







本文参考:
1)机器学习.周志华
2)
https://www.zybuluo.com/hanbingtao/note/448086
https://www.zybuluo.com/hanbingtao/note/433855
https://www.zybuluo.com/hanbingtao/note/476663
3)li_wen01 https://blog.csdn.net/li_wen01/article/details/73222657
4)rookie_wei https://blog.csdn.net/rookie_wei/article/details/80530514#commentBox
================================================================================================
神经元模型
神经网络是具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。


神经网络中最基本的成分是神经元(Neuron)模型,即上述定义的“简单单元”。在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个阈值(threshold),那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
M-P神经元模型(1943)

在这个模型中,神经元接收到来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”(activation function)处理以产生神经元的输出。
可以看到,一个神经元模型有如下组成部分:
(1) 输入权值
一个感知器可以接收多个输入: ![]()
每个输入上有一个权值: ![]()
阈值 可看作一个固定输入为-1.0的‘哑结点’,所对应的连接权重
可看作一个固定输入为-1.0的‘哑结点’,所对应的连接权重 ,这样,权重和阈值的学习就可统一为权重的学习。
,这样,权重和阈值的学习就可统一为权重的学习。
(2) 激活函数
神经元的激活函数可以有很多选择
典型的神经元激活函数

(3) 输出
神经元的输出由下面这个公式来计算:
![]()
把许多这样的神经元按一定的层次结构连接起来,就得到了神经网络。
感知器与多层网络
神经元和感知器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数或tanh函数。感知器由两层神经元组成,输入层接受外界收入信号,输出层是M-P神经元。

例1:用感知器实现and函数

令:
![]()
而激活函数f是阶跃函数,这时,感知器就相当于and函数。
输入上面真值表的第一行,即x1=0;x2=0,那么根据公式(1),计算输出:

也就是当x1x2都为0的时候,y为0,这就是真值表的第一行。自行验证上述真值表的第二、三、四行。
例2:用感知器实现or函数

我们来验算第二行,这时的输入是x1=0;x2=1,带入公式(1):

也就是当x1=0;x2=1时,y为1,即or真值表第二行。自行验证其它行。
若两类模式是线性可分的,即存在一个线性超平面能将它们分开,则感知器的学习过程一定会收敛而求得适当的权向量 ; 否则感知器学习过程将会发生震荡,w难以稳定下来,不能求得合适解。
; 否则感知器学习过程将会发生震荡,w难以稳定下来,不能求得合适解。
感知器能够解决与、或、非问题,但却不能解决异或问题。异或运算不是线性的,你无法用一条直线把分类0和分类1分开。
两层感知器就能解决。


最好先看线性回归、逻辑回归的内容
感知器训练算法(梯度下降)
将权重项和阈值初始化为0,然后,利用下面的感知器规则迭代的修改wi和,直到训练完成。


其中:


wi是与输入xi对应的权重项,是阈值。t是训练样本的实际值,一般称之为label。而y是感知器的输出值。η是一个称为学习速率的常数,其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量x,使用感知器计算其输出y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
实现感知器
新建perseptron.py
from functools import reduce
class Perception():
def __init__(self, input_num, activator):
'''
初始化感知器,设置输入参数的个数,以及激活函数
:param input_num:
:param activator:
'''
self.activator = activator
self.weights = [0.0 for _ in range(input_num)]
self.threshold = 0.0
def __str__(self):
'''
打印学习到的权重,阈值
:return:
'''
return 'weights\t:%s\nthreshold\t:%f\n' % (self.weights, self.threshold)
def predict(self, input_vec):
'''
输入向量,输出感知器的计算结果
:param input_vec:
:return:
'''
return self.activator(
reduce(lambda a, b: a + b, list(map(lambda x, w: x * w, input_vec, self.weights)), 0.0) + self.threshold)
def train(self, input_vecs, labels, iteration, rate):
'''
输入训练数据:一组向量、与每个向量对应的label,训练轮数、学习率
:param input_vecs:
:param labels:
:param rate:
:return:
'''
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
def _one_iteration(self, input_vecs, labels, rate):
'''
一次迭代,把所有的训练数据过一遍
:param input_vecs:
:param labels:
:param rate:
:return:
'''
samples = zip(input_vecs, labels)
for (input_vec, label) in samples:
output = self.predict(input_vec)
self._update_weights(input_vec, output, label, rate)
# **************************************梯度下降*************************************
def _update_weights(self, input_vec, output, label, rate):
'''
按照感知器规则更新权重
:param input_vec:
:param output:
:param label:
:param rate:
:return:
'''
delta = label - output
self.weights = list(map(lambda x, w: w + rate * delta * x, input_vec, self.weights))
self.threshold += rate * delta
def f(x):
'''
定义激活函数
:param x:
:return:
'''
return 1 if x > 0 else 0
def get_training_dataset():
input_vecs = [[1, 1], [0, 0], [1, 0], [0, 1]]
labels = [1, 0, 0, 0]
return input_vecs, labels
def train_and_perception():
p = Perception(2, f)
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
return p
if __name__ == '__main__':
and_perception = train_and_perception()
print(and_perception)
print('1 and 1 = %d' % and_perception.predict([1, 1]))
print('0 and 0 = %d' % and_perception.predict([0, 0]))
print('1 and 0 = %d' % and_perception.predict([1, 0]))
print('0 and 1 = %d' % and_perception.predict([0, 1]))

