









一、逻辑斯蒂分布
逻辑斯蒂分布也叫作增长分布,其分布函数是一个增长函数。
设X是连续随机变量,X服从逻辑斯谛分布是指X具有下列分布函数和密度函数:
分布函数: F ( x ) = P ( X ⩽ x ) = 1 1 + e − ( x − μ ) / y F(x)=P(X\leqslant x)=\frac{1}{1+e^{-(x-\mu )/y}} F(x)=P(X⩽x)=1+e−(x−μ)/y1
密度函数: f ( x ) = F ′ ( x ) = e − ( x − μ ) / y γ ( 1 + e − ( x − μ ) / y ) 2 f(x)=F'(x)=\frac{e^{-(x-\mu)/y}}{\gamma (1+e^{-(x-\mu)/y})^{2}} f(x)=F′(x)=γ(1+e−(x−μ)/y)2e−(x−μ)/y
上式中, μ \mu μ为位置参数, γ > 0 \gamma > 0 γ>0为形状参数。
在不同的参数下概率密度函数 p ( x ; μ , γ ) p(x;\mu ,\gamma ) p(x;μ,γ)的图像如下所示(图中的s是参数 γ \gamma γ):
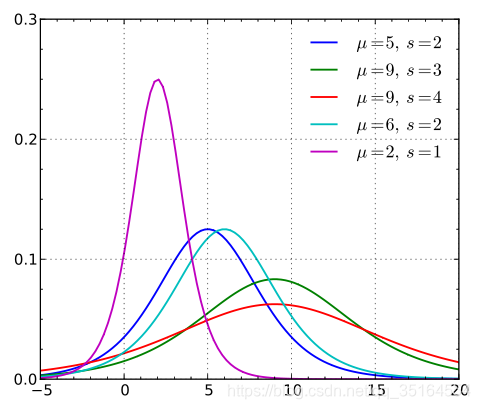
在不同参数下分布函数
p
(
x
;
μ
,
γ
)
p(x;\mu ,\gamma )
p(x;μ,γ)的图像如下所示(图中的s是参数
γ
\gamma
γ):
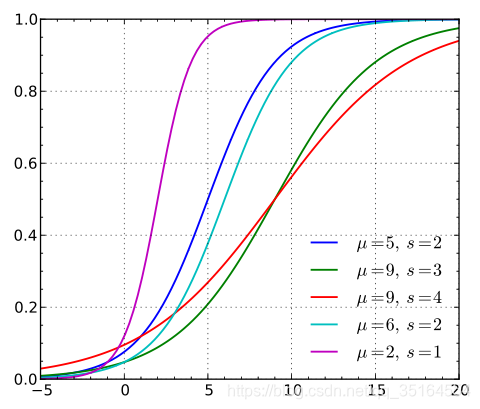
根据分布函数我们可以看出图像呈s型,且关于点 ( μ , 1 2 ) (\mu,\frac{1}{2}) (μ,21)成中心对称,曲线在两端的增长速度很慢,在中间的增长速度很快,且 γ \gamma γ(s)的值越小增长速度越快。
当我们选择 μ = 0 , γ = 1 \mu=0,\gamma=1 μ=0,γ=1的时候,逻辑斯蒂概率分布函数就是我们逻辑斯蒂回归中药用到的sigmoid函数,即:
s i g m o i d ( z ) = g ( z ) = 1 1 + e − z sigmoid(z)=g(z)=\frac{1}{1+e^{-z}} sigmoid(z)=g(z)=1+e−z1
其导数: g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) g'(z)=g(z)(1-g(z)) g′(z)=g(z)(1−g(z)) (这是一个很好的性质,后文中我们会用到)。
二、逻辑回归的由来
我们都知道了线性回归可以进行回归学习,但是想要去做分类问题的时候应该怎么办呢?其实我们只需要去找到一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来。
我们首先考虑二分类任务,其输出标记为y={0,1},而线性回归模型产生的预测值z=w^Tx+b是实值,我们需要的是将这个实值z转换为0/1值,最理想的是“单位阶跃函数”,也就是如下的形式。
y = { 0 , z < 0 ; 0.5 , z = 0 ; 1 , z > 0. y=\left\{\begin{matrix} 0 , z<0;& & \\ 0.5, z=0;& & \\ 1, z>0.& & \end{matrix}\right. y=⎩⎨⎧0,z<0;0.5,z=0;1,z>0.
