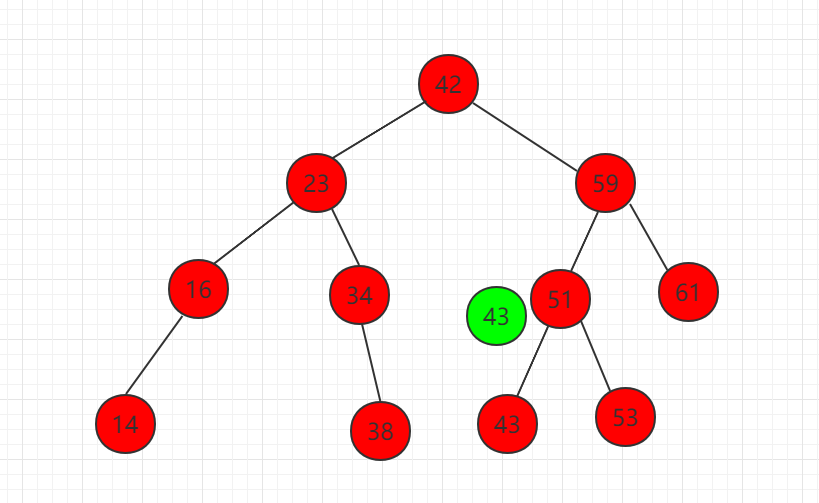
(3) 元素 43 比 51 小,需要在左子节点继续比较。
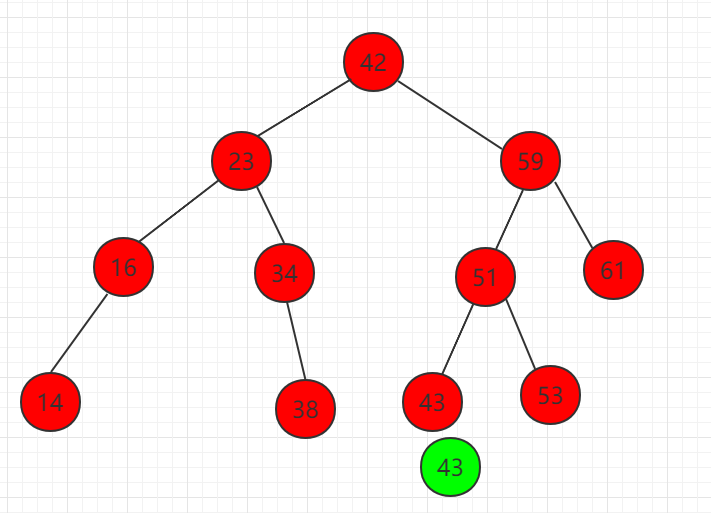
(4) 查找 51 的左子节点 43,正好和相等,结束。
如果需要查找 key 对应的 value,代码如下所示:
...
