







高级IO
在介绍select之前呢,我们先需要先了解一下IO。
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
- 第一阶段:等待数据准备 (Waiting for the data to be ready)。
- 第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
对于socket流而言,
- 第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
- 第二步:把数据从内核缓冲区复制到应用进程缓冲区。
网络应用需要处理的无非就是两大类问题,网络IO,数据计算。相对于后者,网络IO的延迟,给应用带来的性能瓶颈大于后者。网络IO的模型大致有如下几种:
- 同步模型(synchronous IO)
- 阻塞IO(bloking IO)
- 非阻塞IO(non-blocking IO)
- 多路复用IO(multiplexing IO)
- 信号驱动式IO(signal-driven IO)
- 异步IO(asynchronous IO)
阻塞IO
同步阻塞 IO 模型是最常用的一个模型,也是最简单的模型。在linux中,默认情况下所有的socket都是blocking。它符合人们最常见的思考逻辑。阻塞就是进程 "被" 休息, CPU处理其它进程去了。
在这个IO模型中,用户空间的应用程序执行一个系统调用(recvform),这会导致应用程序阻塞,什么也不干,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络IO。调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。
非阻塞IO
同步非阻塞就是 “每隔一会儿瞄一眼进度条” 的轮询(polling)方式。在这种模型中,设备是以非阻塞的形式打开的。这意味着 IO 操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK)。
在网络IO时候,非阻塞IO也会进行recvform系统调用,检查数据是否准备好,与阻塞IO不一样,”非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 ‘被’ CPU光顾”。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。
注:阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回!
多路复用IO
由于同步非阻塞方式需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间,而 “后台” 可能有多个任务在同时进行,人们就想到了循环查询多个任务的完成状态,只要有任何一个任务完成,就去处理它。如果轮询不是进程的用户态,而是有人帮忙就好了。那么这就是所谓的 “IO 多路复用”。UNIX/Linux 下的 select、poll、epoll 就是干这个的(epoll 比 poll、select 效率高,做的事情是一样的)。
IO多路复用有两个特别的系统调用select、poll、epoll函数。select调用是内核级别的,select轮询相对非阻塞的轮询的区别在于—前者可以等待多个socket,能实现同时对多个IO端口进行监听,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,当然这个过程是阻塞的。select或poll调用之后,会阻塞进程,与blocking IO阻塞不同在于,此时的select不是等到socket数据全部到达再处理, 而是有了一部分数据就会调用用户进程来处理。如何知道有一部分数据到达了呢?监视的事情交给了内核,内核负责数据到达的处理。也可以理解为"非阻塞"吧。
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时(注意不是全部数据可读或可写),才真正调用I/O操作函数。
信号驱动式IO
信号驱动式I/O:首先我们允许Socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
异步IO
简介:数据拷贝的时候进程无需阻塞
相对于同步IO,异步IO不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。IO两个阶段,进程都是非阻塞的。
五种IO模型的比较
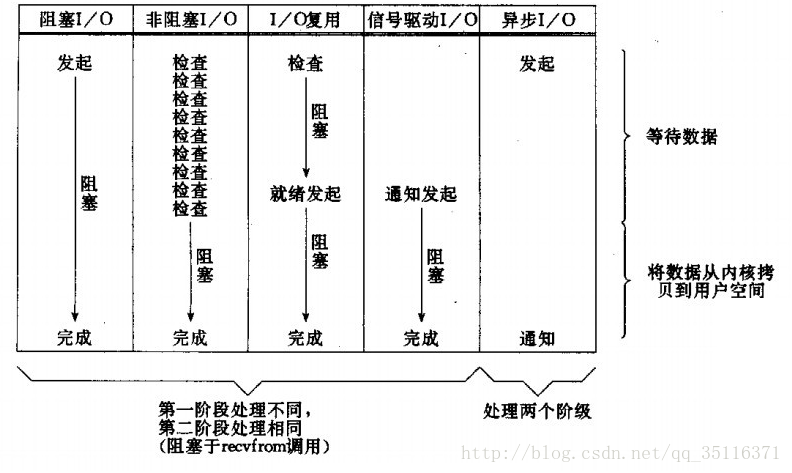
在了解了IO之后我们现在再去仔细了解一下其中的多路转接IO,下面我介绍的是多路转接中的select。
IO多路转接之select
系统提供select函数来实现多路复用输入/输出模型。select系统调用是用来让我们的程序监视多个文件句柄的状态变化的。 程序会停在select这里等待,直到被监视的文件句柄有一个或多个发生了状态改变。 关于文件句柄,其实就是一个整数,我们最熟悉的句柄是0、1、2三个,0是标准输入,1是标准输出,2是标准错误输出。0、1、2是整数示的,对应的FILE *结构的表示就是stdin、stdout、stderr。
select函数
讲到了这个select,那么我们就不得不提到必用的这个select函数了。
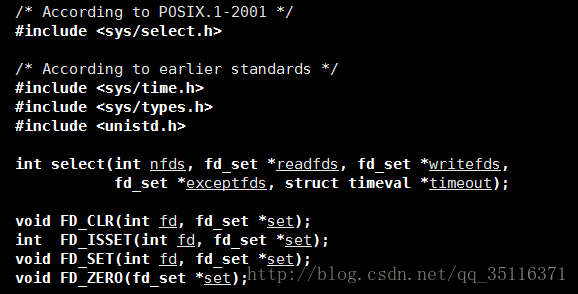
参数意义:
1.nfds:表示最大文件描述符+1,用来表示文件描述符的范围。
