







语义分割FCN FPN UNet DeepLab HRNet SETR TransFuse...
图像分类:
目标检测:
语义分割:
实例分割:
1. FCN
将CNN中的1维FC layers替换为对应的2维卷积层,类别信息也转换为对应的空间位置信息。

5次下采样后,图像分辨率缩小32倍,在通过线性插值等上采样方式将分辨率增大至上一层大小,之后进行相加等融合…16倍…8倍.

FCN-32s:
# Convolutional layers transfered from fully-connected layers
x = Conv2D(4096, (7, 7), activation='relu', padding='same', name='fc1', kernel_regularizer=l2(weight_decay))(x)
x = Dropout(0.5)(x)
x = Conv2D(4096, (1, 1), activation='relu', padding='same', name='fc2', kernel_regularizer=l2(weight_decay))(x)
x = Dropout(0.5)(x)
# classifying layer
x = Conv2D(classes, (1, 1), kernel_initializer='he_normal', activation='linear', padding='valid', strides=(1, 1), kernel_regularizer=l2(weight_decay))(x)
x = BilinearUpSampling2D(size=(32, 32))(x)
# loss fuction
loss = softmax_sparse_crossentropy_ignoring_last_label
2. FPN
FPN是为目标检测设计的,利用CNN中固有的多尺度特征,提取更加鲁棒的特征。

考虑到内存,只上采样到1/2大小。
FPN:
_, C2, C3, C4, C5 = resnet_graph(input_image, "resnet50", stage5=True)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5)
3. U-Net
更多用于医学图像分割。在上采样过程中使用concatenate,将encoder和decoder中相同分辨率大小的特征级联,丰富网络表达能力。

U-Net:
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
# upsample to concatnation
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
4. UNet +
UNet plus版本。a full-scale connected 全尺度连接包含不同尺度的低层细节信息和高层语义信息;学习分层表示从全规模聚合的特征图中。
改进skip connected,旨在减少semantic gap.


5. DeepLab 空洞卷积
空间金字塔池化通过多种感受野得到多尺度上下文信息,encoder-decoder结构通过逐步恢复空间信息得到更清晰的物体边界。


Atrous Spatial Pyramid Pooling, or ASPP:
b0=Conv2D(256,(1,1),padding="same",use_bias=False)(x)
b0=BatchNormalization()(b0)
b0=Activation("relu")(b0)
# dilation convolution
b1=DepthwiseConv2D((3,3),dilation_rate=(6,6),padding="same",use_bias=False)(x)
b1=BatchNormalization()(b1)
b1=Activation("relu")(b1)
b1=Conv2D(256,(1,1),padding="same",use_bias=False)(b1)
b1=BatchNormalization()(b1)
b1=Activation("relu")(b1)
b2=DepthwiseConv2D((3,3),dilation_rate=(12,12),padding="same",use_bias=False)(x)
b2=BatchNormalization()(b2)
b2=Activation("relu")(b2)
b2=Conv2D(256,(1,1),padding="same",use_bias=False)(b2)
b2=BatchNormalization()(b2)
b2=Activation("relu")(b2)
b3=DepthwiseConv2D((3,3),dilation_rate=(12,12),padding="same",use_bias=False)(x)
b3=BatchNormalization()(b3)
b3=Activation("relu")(b3)
b3=Conv2D(256,(1,1),padding="same",use_bias=False)(b3)
b3=BatchNormalization()(b3)
b3=Activation("relu")(b3)
out_shape=int(input_shape[0]/out_stride)
b4=AveragePooling2D(pool_size=(out_shape,out_shape))(x)
b4=Conv2D(256,(1,1),padding="same",use_bias=False)(b4)
b4=BatchNormalization()(b4)
b4=Activation("relu")(b4)
b4=BilinearUpsampling((out_shape,out_shape))(b4)
x=Concatenate()([b4,b0,b1,b2,b3])
return x
6. HRNet 并联结构
HRNet 学到的高分辨率表示不仅在语义上很强,而且在空间上也很精确。这来自两个方面。
1,将高分辨率到低分辨率的卷积流并行连接起来,而不是串联连接。因此能够保持高分辨率,而不是从低分辨率中恢复高分辨率,表示学习在空间上更加精确。
2,大多现有融合方案为 high-resolution low-level and upsampled low-resolution high-level representations。相反,HRNet 重复多分辨率融合,在低分辨率表示的帮助下提高高分辨率表示,反之亦然。因此,所有高分辨率到低分辨率的表示在语义上都更强。

7. SETR Transformer + CNN
使用Transformer作为Encoder,CNN完成Decoder,并将多级特征融合。

8. TransFuse
Transformer + CNN, two-branch structure, novel fusion technique, etc.
以更浅的网络获取更多的全局信息,且不损失低层局部信息。

新的特征融合技术 BiFusion


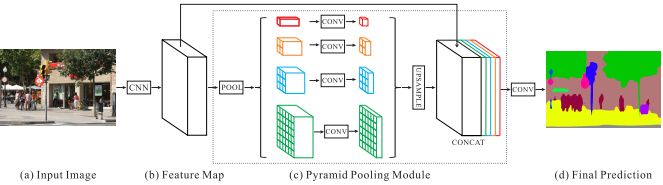
9. PSPNet
P
y
r
a
m
i
d
S
c
e
n
e
P
a
r
s
i
n
g
N
e
t
w
o
r
k
Pyramid Scene Parsing Network
PyramidSceneParsingNetwork
10. DLA


R
e
s
U
n
e
t
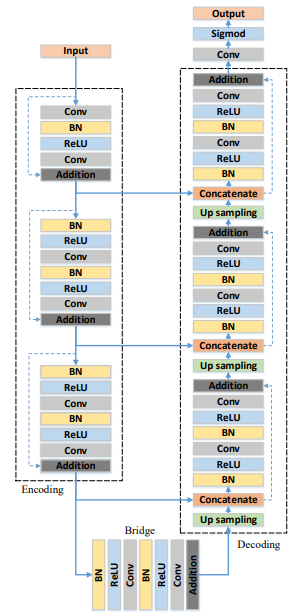
ResUnet
ResUnet:

















 8601
8601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