// 在以node为根的二分搜索树中查找key所对应的value, 递归算法
// 若value不存在, 则返回NULL
private Value search(Node node, Key key){
if( node == null )
return null;
if( key.compareTo(node.key) == 0 )
return node.value;
else if( key.compareTo(node.key) < 0 )
return search( node.left , key );
else // key > node->key
return search( node.right, key );
}
...二分搜索树深度优先遍历
二分搜索树遍历分为两大类,深度优先遍历和层序遍历。
深度优先遍历分为三种:先序遍历(preorder tree walk)、中序遍历(inorder tree walk)、后序遍历(postorder tree walk),分别为:
- 1、前序遍历:先访问当前节点,再依次递归访问左右子树。
- 2、中序遍历:先递归访问左子树,再访问自身,再递归访问右子树。
- 3、后序遍历:先递归访问左右子树,再访问自身节点。
前序遍历结果图示:
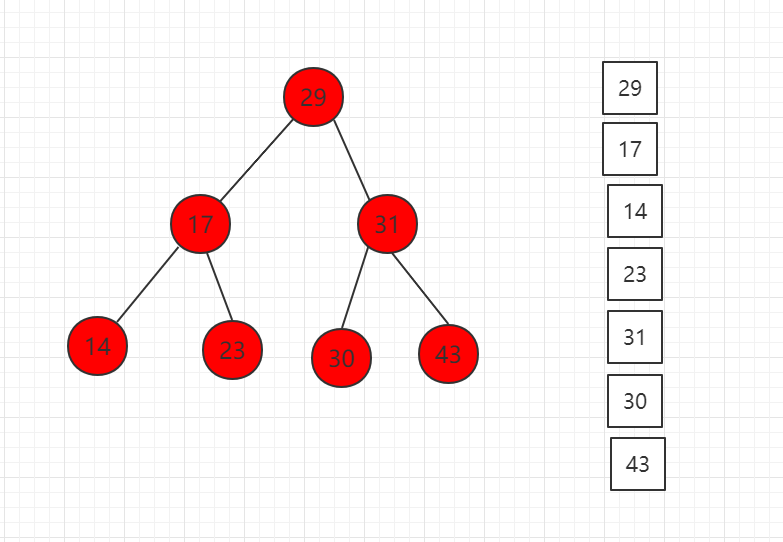
对应代码示例:
...
// 对以node为根的二叉搜索树进行前序遍历, 递归算法
private void preOrder(Node node){
if( node != null ){
System.out.println(node.key);
preOrder(node.left);
preOrder(node.right);
}
}
...中序遍历结果图示:
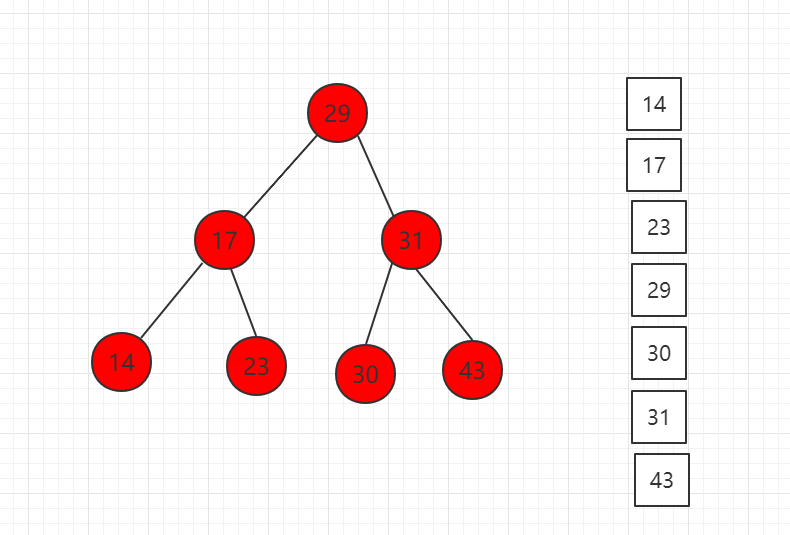
对应代码示例:
...
// 对以node为根的二叉搜索树进行中序遍历, 递归算法
private void inOrder(Node node){
if( node != null ){
inOrder(node.left);
System.out.println(node.key);
inOrder(node.right);
}
}
...后序遍历结果图示:

对应代码示例:
...