将and改为or运算只需修改labels值
线性单元
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
为了简单起见,我们可以设置线性单元的激活函数  为
为

替换了激活函数之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
线性单元的模型
即线性模型 -------------------pass
线性单元的目标函数
在监督学习下,对于一个样本,我们知道它的特征x,以及标记y。同时,我们还可以根据模型h(x)计算得到输出y¯注意这里面我们用y表示训练样本里面的标记,也就是实际值;用带上划线的y¯表示模型计算的出来的预测值。我们当然希望模型计算出来的y¯和y越接近越好。
数学上有很多方法来表示两者的接近程度,比如我们可以用两者的的差的平方的1/2来表示它们的接近程度

我们把e叫做单个样本的误差。至于为什么前面要乘  ,是为了后面计算方便。
,是为了后面计算方便。


x(i)表示第i个训练样本的特征,y(i)表示第个i样本的标记,我们也可以用元组(x(i),y(i))表示第i个训练样本。y¯(i)则是模型对第i个样本的预测值。
模型的训练,实际上就是求取到合适的w,使E最小。E就是我们优化的目标,称之为目标函数。
梯度下降优化算法
函数 的极值点,就是它的导数  的那个点。因此我们可以通过解方程 ,求得函数的极值点
的那个点。因此我们可以通过解方程 ,求得函数的极值点 。
。
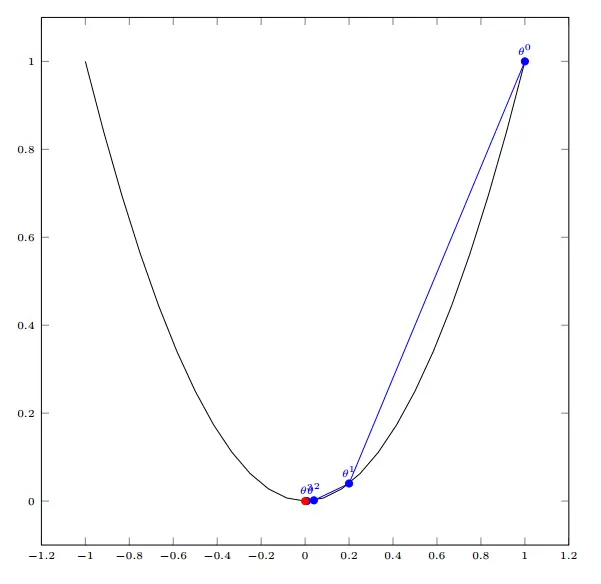
不过对于计算机来说,它可不会解方程。但是它可以凭借强大的计算能力,一步一步的去把函数的极值点『试』出来。如下图所示:

首先,我们随便选择一个点开始,比如上图的 点。接下来,每次迭代修改x的为x1,x2,x3,...,经过数次迭代后最终达到函数最小值点。
点。接下来,每次迭代修改x的为x1,x2,x3,...,经过数次迭代后最终达到函数最小值点。
你可能要问了,为啥每次修改的值,都能往函数最小值那个方向前进呢?这里的奥秘在于,我们每次都是向函数 的梯度的相反方向来修改x。什么是梯度呢?
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
梯度是一个向量,它指向函数值上升最快的方向。显然,梯度的反方向当然就是函数值下降最快的方向了。我们每次沿着梯度相反方向去修改x的值,当然就能走到函数的最小值附近。之所以是最小值附近而不是最小值那个点,是因为我们每次移动的步长不会那么恰到好处,有可能最后一次迭代走远了越过了最小值那个点。步长的选择是门手艺,如果选择小了,那么就会迭代很多轮才能走到最小值附近;如果选择大了,那可能就会越过最小值很远,收敛不到一个好的点上。
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。

我们同时可以假设这座山最陡峭的地方是无法通过肉眼立马观察出来的,而是需要一个复杂的工具来测量,同时,这个人此时正好拥有测量出最陡峭方向的能力。所以,此人每走一段距离,都需要一段时间来测量所在位置最陡峭的方向,这是比较耗时的。那么为了在太阳下山之前到达山底,就要尽可能的减少测量方向的次数。这是一个两难的选择,如果测量的频繁,可以保证下山的方向是绝对正确的,但又非常耗时,如果测量的过少,又有偏离轨道的风险。所以需要找到一个合适的测量方向的频率,来确保下山的方向不错误,同时又不至于耗时太多!
梯度下降算法的公式:
导数


