







目录
数据并行技术
数据并行(Data Parallel, DP)是一种常用的深度学习训练策略,它通过在多个 GPU 上分布数据来实现并行处理。在数据并行的框架下,每个 GPU(或称作工作单元)都会存储模型的完整副本,这样每个 GPU 都能独立地对其分配的数据子集进行前向和反向传播计算。

工作流程
-
参数同步:在开始训练之前,所有的工作单元同步模型参数,确保每个 GPU 的模型副本是相同的。
-
分配数据:训练数据被划分为多个批次,每个批次进一步被分割成多个子集,每个 GPU 负责处理一个数据子集。
-
独立计算梯度:每个 GPU 独立地对其数据子集进行前向传播和反向传播,计算出相应的梯度。
-
梯度聚合:计算完成后,所有工作单元的梯度需要被聚合起来。这通常通过网络通信来实现,比如使用 All-Reduce 算法,它允许在不同的 GPU 间高效地计算梯度的平均值。
-
更新参数:一旦梯度被平均,每个 GPU 使用这个平均梯度来更新其模型副本的参数。
-
重复过程:这个过程在每个数据批次上重复进行,直到模型在整个数据集上训练完成。
优势和挑战
数据并行可以允许训练过程水平扩展到更多的 GPU 上,从而加速训练。其优势是实现简单,而且可以灵活的调整工作单元的数量来适应可用的硬件资源,当前多种深度学习框架提供了内置支持。不过数据并行随着并行的 GPU 数量增加,需要存储更多的参数副本,这会导致显著的内存开销。此外,梯度聚合步骤需要在 GPU 之间同步大量数据,这可能成为系统的瓶颈,特别是当工作单元的数量增多时。
为了解决数据并行中的通信瓶颈问题,研究者们提出了各种异步同步方案。在这些方案中,每个 GPU 工作线程可以独立于其他线程处理数据,无需等待其他工作线程完成其梯度计算和同步。这种方法可以显著降低因通信导致的停滞时间,从而提高系统的吞吐量。
其实现原理为,在梯度计算阶段,每个 GPU 在完成自己的前向和反向传播后,不等待其他 GPU,立即进行梯度更新。其次,每个 GPU 在需要时读取最新可用的全局权重,而不必等待所有 GPU 达到同步点。然而,这种方法也有其缺点。由于不同 GPU 上的模型权重可能不同步,工作线程可能会使用过时的权重进行梯度计算,这可能导致统计效率的降低,即精度上无法严格保证。
分类
根据模型在设备之间的通信程度,数据并行技术可以分为 DP, DDP, FSDP 三种。
PyTorch 分布式数据并行 (DDP) 简介
- Data parallelism, DP 数据并行
数据并行是最简单的一种分布式并行技术,具体实施是将大规模数据集分割成多个小批量,每个批量被发送到不同的计算设备(如 NPU)上并行处理。每个计算设备拥有完整的模型副本,并单独计算梯度,然后通过 all_reduce 通信机制在计算设备上更新模型参数,以保持模型的一致性。
- Distribution Data Parallel, DDP 分布式数据并行
DDP 是一种分布式训练方法,能够在 PyTorch 中实现数据并行训练。它允许模型在多个计算节点上进行并行训练,每个节点都有自己的本地模型副本和本地数据。DDP 通常用于大规模的数据并行任务,其中模型参数在所有节点之间同步,在 PyTorch 中,DistributedSampler 确保每个设备都获得不重叠的输入批次。
在 DDP 中,每个节点上的模型副本都会执行前向和后向传播计算,并计算梯度,并使用ring all-reduce algorithm算法与其他副本同步。这些梯度在不同的节点之间进行通信和平均,以便所有节点都可以使用全局梯度来更新其本地模型参数。这种方法的优点是可以扩展到大量的节点,并且可以显著减少每个节点的内存需求,因为每个节点只需要存储整个模型的一个副本。
DDP 通常与深度学习框架(如 PyTorch)一起使用,这些框架提供了对 DDP 的内置支持。例如,在 PyTorch 中,torch.nn.parallel.DistributedDataParallel 模块提供了 DDP 实现,它可以自动处理模型和梯度的同步,以及分布式训练的通信。
为什么应该优先选择 DDP 而不是 DataParallel (DP)