// 对以node为根的二叉搜索树进行后序遍历, 递归算法
private void postOrder(Node node){
if( node != null ){
postOrder(node.left);
postOrder(node.right);
System.out.println(node.key);
}
}
...二分搜索树层序遍历
二分搜索树的层序遍历,即逐层进行遍历,即将每层的节点存在队列当中,然后进行出队(取出节点)和入队(存入下一层的节点)的操作,以此达到遍历的目的。
通过引入一个队列来支撑层序遍历:
-
如果根节点为空,无可遍历;
-
如果根节点不为空:
-
先将根节点入队;
-
只要队列不为空:
- 出队队首节点,并遍历;
- 如果队首节点有左孩子,将左孩子入队;
- 如果队首节点有右孩子,将右孩子入队;
-
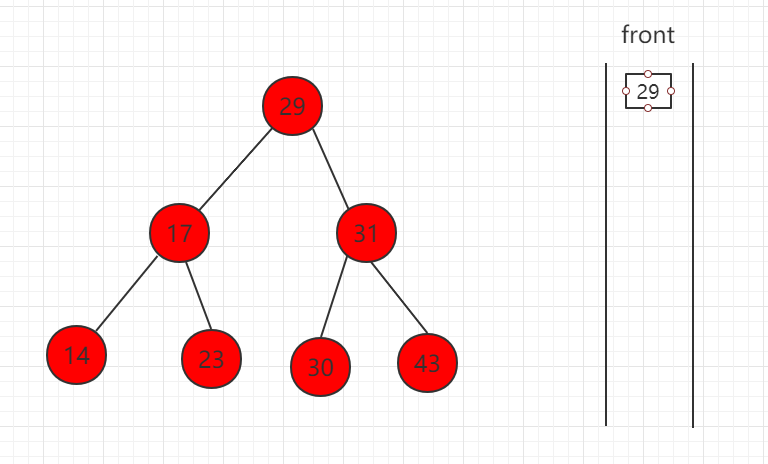
下面依次演示如下步骤:
(1)先取出根节点放入队列
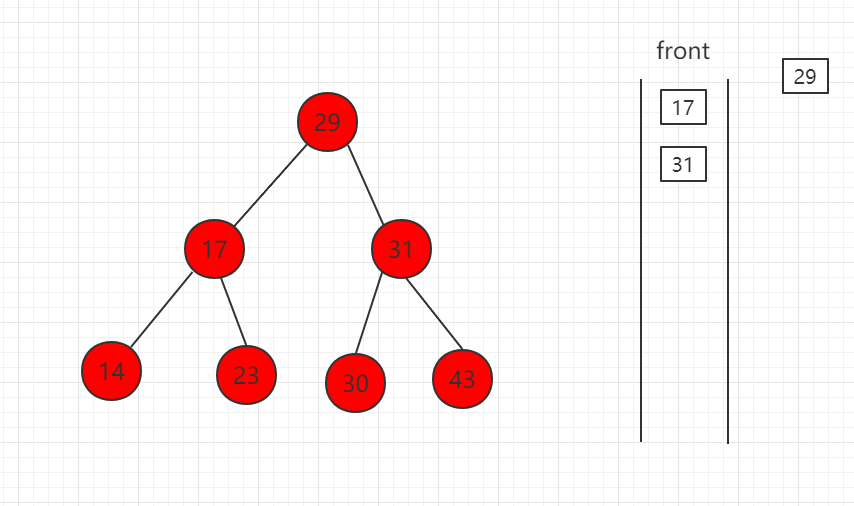
(2)取出 29,左右孩子节点入队
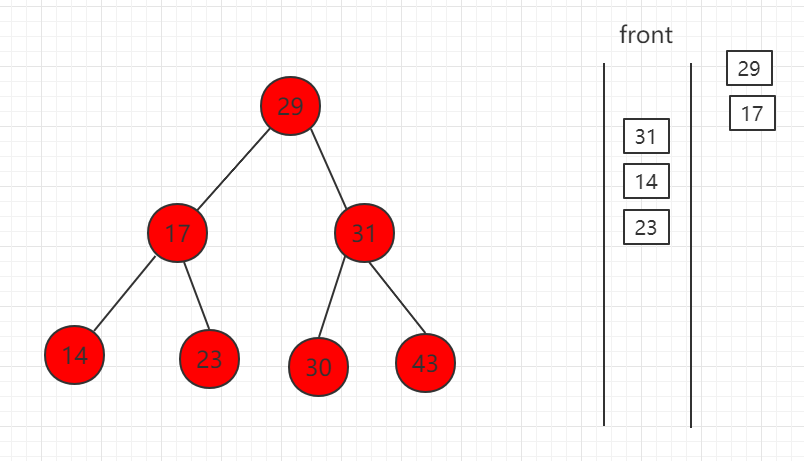