反映的是函数y=f(x)在某一点处沿x轴正方向的变化率。再强调一遍,是函数f(x)在x轴上某一点处沿着x轴正方向的变化率/变化趋势。直观地看,也就是在x轴上某一点处,如果f’(x)>0,说明f(x)的函数值在x点沿x轴正方向是趋于增加的;如果f’(x)<0,说明f(x)的函数值在x点沿x轴正方向是趋于减少的。
导数和偏导数

导数与偏导数本质是一致的,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
区别在于:
导数,指的是一元函数中,函数y=f(x)在某一点处沿x轴正方向的变化率;
偏导数,指的是多元函数中,函数y=f(x1,x2,…,xn)在某一点处沿某一坐标轴(x1,x2,…,xn)正方向的变化率。
方向导数
导数和偏导数均是沿坐标轴正方向讨论函数的变化率。那么当我们讨论函数沿任意方向的变化率时,也就引出了方向导数的定义,即:某一点在某一趋近方向上的导数值。

通俗的解释是:我们不仅要知道函数在坐标轴正方向上的变化率(即偏导数),而且还要设法求得函数在其他特定方向上的变化率。而方向导数就是函数在其他特定方向上的变化率。
梯度

梯度的提出只为回答一个问题: 函数在变量空间的某一点处,沿着哪一个方向有最大的变化率?
梯度定义如下:
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
这里注意三点:
1)梯度是一个向量,即有方向有大小;
2)梯度的方向是最大方向导数的方向;
3)梯度的值是最大方向导数的值。
既然在变量空间的某一点处,函数沿梯度方向具有最大的变化率,那么在优化目标函数的时候,自然是沿着负梯度方向去减小函数值,以此达到我们的优化目标。
如何沿着负梯度方向减小函数值呢?既然梯度是偏导数的集合,如下:

在每个变量轴上减小对应变量值即可,梯度下降法可以描述如下:

即
![]()
∇  指 的梯度,
指 的梯度, 是步长,也称作学习速率。
是步长,也称作学习速率。
单变量函数的梯度下降
![]()
![]()
初始化,起点为
![]()
![]()
梯度下降的迭代计算过程:
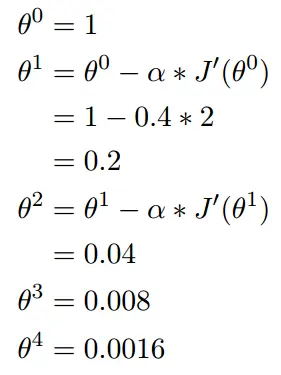
多变量函数的梯度下降
![]()
![]()
![]()
![]()

对于目标函数:
![]()

梯度下降算法可以写成
![]()
如果要求目标函数的最大值,那么我们就应该用梯度上升算法,它的参数修改规则是
![]()
目标函数E(w)的梯度是

和的导数等于导数的和,所以我们可以先把求和符号∑面的导数求出来,然后再把它们加在一起就行了,也就是


 是与w无关的常数,而
是与w无关的常数,而  ,下面我们根据链式求导法则来求导
,下面我们根据链式求导法则来求导
![]()
涉及到矩阵求导???
分别计算上式等号右边的两个偏导数


最后代入∇E(w),求得

即
![]()
先比较一下感知器模型和线性单元模型。

除了激活函数f不同之外,两者的模型和训练规则是一样的——梯度下降算法
新建linear.py
from perceptron import Perception
f = lambda x: x
class LinearUnit(Perception):
def __init__(self, input_num):
Perception.__init__(self, input_num, f)
def get_training_dataset():
input_vecs = [[5], [3], [8], [1.4], [10.1]]
labels = [5500, 2300, 7600, 1800, 11400]
return input_vecs, labels
def train_linear_unit():
lu = LinearUnit(1)
input_vecs, labels = get_training_dataset()
lu.train(input_vecs, labels, 10, 0.01)
return lu
if __name__ == '__main__':
linear_unit = train_linear_unit()
print(linear_unit)
print('Work 3.4 years, monthly salary = %.2f' % linear_unit.predict([3.4]))
print('Work 15 years, monthly salary = %.2f' % linear_unit.predict([15]))
print('Work 1.5 years, monthly salary = %.2f' % linear_unit.predict([1.5]))
print('Work 6.3 years, monthly salary = %.2f' % linear_unit.predict([6.3]))


随机梯度下降算法(Stochastic Gradient Descent, SGD)
梯度下降算法每次更新w的迭代,要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent)。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新w的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新w并不一定按照减少E的方向。然而,虽然存在一定随机性,大量的更新总体上沿着减少E的方向前进的,因此最后也能收敛到最小值附近。