DataParallel是一种较旧的数据并行方法。DP 实现起来非常简单(只需额外添加一行代码),但性能要差得多。DDP 在架构上进行了一些改进:
| 特性 | DataParallel | DistributedDataParallel |
|---|---|---|
| 模型复制 | 每次前向传递都会复制和销毁模型 | 只复制模型一次 |
| 并行支持 | 只支持单节点并行 | 支持扩展到多台机器 |
| 速度 | 较慢;在单个进程上使用多线程,并会遇到全局解释器锁 (GIL) 争用 | 较快(没有 GIL 争用),因为它使用多进程 |
- Fully Sharded Data Parallel, FSDP 全分片数据并行
Fully Sharded Data Parallelism (FSDP) 技术是 DP 和 DDP 技术的结合版本,可以实现更高效的模型训练和更好的横向扩展性。这种技术的核心思想是将神经网络的权重参数以及梯度信息进行分片(shard),并将这些分片分配到不同的设备或者计算节点上进行并行处理。FSDP 分享所有的模型参数,梯度,和优化状态。所以在计算的相应节点需要进行参数、梯度和优化状态数据的同步通信操作。
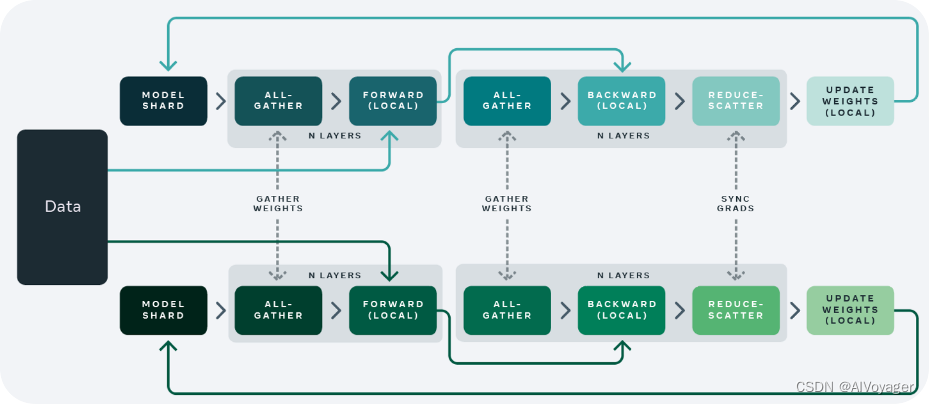
如上图是 FSDP 并行技术的示意图,可以看到不同的计算节点多了一些虚线链接的通信操作。
DP与DDP
Pytorch为分布式训练提供了两种设置:torch.nn.DataParallel (DP) 和torch.nn.parallel.DistributedDataParallel (DDP),其中后者是官方推荐的。
DistributedDataParallel (DDP)实现了模块级的数据并行,可以在多台机器上运行。使用DDP的应用程序应该产生多个进程,并为每个进程创建一个DDP实例。DDP在torch中使用 torch.distributed中的collective communications用于同步gradients和buffers。更具体地说,DDP为model.parameters()给出的每个参数注册一个autograd钩子,该钩子将在反向传递中计算相应的梯度时触发。然后DDP使用该信号来触发跨进程的梯度同步。推荐使用DDP的方式是为每个模型副本生成一个进程,其中模型副本可以跨越多个设备。DDP进程可以放置在同一台机器上或跨机器,但GPU设备不能跨进程共享。
DataParallel和DistributedDataParallel的比较
首先,DataParallel是单进程、多线程的,只适用于单机器,而DistributedDataParallel是多进程的,适用于单机器和多机器训练。即使在单台机器上,DataParallel通常也比DistributedDataParallel慢,这是因为线程之间的GIL竞争、每次迭代的复制模型以及分散输入和收集输出所引入的额外开销。如果你的模型太大,不能放在单个GPU上,你必须使用model parallel将它划分到多个GPU上DistributedDataParallel支持模型并行;DataParallel目前没有这种特性。当DDP与model parallel结合使用时,每个DDP进程使用model parallel,所有进程共同使用data parallel。
总之,DDP比DP更快、更灵活,支持模型并行和数据并行。
对于torch.nn.parallel.DataParallel直接弃用,其源代码给出了建议。
.. warning::
It is recommended to use :class:`~torch.nn.parallel.DistributedDataParallel`,
instead of this class, to do multi-GPU training, even if there is only a single
node. See: :ref:`cuda-nn-ddp-instead` and :ref:`ddp`.