(3)队首 17 出队,孩子节点 14、23 入队。
(4)31 出队,孩子节点 30 和 43 入队
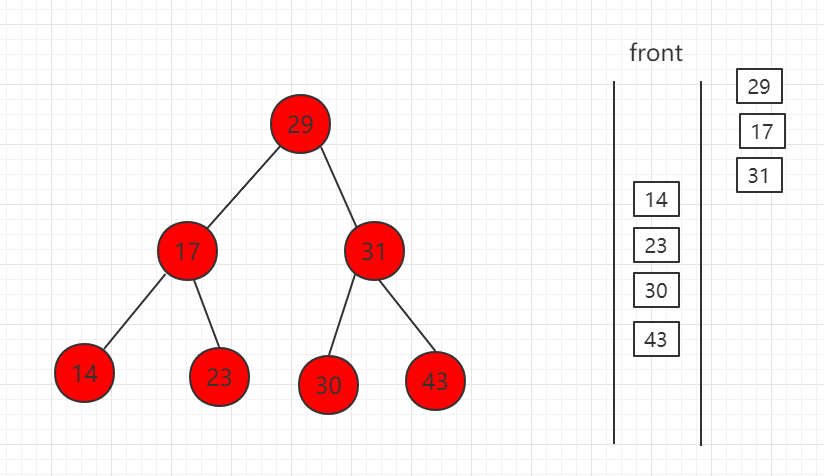
(5)最后全部出队
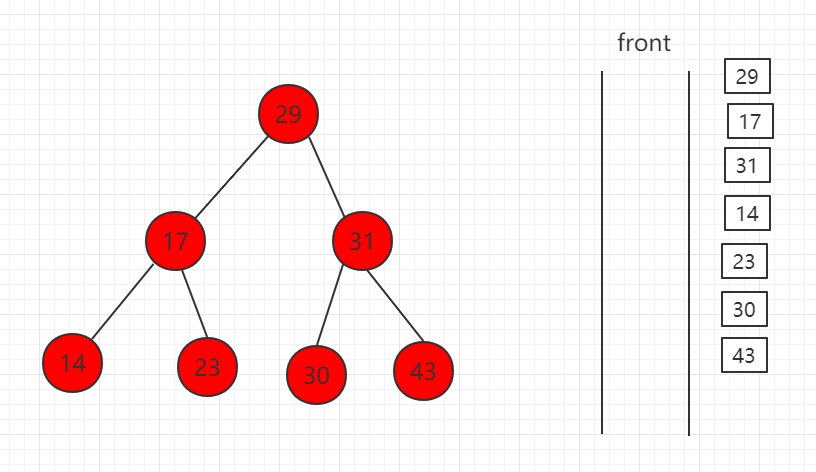
核心代码示例:
...
// 二分搜索树的层序遍历
public void levelOrder(){
// 我们使用LinkedList来作为我们的队列
LinkedList<Node> q = new LinkedList<Node>();
q.add(root);
while( !q.isEmpty() ){
Node node = q.remove();
System.out.println(node.key);
if( node.left != null )
q.add( node.left );
if( node.right != null )
q.add( node.right );
}
}
...二分搜索树节点删除
本小节介绍二分搜索树节点的删除之前,先介绍如何查找最小值和最大值,以及删除最小值和最大值。
以最小值为例(最大值同理):
查找最小 key 值代码逻辑,往左子节点递归查找下去:
...