椭圆表示的是函数值的等高线,椭圆中心是函数的最小值点。红色是BGD的逼近曲线,而紫色是SGD的逼近曲线。我们可以看到BGD是一直向着最低点前进的,而SGD明显躁动了许多,但总体上仍然是向最低点逼近的。
最后需要说明的是,SGD不仅仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
如果误差函数只有一个局部极小,那么,此时的局部极小就是全局最小;然而,如果误差函数具有多个局部极小,则不能保证找到的是全局最小。

- 以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数,这相当于从多个不同的初始点开始搜索,这样就可能陷入不同的局部极小,从中进行选择可能获得更接近全局最小的结果。
- 使用“模拟退火”,模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于“跳出”局部极小,在每步迭代过程中,接受“次优解”的概率要随着时间的推移而逐步降低,从而保证算法稳定。
- 随机梯度下降算法
多层网络
多层前馈神经网络(全连接(full connected, FC)神经网络):每层神经元与下一层神经元全互连,神经元之间不存在同层互连,也不存在跨层连接。前馈指网络拓扑结构上不存在环或回路。

- 神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
- 同一层的神经元之间没有连接。
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。
- 每个连接都有一个权值。
神经网络的学习过程,就是根据寻来你数据来调整神经元之间的“连接权”(connection weight)以及每个功能单元的阈值。
误差逆传播算法(error BackPropagation)
BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络,例如训练递归神经网络,一般是指多层前馈神经网络。

按照下面的方法计算出每个节点的误差项 :
:
对于输出层节点 i ,

其中, 是节点i 的误差项, 是节点i 的输出值,
是样本对于于节点 i 的目标值。
对于隐藏层节点,

其中, 是节点i 的输出值,
是节点i 的输出值, 是节点 i到它的下一层节点 k 的连接的权重,
是节点 i到它的下一层节点 k 的连接的权重, 是节点i 的下一层节点 k 的误差项。
是节点i 的下一层节点 k 的误差项。
最后,更新每个连接上的权值:

其中, 是节点i 到节点j 的权重, 是一个称为学习速率的常数,
是节点i 到节点j 的权重, 是一个称为学习速率的常数, 是节点j 的误差项,
是节点j 的误差项, 是节点i 传递给节点j的输入。
是节点i 传递给节点j的输入。
计算一个节点的误差项,需要先计算每个与其相连的下一层节点的误差项。这就要求误差项的计算顺序必须是从输出层开始,然后反向依次计算每个隐藏层的误差项,直到与输入层相连的那个隐藏层。这就是反向传播算法的名字的含义。当所有节点的误差项计算完毕后,我们就可以更新所有的权重。
反向传播算法其实就是链式求导法则的应用。然而,这个如此简单且显而易见的方法,却是在Roseblatt提出感知器算法将近30年之后才被发明和普及的。对此,Bengio这样回应道:
很多看似显而易见的想法只有在事后才变得显而易见。
推导过程
取网络所有输出层节点的误差平方和作为目标函数:

其中, 表示样本d 的误差 .
表示样本d 的误差 .
利用随机梯度下降算法对目标函数进行优化

随机梯度下降算法需要求出误差 对于每个权重 的偏导数,怎么求呢?
权重 仅能通过影响节点j 的输入值影响网络的其他部分,设 是节点j 的加权输入,即
是节点j 的加权输入,即

是的函数,而 是 的函数,根据链式求导法则,可以得到:


仅能通过节点j 的输出值 来影响网络其他部分,也就是说
是 的函数,而
是
的函数,其中

--------------------------------- 数学重灾区------------------------------------------------------------------------------------------------------------------------更直观表述

目标:(x1=0.10,x2=0.50 => Yout1=0.01,Yout2=0.89)
初始化:
输入:x1=0.1, x2 = 0.5
权重:w1=0.15, w2=0.30, w3=0.45, w4=0.60
w5=0.25, w6=0.40, w7=0.55, w8=0.65
偏置:b1=0.54, b2=0.87
前向传播
1> 输入层——》隐藏层
计算a1的加权和,将上面初始化的值带入运算即可,
NETa1 = x1×w1 + x2×w3 +b1=0.1×0.15+0.5×0.45+0.54=0.78
NETa2 = x1×w2 + x2×w4 +b1=0.1×0.30+0.5×0.60+0.54=0.87
对NETa1和NETa2使用Sigmoid激活函数,得到OUTa1,OUTa2,

2> 隐含层——》输出层
NETy1=OUTa1×w5 + OUTa2×w7 +b2=0.6857×0.25+0.7047×0.55+0.87=1.4290
NETy2=OUTa1×w6 + OUTa2×w8 +b2=0.6857×0.40+0.7047×0.65+0.87=1.6023
对NETy1和NETy2使用Sigmoid激活函数,得到OUTy1,OUTy2

