









文本分类大体被我分为4类,链接如下:
文本分类流程(一)文本分类的大致步骤+数据预处理------毕业论文的纪念
文本分类(二)文本数据数值化,向量化,降维
文本分类(三)–对已经处理好的数据使用KNN、Naive Bayes、SVM分类方法
文本分类(四)–分类好坏的评价
所使用的主要有四个评价的标准,根据不同的分类情况,有的单独分析,有的综合着来看。
这四个评估标准分别是Accuracy, Precision, Recall, f1-score.
我自己对他们的理解:
- Accuracy(准确率):
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
\cfrac{TP+TN}{TP+TN+FP+FN}
TP+TN+FP+FNTP+TN
综合分类正确的概率,综合是指正类和负类被分类正确的概率 - Precision(精确率):
T
P
T
P
+
F
P
\cfrac{TP}{TP+FP}
TP+FPTP or
T
N
T
N
+
F
N
\cfrac{TN}{TN+FN}
TN+FNTN对正类/负类样本的区分能力。
针对某一类而言的,正类或者是负类,一般的模块中的precision还有一般的理解是被分为正类的准确率。即所有被分为正类的样本中,真正被分类正确的概率。负类同理。(在我的论文中利用sklearn模块中的metrics对象中的方法来计算的准确率,上面一行是负类,下面一行是正类)
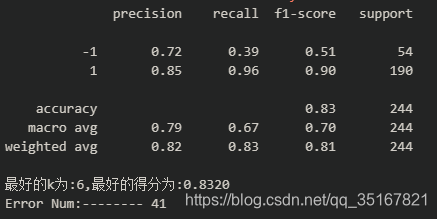
上面是负类的precision, recall f1-score, 下面是正类的相关评估结果。 - Recall(召回率):
T
P
T
P
+
F
N
\cfrac{TP}{TP+FN}
TP+FNTP or
T
N
T
N
+
F
P
\cfrac{TN}{TN+FP}
TN+FPTN 对正类/负类样本的识别能力。
也是针对某一类而言的,一般与Precision相对应。召回,是否全部被发现的意思。还是对正类来讲,是所有的正类都被探测出来的概率,即你是正类,我讲你归为正类的概率。那些没有分探索出来的有被错误分为负类的样本(FN)。 - F1-score:
P
R
P
+
R
\cfrac{PR}{P+R}
P+RPR,P-precision, R- recall
也是对正类或者负类某一类来讲的。是准确率与召回率的综合指标,f1-score越高,模型越稳健(要考的)。
参考资料:
准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
分类器模型评价指标
文本分类——算法性能评估
Python scikit-learn,分类模型的评估,精确率和召回率,classification_report
机器学习中的F1-score
python sklearn画ROC曲线
我的毕业论文差不多就是这几个方法加上我自己从网上获取的评论进行分析。听起来确实是蛮简单的,最基础的东西,但是实实在在地花了我很多的时间去入门,去理解去实现从开始到最后分析的每一步。感谢在这一路上帮助过我的每一个人,非常感谢。同时我也希望能够将自己从这些地方学习的东西记录下来,以去帮助曾经像我这样迷茫过的人,真诚的希望大家都能够在自己感兴趣的道路上面越走越远,当坚持不下去的时候告诉自己,大家都是这么过来的,你并不是一个人嘞,谁学习东西一下子就会的,very little.
那么,未来继续探索知识,永远地学习下去吧。感谢他人,感谢自己。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