// 返回以node为根的二分搜索树的最小键值所在的节点
private Node minimum(Node node){
if( node.left == null )
return node;
return minimum(node.left);
}
...删除二分搜索树的最小 key 值,如果该节点没有右子树,那么直接删除,如果存在右子树,如图所示:
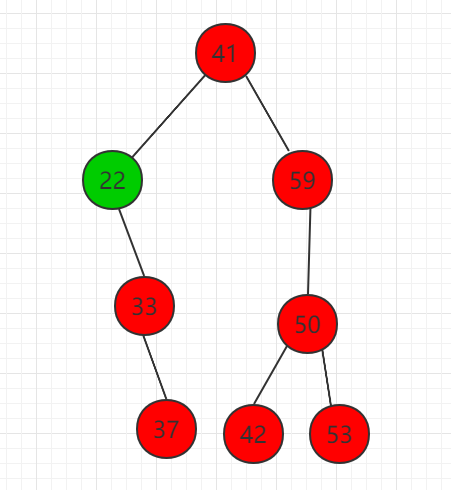
删除节点 22,存在右孩子,只需要将右子树 33 节点代替节点 22。
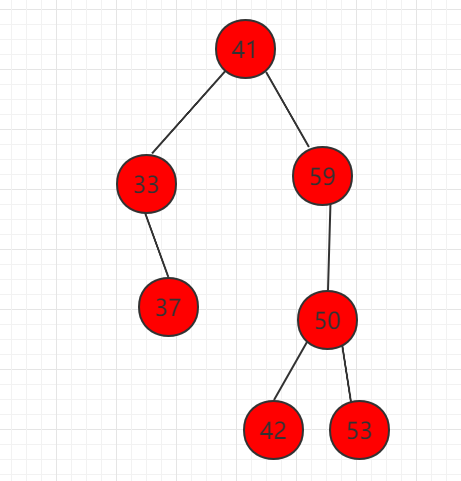
这个删除最小值用代码表示:
...
// 删除掉以node为根的二分搜索树中的最小节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node){
if( node.left == null ){
Node rightNode = node.right;
node.right = null;