反向传播
计算均方误差

1> 隐含层——》输出层 权值更新
以更新w5为例,要想知道w5对整体误差产生多少影响,就用整体误差对w求偏导:

![]()

![]()
![]()

![]()
假设β为学习率,β=0.1,则
![]()
同理可更新w6,w7,w8的值。
1> 输入层——》隐含层 权值更新
![]()

![]()

计算![]() 和
和![]() 相加得到总值
相加得到总值![]() ,
,
接着计算![]() 和
和![]() ,最后三者相乘,然后根据学习率更新权值。
,最后三者相乘,然后根据学习率更新权值。
其他类似。
全连接神经网络实现
先做一个基本的模型:

- Network 神经网络对象,提供API接口。它由若干层对象组成以及连接对象组成。
- Layer 层对象,由多个节点组成。
- Node 节点对象计算和记录节点自身的信息(比如输出值a、误差项等δ),以及与这个节点相关的上下游的连接。
- Connection 每个连接对象都要记录该连接的权重。
- Connections 仅仅作为Connection的集合对象,提供一些集合操作。
from functools import reduce
import random
from numpy import exp
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))class Node():
def __init__(self, layer_index, node_index):
'''
构造节点对象
:param layer_index: 节点所属的层的编号
:param node_index: 节点的编号
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.upstream = []
self.output = 0
self.delta = 0
def set_output(self, output):
'''
设置节点的输出值,如果节点属于输入层会用到这个函数
:param output:
:return:
'''
self.output = output
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.downstream.append(conn)
def append_upstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.upstream.append(conn)
# ?????????????????????????????????????????
def calc_output(self):
'''
计算节点输出
:return:
'''
# 0 ??????
output = reduce(lambda ret, conn: ret + conn.upstream_node.output * conn.weight, self.upstream, 0)
# print('output:', output)
self.output = sigmoid(output)
# ?????????????????????????????????????????
def calc_hidden_layer_delta(self):
'''
节点属于隐藏层时,计算delata
:return:
'''
# ????????
downstream_delta = reduce(
lambda ret, conn: ret + conn.downstream_node.delta * conn.weight, self.downstream, 0.0)
self.delta = self.output * (1 - self.output) * downstream_delta
# ?????????????????????????????????????????
def calc_output_layer_delta(self, label):
'''
节点属于输出层,计算delta
:param label:
:return:
'''
# ???????
self.delta = self.output * (1 - self.output) * (label - self.output)
class ConstNode():
def __init__(self, layer_index, node_index):
'''
:param layer_index:
:param node_index:
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.output = 1
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.downstream.append(conn)class Layer():
def __init__(self, layer_index, node_count):
self.layer_index = layer_index
self.nodes = []
for i in range(node_count):
self.nodes.append(Node(layer_index, i))
self.nodes.append(ConstNode(layer_index, node_count))
def set_output(self, data):
'''
设置层的输出,当层是输入层时会用到
:param data:
:return:
'''
for i in range(len(data)):
self.nodes[i].set_output(data[i])
def calc_output(self):
'''
计算层的输出向量
:return:
'''
for node in self.nodes[: -1]:
node.calc_output()class Connection():
def __init__(self, upstream_node, downstream_node):
'''
初始化权重,权重初始化为一个很小的随机数
:param upstream:
:param downstream:
'''
self.upstream_node = upstream_node
self.downstream_node = downstream_node
self.weight = random.uniform(-0.1, 0.1) # ???
self.gradient = 0.0class Connections():
def __init__(self):
self.connections = []
def add_connection(self, connection):
self.connections.append(connection)class Network():
def __init__(self, layers):
'''
初始化一个全连接神经网络
:param layers:
'''
self.connections = Connections()
self.layers = []
layer_count = len(layers)
node_count = 0
for i in range(layer_count):
self.layers.append(Layer(i, layers[i]))
for layer in range(layer_count - 1):
connections = [Connection(upstream_node, downstream_node)
for upstream_node in self.layers[layer].nodes
for downstream_node in self.layers[layer + 1].nodes[: -1]] # ???
for conn in connections:
self.connections.add_connection(conn)
conn.downstream_node.append_upstream_connection(conn)
conn.upstream_node.append_downstream_connection(conn)
print('初始化完成')
def train(self, labels, data_set, rate, iteration):
'''
训练神经网络
labels: 数组,训练样本标签。每个元素是一个样本的标签。
data_set: 二维数组,训练样本特征。每个元素是一个样本的特征。
'''
for i in range(iteration):
for d in range(len(data_set)):
self.train_one_sample(labels[d], data_set[d], rate)
def train_one_sample(self, label, sample, rate):
'''
内部函数,用一个样本训练网络
'''
self.predict(sample)
self.calc_delta(label)
self.update_weight(rate)
def predict(self, sample):
'''
根据输入的样本预测输出值
sample: 数组,样本的特征,也就是网络的输入向量
'''
self.layers[0].set_output(sample)