这个参数有什么用呢?系统迫使我们计算文件描述符的最大值,所为的不过是效率问题,我们在上面分析过,调用select需要不断拷贝转移描述符集fd_set,当数量庞大时,会是一个很大的负担,利用这个最大值就可以避免复制一些并不存在的描述符。
2.readfds:表示指向读文件描述符集的指针
3.writefds:表示指向写文件描述符集的指针
4.execptfds:表示指向错误输出文件描述符集的指针。
参数readfds,writefds,execptfds既是输入参数,又是输出参数。
输入:将要监控的文件描述符传给select
输出:将处于就绪状态的文件描述符返回。 (所以要在每次处理完一就绪事件后要将readfds,writefds,execptfd三个参数重置)
5.timeout:表示超时时间限制。(有三种情况)
timeout也是一种输入输出两用参数,输入表示设定超时时间,输出表示超时时间还剩多少。
timeout是一个timeval结构体类型的指针。
timeval结构如下:

我们可以通过设置上面结构体内两个元素的值来设定select的超时时间。
上面的图中我们还看到了好几个函数,都是以FD开头的函数,它们是干嘛的呢?
void FD_CLR(int fd, fd_set *set);将文件描述符中的fd位去掉
int FD_ISSET(int fd, fd_set *set);检测文件描述符集set中的fd位是否存在
void FD_SET(int fd, fd_set *set);为set文件描述符集设置fd为设置
void FD_ZERO(fd_set *set);将set文件描述符集清空
返回值
select的返回值有三种:
-1 —– 执行错误
0 —– timeout时间到达
其他 —– 正确执行,并且有就绪事件到达。
代码实现
准备工作:
①我们需要定义一个数组来保存所有的文件描述符 ——- int fds[];(如果三种文件描述符都考虑,则设立三个数组)
原因:因为readfds,writefds,execptfds 每次调用select函数,这三个参数的值都会变化,为了保证下次调用select能够正常执行,我们需要利用这个数组来重置这些参数。
② 定义一个值来保存文件描述符的最大值 —– int max_fd; —– 方便我们传参。
服务器端:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<arpa/inet.h>
#include<sys/time.h>
#include<unistd.h>
#include<string.h>
#define SIZE sizeof(fd_set)*8
int readfds[SIZE];//保存所有文件描述符的数组
void usage(const char* proc)
{
printf("Usage:%s [local_ip] [local_port]\n");
}
int startup(const char* ip, int port)
{
int sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock < 0)
{
perror("socket");
return 2;
}
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = inet_addr(ip);
if(bind(sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
perror("bind");
return 3;
}
if(listen(sock, 5) < 0)
{
perror("listen");
return 4;
}
return sock;
}
int main(int argc, char* argv[])
{
if(argc != 3)
{
usage(argv[0]);
return 1;
}
int sock = startup(argv[1], atoi(argv[2]));
int i = 0;
for(; i < SIZE; ++i)
{
readfds[i] = -1;//全部初始化为-1
}
readfds[0] = sock;
int max_fd = readfds[0];//保存最大的文件描述符用作select函数参数
while(1)
{
fd_set rfds, wfds;
char buf[1024];
FD_ZERO(&rfds);//将文件描述符集指针指向的文件描述符集清零
int j = 0;
for(; j < SIZE; ++j)
{
if(readfds[j] != -1)
{
FD_SET(readfds[j], &rfds);//将文件描述符设置进文件描述符集指针指向的文件描述符集中
}
if(max_fd < readfds[j])
{
max_fd = readfds[j];
}
}
struct timeval timeout = {5, 0};
switch(select(max_fd+1, &rfds, &wfds, NULL, &timeout))
{
case -1:
{
perror("select");
break;
}
case 0:
{
printf("timeout...\n");
break;
}
default:
{
int k = 0;
for(; k < SIZE; ++k)
{
if(readfds[k] == sock && FD_ISSET(readfds[k], &rfds))//FD_ISSET用来判断文件描述符是否在文件描述符集中,是返回1,否返回0