count --;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
...现在讨论二分搜索树节点删除分以下三种情况:
1、删除只有左孩子的节点,如下图节点 58。
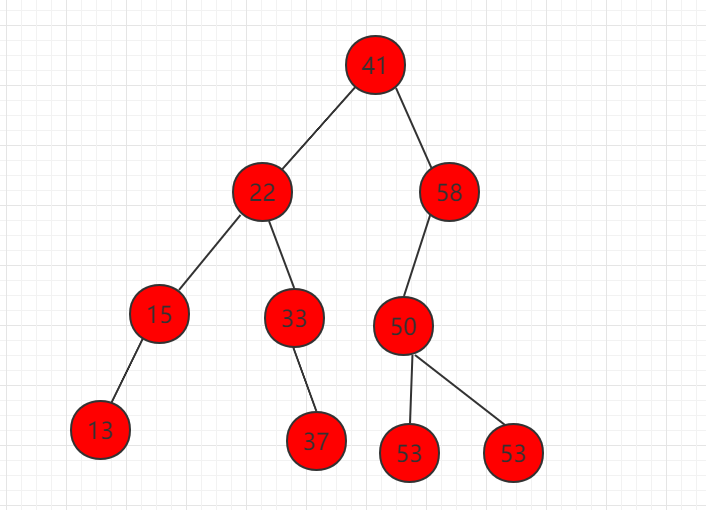
删除掉元素 58,让左子树直接代替 58 的位置,整个二分搜索树的性质不变。
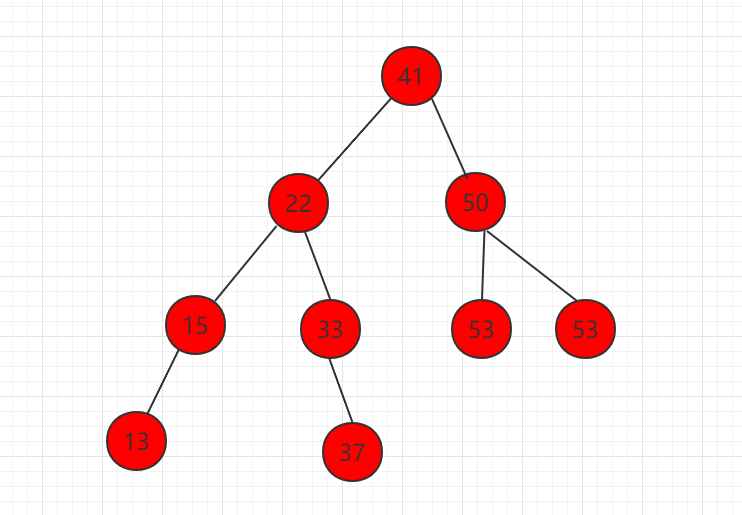
2、删除只有右孩子的节点,如下图节点 58。
删除掉元素 58,让右子树直接代替 58 的位置,整个二分搜索树的性质不变。
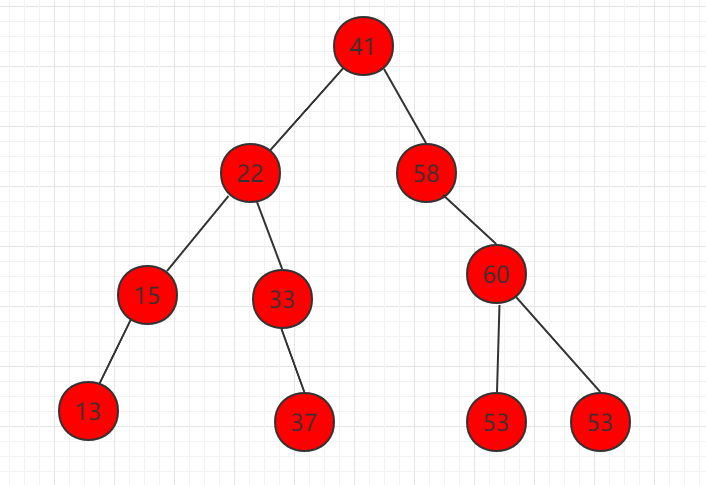
3、删除左右都有孩子的节点,如下图节点 58。
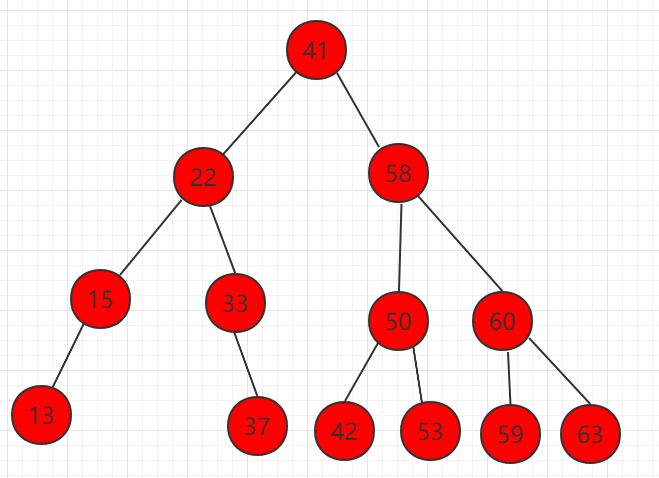
(1)找到右子树中的最小值,为节点 59
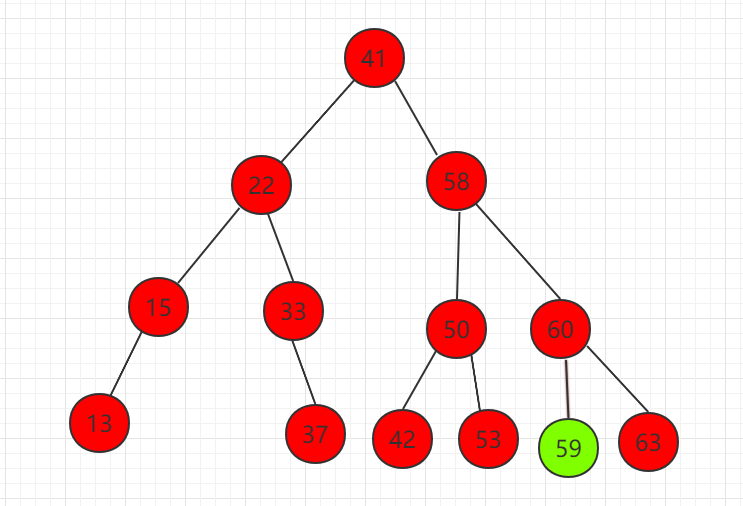
(2)节点 59 代替待删除节点 58
二分搜索树的特性