for i in range(1, len(self.layers)):
self.layers[i].calc_output()
return list(map(lambda node: node.output, self.layers[-1].nodes[:-1]))
def calc_delta(self, label):
'''
内部函数,计算每个节点的delta
'''
output_nodes = self.layers[-1].nodes
for i in range(len(label)):
output_nodes[i].calc_output_layer_delta(label[i])
for layer in self.layers[-2::-1]:
for node in layer.nodes:
node.calc_hidden_layer_delta()
global count
count = count + 1
print('误差计算', count)
def update_weight(self, rate):
'''
内部函数,更新每个连接权重
'''
for layer in self.layers[:-1]:
for node in layer.nodes:
for conn in node.downstream:
conn.update_weight(rate)def calc_gradient(self):
'''
计算梯度
:return:
'''
self.gradient = self.downstream_node.delta * self.upstream_node.output
def update_weight(self, rate):
'''
根据梯度下降算法更新权重
:param rate:
:return:
'''
self.calc_gradient()
self.weight += rate * self.gradient完整代码:
from functools import reduce
import random
from numpy import exp
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))
class Node():
def __init__(self, layer_index, node_index):
'''
构造节点对象
:param layer_index: 节点所属的层的编号
:param node_index: 节点的编号
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.upstream = []
self.output = 0
self.delta = 0
def set_output(self, output):
'''
设置节点的输出值,如果节点属于输入层会用到这个函数
:param output:
:return:
'''
self.output = output
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.downstream.append(conn)
def append_upstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.upstream.append(conn)
# ?????????????????????????????????????????
def calc_output(self):
'''
计算节点输出
:return:
'''
# 0 ??????
output = reduce(lambda ret, conn: ret + conn.upstream_node.output * conn.weight, self.upstream, 0)
# print('output:', output)
self.output = sigmoid(output)
# ?????????????????????????????????????????
def calc_hidden_layer_delta(self):
'''
节点属于隐藏层时,计算delata
:return:
'''
# ????????
downstream_delta = reduce(
lambda ret, conn: ret + conn.downstream_node.delta * conn.weight, self.downstream, 0.0)
self.delta = self.output * (1 - self.output) * downstream_delta
# ?????????????????????????????????????????
def calc_output_layer_delta(self, label):
'''
节点属于输出层,计算delta
:param label:
:return:
'''
# ???????
self.delta = self.output * (1 - self.output) * (label - self.output)
def __str__(self):
'''
打印节点的信息
:return:
'''
node_str = '%u-%u:output:%f delta:%f' % (self.layer_index, self.node_index, self.output, self.delta)
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
upstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.upstream, '')
return node_str + '\n\tdownstream:' + downstream_str + '\n\tupstream:' + upstream_str
class ConstNode():
def __init__(self, layer_index, node_index):
'''
:param layer_index:
:param node_index:
'''
self.layer_index = layer_index
self.node_index = node_index
self.downstream = []
self.output = 1
def append_downstream_connection(self, conn):
'''
添加一个到下游节点的连接
:param conn:
:return:
'''
self.downstream.append(conn)
def calc_hidden_layer_delta(self):
'''
节点属于隐藏层时,计算delata
:return:
'''
# 0.0 ????????
downstream_delta = reduce(
lambda ret, conn: ret + conn.downstream_node.delta * conn.weight, self.downstream, 0.0)
self.delta = self.output * (1 - self.output) * downstream_delta
def __str__(self):
'''
打印节点的信息
:return:
'''
node_str = '%u-%u: output: 1' % (self.layer_index, self.node_index)
# ???????
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
return node_str + '\n\tdownstream:' + downstream_str
class Layer():
def __init__(self, layer_index, node_count):
self.layer_index = layer_index
self.nodes = []
for i in range(node_count):
self.nodes.append(Node(layer_index, i))
self.nodes.append(ConstNode(layer_index, node_count))
def set_output(self, data):
'''
设置层的输出,当层是输入层时会用到
:param data:
:return:
'''
for i in range(len(data)):
self.nodes[i].set_output(data[i])
def calc_output(self):
'''
计算层的输出向量
:return:
'''
for node in self.nodes[: -1]:
node.calc_output()
def dump(self):
'''
打印层的信息
:return:
'''
for node in self.nodes:
print(node)
class Connection():
def __init__(self, upstream_node, downstream_node):
'''
初始化权重,权重初始化为一个很小的随机数
:param upstream:
:param downstream:
'''
self.upstream_node = upstream_node