这个函数代表的也就是若预测值z大于0就判为正例,小于0则判为负例,预测值为临界值0则可以任意判别,对应的图形表示如下。
对于图中的单位阶跃函数(红色)我们可以看出它并不是连续的,于是我们希望找到能在一定程度上近似单位阶跃函数的替代函数,并希望它是单调可微的,也就是如下的形式:
y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1
性质:我们把用g(z)来表示y,它的导数形式为 g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) g'(z)=g(z)(1-g(z)) g′(z)=g(z)(1−g(z))。
该函数我们称作对数几率函数,也可以称作“Sigmoid函数”,它将z值转化为了一个接近0或1的y值。我们结合z的表达式可以得到如下的形式:
y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1
三、逻辑回归的推导
对于上文中这种将z(线性回归函数)带入到sigmoid函数转化为分类问题的形式我们可以把它叫做逻辑回归(logistic regression)
从二分类问题入手,我们给定数据集 D ( ( x i , y i ) 1 m ) D({(x_{i},y_{i})}_1^{m}) D((xi,yi)1m),我们希望对于输入数据 x ∈ R x\in R x∈R,有输出 y i ∈ { 0 , 1 } y_{i}\in\left \{ 0,1 \right \} yi∈{0,1},一类为正例,一类为负例。``
首先我们进行一个设定(g(z)表示sigmoid函数):
x i x^i xi为正例的概率: h θ ( x ( i ) ) = g ( θ T x ( i ) ) h_{\theta }(x^{(i)})=g(\theta^T x^{( i )}) hθ(x(i))=g(θTx(i))
x^i为负例的概率: 1 − h θ ( x ( i ) ) = 1 − g ( θ T x ( i ) ) 1-h_{\theta }(x^{ ( i )})=1-g(\theta^T x^ {( i )}) 1−hθ(x(i))=1−g(θTx(i))
对于真实标记为正例的样本我们希望 h θ ( x ( i ) ) h_{\theta }(x^{(i)}) hθ(x(i))越大越好。
对于真实标记为负例的样本我们希望 1 − h θ ( x ( i ) ) 1-h_{\theta }(x^{(i)}) 1−hθ(x(i))越大越好。
利用极大似然,我们希望得到:
m a x ∏ i = 1 m = h θ ( x ( i ) ) ( y ( i ) ) ∗ ( 1 − h θ ( x ( i ) ) ) ( 1 − y ( i ) ) max \prod_{i=1}^{m}=h_{\theta }(x^{( i )})^{(y^{(i)})}*(1-h_{\theta }(x^{( i )}))^{(1-y^{(i)}) } max∏i=1m=hθ(x(i))(y(i))∗(1−hθ(x(i)))(1−y(i))
即:
m a x 1 m ∑ i = 1 m y ( i ) l o g ( h ( θ ) ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h ( θ ) ( x ( i ) ) ) max\frac{1}{m}\sum_{i=1}^{m}y^{(i)}log (h_{(\theta) }(x^{(i)}))+(1-y^{(i)})log(1- h_{(\theta) }(x^{(i)})) maxm1∑i=1my(i)log(h(θ)(x(i)))+(1−y(i))log(1−h(θ)(x(i)))
即:
l o s s = − 1 m ∑ i = 1 m y ( i ) l o g ( h ( θ ) ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h ( θ ) ( x ( i ) ) ) loss = -\frac{1}{m}\sum_{i=1}^{m}y^{(i)}log (h_{(\theta) }(x^{(i)}))+(1-y^{(i)})log(1- h_{(\theta) }(x^{(i)})) loss=−m1∑i=1my(i)log(h(θ)(x(i)))+(1−y(i))log(1−h(θ)(x(i)))
在实际应用中我们需要不断的减小loss使得模型优化,我们采用梯度下降法来优化模型:
(对loss进行求导,我们只处理\sum后的补分即可)
d l d θ = y ∗ 1 h θ ( x ) ∗ h θ ′ ( x ) ∗ x + ( 1 − y ) ∗ 1 1 − h θ ( x ) ∗ ( − h θ ′ ( x ) ) ∗ x \frac{dl}{d\theta}=y*\frac{1}{h_{\theta}(x)}*h_{\theta}'(x)*x+(1-y)*\frac{1}{1-h_{\theta}(x)}*(-h_{\theta}'(x))*x dθdl=y∗hθ(x)1∗hθ′(x)∗x+(1−y)∗1−hθ(x)1∗(−hθ′(x))∗x
= y ∗ ( 1 − h θ ( x ) ) ∗ x + ( 1 − y ) ∗ h θ ( x ) ∗ x ∗ − 1 =y*(1-h_{\theta}(x))*x+(1-y)*h_{\theta}(x)*x*-1 =y∗(1−hθ(x))∗x+(1−y)∗hθ(x)∗x∗−1 (此处用到sigmoid函数的求导特性)
= ( y − h θ ( x ) ) ∗ x =(y-h_{\theta}(x))*x =(y−hθ(x))∗x
由此可得梯度为:
g r a d s = ∑ i = 1 m ( y ( i ) − h θ ( x ( i ) ) ) ∗ x ( i ) grads=\sum_{i=1}^{m}(y^{(i)}-h_{\theta}(x^{(i)}))*x^{(i)} grads=∑i=1m(y(i)−hθ(x(i)))∗x(i)
梯度参数更新即为:
θ : = θ − ∑ i = 1 m ( y ( i ) − h θ ( x ( i ) ) ) ∗ x ( i ) \theta:=\theta-\sum_{i=1}^{m}(y^{(i)}-h_{\theta}(x^{(i)}))*x^{(i)} θ:=θ−∑i=1m(y(i)−hθ(x(i)))∗x(i)
以上便是逻辑回归的损失函数的推导以及梯度下降法参数更新的推导过程。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