一、顺序性
二分搜索树可以当做查找表的一种实现。
我们使用二分搜索树的目的是通过查找 key 马上得到 value。minimum、maximum、successor(后继)、predecessor(前驱)、floor(地板)、ceil(天花板、rank(排名第几的元素)、select(排名第n的元素是谁)这些都是二分搜索树顺序性的表现。
二、局限性
二分搜索树在时间性能上是具有局限性的。
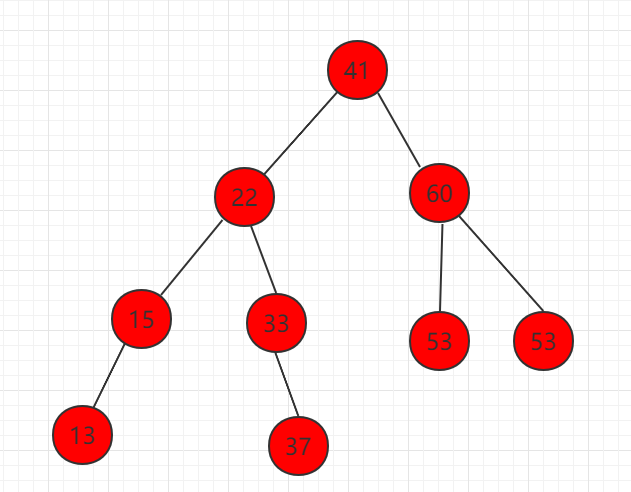
如下图所示,元素节点一样,组成两种不同的二分搜索树,都是满足定义的:
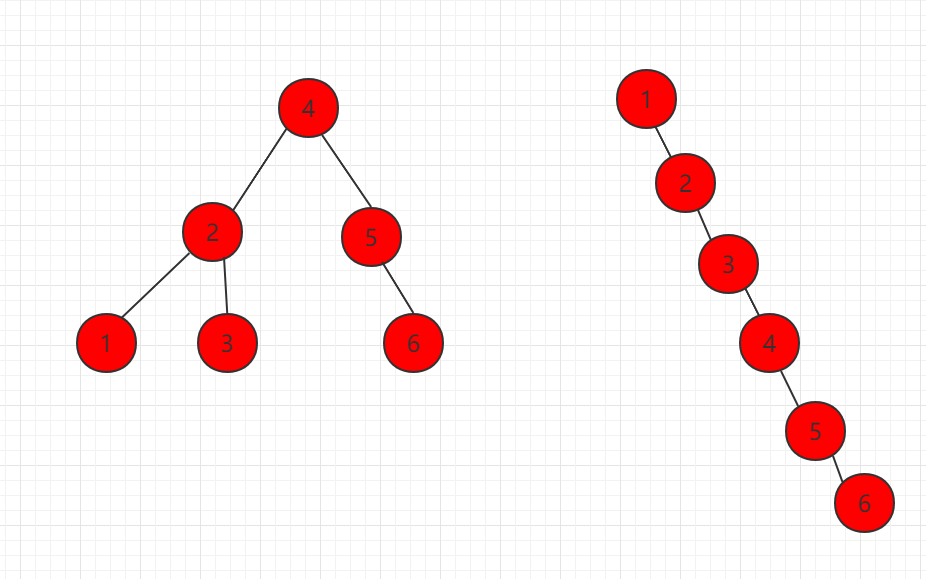
二叉搜索树可能退化成链表,相应的,二叉搜索树的查找操作是和这棵树的高度相关的,而此时这颗树的高度就是这颗树的节点数 n,同时二叉搜索树相应的算法全部退化成 O(n) 级别。


















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