self.downstream_node = downstream_node
self.weight = random.uniform(-0.1, 0.1) # ???
self.gradient = 0.0
def calc_gradient(self):
'''
计算梯度
:return:
'''
self.gradient = self.downstream_node.delta * self.upstream_node.output
def get_gradient(self):
return self.gradient
def update_weight(self, rate):
'''
根据梯度下降算法更新权重
:param rate:
:return:
'''
self.calc_gradient()
self.weight += rate * self.gradient
def __str__(self):
return '(%u-%u)->(%u-%u)=%f' % (
self.upstream_node.layer_index,
self.upstream_node.node_index,
self.downstream_node.layer_index,
self.downstream_node.node_index,
self.weight
)
class Connections():
def __init__(self):
self.connections = []
def add_connection(self, connection):
self.connections.append(connection)
def dump(self):
for conn in self.connections:
print(conn)
count = 0
class Network():
def __init__(self, layers):
'''
初始化一个全连接神经网络
:param layers:
'''
self.connections = Connections()
self.layers = []
layer_count = len(layers)
node_count = 0
for i in range(layer_count):
self.layers.append(Layer(i, layers[i]))
for layer in range(layer_count - 1):
connections = [Connection(upstream_node, downstream_node)
for upstream_node in self.layers[layer].nodes
for downstream_node in self.layers[layer + 1].nodes[: -1]] # ???
for conn in connections:
self.connections.add_connection(conn)
conn.downstream_node.append_upstream_connection(conn)
conn.upstream_node.append_downstream_connection(conn)
print('初始化完成')
def train(self, labels, data_set, rate, iteration):
'''
训练神经网络
labels: 数组,训练样本标签。每个元素是一个样本的标签。
data_set: 二维数组,训练样本特征。每个元素是一个样本的特征。
'''
for i in range(iteration):
for d in range(len(data_set)):
self.train_one_sample(labels[d], data_set[d], rate)
def train_one_sample(self, label, sample, rate):
'''
内部函数,用一个样本训练网络
'''
self.predict(sample)
self.calc_delta(label)
self.update_weight(rate)
def calc_delta(self, label):
'''
内部函数,计算每个节点的delta
'''
output_nodes = self.layers[-1].nodes
for i in range(len(label)):
output_nodes[i].calc_output_layer_delta(label[i])
for layer in self.layers[-2::-1]:
for node in layer.nodes:
node.calc_hidden_layer_delta()
global count
count = count + 1
print('误差计算', count)
def update_weight(self, rate):
'''
内部函数,更新每个连接权重
'''
for layer in self.layers[:-1]:
for node in layer.nodes:
for conn in node.downstream:
conn.update_weight(rate)
def calc_gradient(self):
'''
内部函数,计算每个连接的梯度
'''
for layer in self.layers[:-1]:
for node in layer.nodes:
for conn in node.downstream:
conn.calc_gradient()
def get_gradient(self, label, sample):
'''
获得网络在一个样本下,每个连接上的梯度
label: 样本标签
sample: 样本输入
'''
self.predict(sample)
self.calc_delta(label)
self.calc_gradient()
def predict(self, sample):
'''
根据输入的样本预测输出值
sample: 数组,样本的特征,也就是网络的输入向量
'''
self.layers[0].set_output(sample)
for i in range(1, len(self.layers)):
self.layers[i].calc_output()
return list(map(lambda node: node.output, self.layers[-1].nodes[:-1]))
def dump(self):
'''
打印网络信息
'''
for layer in self.layers:
layer.dump()
def gradient_check(network, sample_feature, sample_label):
'''
梯度检查
:param network: 神经网络对象
:param sample_feature: 样本特征
:param sample_label: 样本标签
:return:
'''
# 计算网络误差
network_error = lambda vec1, vec2: \
0.5 * reduce(lambda a, b: a + b,
map(lambda v: (v[0] - v[1]) * (v[0] - v[1]),
zip(vec1, vec2)))
# 获取网络在当前样本下每个连接的梯度
network.get_gradient(sample_feature, sample_label)
# 对每个权重做梯度检查
for conn in network.connections.connections:
# 获取指定连接的梯度
actual_gradient = conn.get_gradient()
# 增加一个很小的值,计算网络的误差
epsilon = 0.0001
conn.weight += epsilon
error1 = network_error(network.predict(sample_feature), sample_label)
# 减去一个很小的值,计算网络的误差
conn.weight -= 2 * epsilon
error2 = network_error(network.predict(sample_feature), sample_label)
#
expected_gradient = (error2 - error1) / (2 * epsilon)
# l
print('expected gradient:\t%f\nactual gradient:\t%f' % (expected_gradient, actual_gradient))
每次更新w的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,效率大大提升。
MNIST大约有60000个手写字母的训练样本,我们使用它训练我们的神经网络,然后再用训练好的网络去识别手写数字。
手写数字识别是个比较简单的任务,数字只可能是0-9中的一个,这是个10分类问题。
MNIST数据集每个训练数据是28*28的图片,共784个像素,因此,输入层节点数应该是784,每个像素对应一个输入节点。输出层节点数也是确定的。因为是10分类,我们可以用10个节点,每个节点对应一个分类。输出层10个节点中,输出最大值的那个节点对应的分类,就是模型的预测结果。
先试试仅有一个隐藏层的神经网络效果,隐藏层节点数量是不好确定的,从1到100万都可以。下面有几个经验公式:

