







 本文详细介绍了数据挖掘中处理缺失值的七种方法,包括均值、中位数、众数填充,前后数据填充,自定义数据填充,Pandas插值以及机器学习算法填充。这些方法适用于不同数据类型和场景,例如数值类型和字符类型数据,以及具有前后关系的数据。对于数值类型数据,可以选择线性回归等机器学习模型进行预测填充;而对于字符类型数据,如城市信息,可使用众数填充。
本文详细介绍了数据挖掘中处理缺失值的七种方法,包括均值、中位数、众数填充,前后数据填充,自定义数据填充,Pandas插值以及机器学习算法填充。这些方法适用于不同数据类型和场景,例如数值类型和字符类型数据,以及具有前后关系的数据。对于数值类型数据,可以选择线性回归等机器学习模型进行预测填充;而对于字符类型数据,如城市信息,可使用众数填充。
| 新专栏《数据挖掘(分析)面经》 |
| 第一篇:缺失值处理方法 |
对于从事数据相关工作的小伙伴,面试的时候经常会被问到如何进行缺失值/异常值的处理,本文来梳理一下填补缺失值的7种方法。
示例数据
本文所使用的示例数据创建如下:
import pandas as pd
import numpy as np
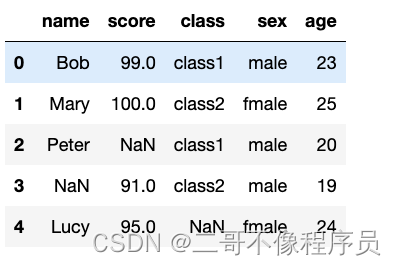
data = pd.DataFrame({
'name': ['Bob', 'Mary', 'Peter', np.nan, 'Lucy'],
'score': [99, 100, np.nan, 91, 95],
'class': ['class1', 'class2', 'class1', 'class2', np.nan],
'sex': ['male', 'fmale', 'male', 'male', 'fmale'],
'age': [23, 25, 20, 19, 24]
})
一、均值填充
- 适用数据类型:数值类型
- 适用场景:数据整体极值差异不大时
- 举例:对成年男性身高的缺失值进行填充
- 代码示例:对
data数据中的score进行均值填充
data['score'].fillna(data['score'].mean())
# 结果如下
0 99.00
1 100.00
2 96.25
3 91.00
4 95.00
二、中位数填充
- 适用数据类型:数值类型
- 适用场景:数据整体极值差异较大时
- 举例:对人均收入进行填充(数据中含有高收入人群:如马总)
- 代码示例:对
data数据中的score进行中位数填充
data['score'].fillna(data['score'].median())
# 结果如下
0 99.0
1 100.0
2 97.0
3 91.0
4 95.0
三、众数填充
- 适用数据类型:字符类型|没有大小关系的数值类型数据
- 适用场景:大多数情况下
- 举例:对城市信息的缺失进行填充/对工人车间编号进行填充
- 代码示例:对
data数据中的class进行众数填充(注意:众数填充时要通过索引0进行取值,一组数据的众数可能有多个,索引为0的数据一定会存在)
data['class'].fillna(data['class'].mode()[0])
# 结果如下
0 class1
1 class2
2 class1
3 class2
4 class1
四、前后数据填充
- 适用数据类型:数值类型|字符类型
- 适用场景:数据行与行之间具有前后关系时
- 举例:学年成绩排行中的某同学某科目成绩丢失
- 代码示例:对
data数据中的score进行前后数据填充
# 前文填充
data['score'].fillna(method='pad')
# 后文填充
data['score'].fillna(method='bfill')
# 前文填充结果
0 99.0
1 100.0
2 100.0
3 91.0
4 95.0
# 后文填充结果
0 99.0
1 100.0
2 91.0
3 91.0
4 95.0
五、自定义数据填充
- 适用数据类型:数值类型|字符类型
- 适用场景:业务规定外的数据
- 举例:某调查问卷对婚后幸福程度进行调查,到那时很多人是未婚,可以自定义内容表示未婚人群
- 代码示例:对
data数据中的name进行自定义数据填充
data['name'].fillna('no_name')
# 结果如下
0 Bob
1 Mary
2 Peter
3 no_name
4 Lucy
六、Pandas插值填充
- 适用数据类型:数值类型
- 适用场景:数据列的含义较为复杂,需要更精确的填充方法时
- 举例:对所有带有
nan的数值列dataframe进行填充 - 说明:
pandas中进行空值填充的方法为interpolate(),该方法的本质是使用各种数学(统计学)中的插值方法进行填充,其中包含最近邻插值法、阶梯插值、线性插值、B样条曲线插值等多种方法。 - 参数说明:interpolate()参数介绍
- 代码示例:
data['score'].interpolate()
# 结果如下
0 99.0
1 100.0
2 95.5
3 91.0
4 95.0
七、机器学习算法填充
- 适用数据类型:数值类型|字符类型
- 适用场景:具有多种数据维度的场景
- 说明:可以选择不同的回归|分类模型对数据进行填充
- 注意:下面的例子中不考虑具体场景,只是用于举例
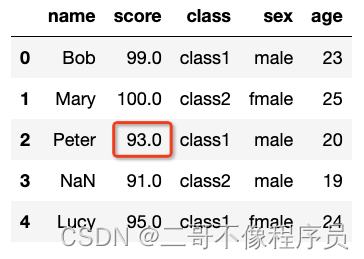
- 数值类型数据填充代码示例(线性回归):
from sklearn.linear_model import LinearRegression
# 获取数据
data_train = data.iloc[[0, 1, 3]]
data_train_x = data_train[['age']]
data_train_y = data_train['score']
# 使用线性回归进行拟合
clf = LinearRegression()
clf.fit(data_train_x, data_train_y)
# 使用预测结果进行填充
data['score'].iloc[2] = clf.predict(pd.DataFrame(data[['age']].iloc[2]))
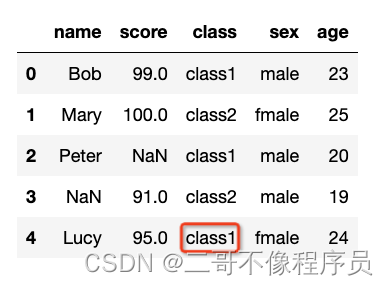
- 字符类型数据填充代码示例(决策树):
from sklearn.tree import DecisionTreeClassifier
# 获取数据
data_train = data.iloc[[0, 1, 3]]
data_train_x = data_train[['age']]
data_train_y = data_train['class']
# 使用决策树进行拟合
clf = DecisionTreeClassifier()
clf.fit(data_train_x, data_train_y)
# 使用分类结果进行填充
data['class'].iloc[4] = clf.predict(pd.DataFrame(data[['age']].iloc[4]))[0]


















 2262
2262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