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newsock = accept(sock, (struct sockaddr*)&peer, &len);
if(newsock < 0)
{
perror("accept");
continue;
}
int l = 0;
for(; l < SIZE; ++l)
{
if(readfds[l] == -1)
{
readfds[l] = newsock;
break;
}
}
if(l == SIZE)
{
printf("readfds is full\n");
return 5;
}
}
else if(readfds[k] > 0 && FD_ISSET(readfds[k], &rfds))
{
ssize_t s = read(readfds[k], buf, sizeof(buf)-1);
if(s < 0)
{
perror("read");
return 6;
}
else if(s == 0)
{
printf("client quit\n");
readfds[k] = -1;
close(readfds[k]);
continue;
}
else
{
buf[s] = 0;
printf("client # %s\n", buf);
fflush(stdout);
write(readfds[k], buf, strlen(buf));
}
}
}
}
break;
}
}
close(sock);
return 0;
}
客户端:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<string.h>
#include<unistd.h>
void usage(const char* proc)
{
printf("Usage: %s [local_ip] [local_port]\n");
}
int main(int argc, char* argv[])
{
if(argc != 3)
{
usage(argv[0]);
return 1;
}
int sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock < 0)
{
perror("socket");
return 2;
}
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(atoi(argv[2]));
local.sin_addr.s_addr = inet_addr(argv[1]);
if(connect(sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
perror("connect");
return 3;
}
printf("connect success\n");
char buf[1024];
while(1)
{
printf("client # ");
fflush(stdout);
ssize_t s = read(0, buf, sizeof(buf)-1);
if(s <= 0)
{
perror("read");
return 4;
}
else
{
buf[s-1] = 0;
int fd = dup(1);
dup2(sock, 1);
printf("%s", buf);
fflush(stdout);
dup2(fd, 1);
}
s = read(sock, buf, sizeof(buf)-1);
if(s == 0)
{
printf("server quit\n");
break;
}
else if(s < 0)
{
perror("read");
return 5;
}
else
{
buf[s] = 0;
printf("server # %s\n", buf);
}
}
close(sock);
return 0;
}
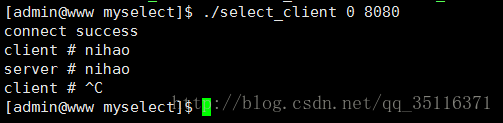
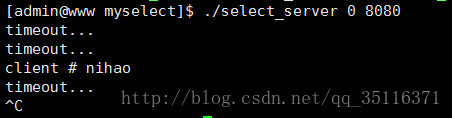
在客户端没有发送数据时就会显示超时,当客户端发送数据时,服务端就会收到客户端发来的数据并显示。
总结select服务器的优缺点
优点:
1、不需要建立多个线程、进程就可以实现一对多的通信。
2、可以同时等待多个文件描述符,效率比起多进程多线程来说要高很多
select高效的原因
首先要知道一个概念,一次I/O分两个部分(①等待数据就绪 ②进行I/O),减少等的比重,增加I/O的比重就可以达到高效服务器的目的。select工作原理就是这个,同时监控多个文件描述符(或者说文件句柄),一旦其中某一个进入就绪状态,就进行I/O操作。监控多个文件句柄可以达到提高就绪状态出现的概率,就可以使CPU在大多数时间下都处于忙碌状态,大大提高CPU的性能。达到高效服务器的目的。 可以理解为select轮询监控多个文件句柄或套接字。
缺点:
1、每次进行select都要把文件描述符集fd由用户态拷贝到内核态,这样的开销会很大。
2、实现select服务器,内部要不断对文件描述符集fd进行循环遍历,当fd很多时,开销也很大。
3、select能监控文件描述符的数量有限,一般为1024。(sizeof(fd_set) * 8 = 1024(fd_set内部是以位图表示文件描述符))















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