如果有时间,我们可以设置不同的节点数,分别训练,看看哪个效果最好就用哪个。我们先拍一个,设隐藏层节点数为300吧。对于3层784*300*10的全连接网络,总共有(784+1)*300+(300+1)*10=238510个参数!神经网络之所以强大,是它提供了一种非常简单的方法去实现大量的参数。
MNIST数据集包含10000个测试样本。我们先用60000个训练样本训练我们的网络,然后再用测试样本对网络进行测试,计算识别错误率:

我们每训练10轮,评估一次准确率。当准确率开始下降时(出现了过拟合)终止训练。
每个训练样本是一个28*28的图像,我们按照行优先,把它转化为一个784维的向量。每个标签是0-9的值,我们将其转换为一个10维的one-hot向量:如果标签值为,我们就把向量的第维(从0开始编号)设置为0.9,而其它维设置为0.1。例如,向量[0.1,0.1,0.9,0.1,0.1,0.1,0.1,0.1,0.1,0.1]表示值2。
新建mnist.py
from BP import *
from datetime import datetime
# 数据加载器基类
class Loader():
def __init__(self, path, count):
'''
初始化加载器
:param path:数据文件路径
:param count: 文件中的样本个数
'''
self.path = path
self.count = count
def get_file_content(self):
'''
读取文件内容
:return:
'''
f = open(self.path, 'rb')
content = f.read()
f.close()
return content
# 图像数据加载器
class ImageLoader(Loader):
def get_picture(self, content, index):
'''
内部函数,从文件中获取图像
:param content:
:param index:
:return:
'''
start = index * 28 * 28 + 16 # ??????
picture = []
for i in range(28):
picture.append([])
for j in range(28):
picture[i].append(content[start + i * 28 + j]) # ???
return picture
def get_one_sample(self, picture):
'''
将图像转化为样本的输入向量
:param picture:
:return:
'''
sample = []
for i in range(28):
for j in range(28):
sample.append(picture[i][j])
return sample
def load(self):
'''
加载数据文件,获得全部样本的输入向量
:return:
'''
content = self.get_file_content()
data_set = []
for index in range(self.count):
data_set.append(
self.get_one_sample(
self.get_picture(content, index)
)
)
return data_set
# 标签数据加载器
class LabelLoader(Loader):
def load(self):
'''
加载数据文件,获得全部样本的输入向量
:return:
'''
content = self.get_file_content()
labels = []
for index in range(self.count): # content[index + 8]?
labels.append(self.norm(content[index + 8]))
return labels
def norm(self, label):
'''
将一个值转换为10维标签向量
:param label:
:return:
'''
label_vec = []
label_value = label
for i in range(10):
if i == label_value:
label_vec.append(0.9)
else:
label_vec.append(0.1)
return label_vec
def get_training_data_set():
'''
获得训练数据集
:return:
'''
image_loader = ImageLoader('data/train-images.idx3-ubyte', 60000)
label_loader = LabelLoader('data/train-labels.idx1-ubyte', 60000)
return image_loader.load(), label_loader.load()
def get_test_data_set():
'''
获得测试数据集
:return:
'''
image_loader = ImageLoader('data/t10k-images.idx3-ubyte', 10000)
label_loader = LabelLoader('data/t10k-labels.idx1-ubyte', 10000)
return image_loader.load(), label_loader.load()
def get_result(vec):
max_value_index = 0
max_value = 0
for i in range(len(vec)):
if vec[i] > max_value:
max_value = vec[i]
max_value_index = i
return max_value_index
def evaluate(network, test_data_set, test_labels):
error = 0
total = len(test_data_set)
for i in range(total):
label = get_result(test_labels[i])
predict = get_result(network.predict(test_data_set[i]))
if label != predict:
error += 1
return float(error) / float(total)
def train_and_evaluate():
last_error_ratio = 1.0
epoch = 0
train_data_set, train_labels = get_training_data_set()
test_data_set, test_labels = get_test_data_set()
# -------------------------------------------------------------
network = Network([784, 300, 10])
print('hahahaha')
while True:
epoch += 1
network.train(train_labels, train_data_set, 0.3, 1)
print('hahahahahonghong')
print('%s epoch %d finished' % (now(), epoch))
if epoch % 10 == 0:
error_ratio = evaluate(network, test_data_set, test_labels)
print('%s after epoch %d,error ratio is %f' % (now(), epoch, error_ratio))
if error_ratio > last_error_ratio:
break
else:
last_error_ratio = error_ratio
if __name__ == '__main__':
train_and_evaluate()















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