torch.nn.parallel.DistributedDataParallel(module,
device_ids=None,
output_device=None,
dim=0,
broadcast_buffers=True,
process_group=None,
bucket_cap_mb=25,
find_unused_parameters=False,
check_reduction=False)
参数解析
- module:要进行分布式并行的 module,一般为完整的 model。
- device_ids:int 列表或 torch.device 对象,用于指定要并行的设备。
对于数据并行,即完整模型放置于一个 GPU 上(single-device module)时,需要提供该参数,表示将模型副本拷贝到哪些 GPU 上。
对于模型并行,即一个模型,分散于多个 GPU 上的情况(multi-device module),以及 CPU 模型,该参数比必须为 None,或者为空列表。与单机并行一样,输入数据及中间数据,必须放置于对应的,正确的 GPU 上。 - output_device:int 或者 torch.device。对于 single-device 的模型,表示结果输出的位置。对于 multi-device module 和 GPU 模型,该参数必须为 None 或空列表。
- broadcast_buffers:bool 值,默认为 True。表示在 forward() 函数开始时,对模型的 buffer 进行同步 (broadcast)。
- process_group:对分布式数据(主要是梯度)进行 all-reduction 的进程组。默认为 None,表示使用由 torch.distributed.init_process_group 创建的默认进程组 (process group)。
DDP实现数据并行
如果模型可以放在一个gpu(它可以在batch_size=1的gpu上进行训练),并且我们想在K个gpu上train/test,DDP的最佳实践是将模型复制到K个gpu上(DDP类自动为您完成此工作),并将dataloader划分为K个不重叠的组,分别输入到K个模型中。
- 设置进程组,这是三行代码,不需要修改;
import torch.distributed as dist
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl", rank=rank, world_size=world_size)
- 将dataloader拆分到组中的每个进程中,这可以通过
torch.utils.data.DistributedSampler或任何定制的sampler实现;
DDP中DistributedSampler保证测试数据集加载固定顺序,且在各个程序中都是一样时(因为shuffle=True时使用了随机种子,不保证在各个程序中测试数据集加载顺序都是一样),最好在DistributedSampler中保证参数shuflle=False,训练集需要保证shuffle=True(DistributedSampler中默认shuffle参数是True)。
DDP中在DataLoader中需要保证测试数据集和训练数据集都是shuffle=False(参数shuflle默认是False),因为有了sampler进行数据采样,如果shuffle=True会与sampler进行采样冲突,出现报错(DataLoader中默认shuflle参数是False)。如果不是DDP,则需要保证训练数据集的dataloader中shuffle参数是True,测试数据集的dataloader中shuffle参数是False。
from torch.utils.data.distributed import DistributedSampler
def prepare(rank, world_size, batch_size=32, pin_memory=False, num_workers=0):
dataset = Your_Dataset()
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=False, drop_last=False)
dataloader = DataLoader(dataset, batch_size=batch_size, pin_memory=pin_memory, num_workers=num_workers, drop_last=False, shuffle=False, sampler=sampler)
return dataloader
- 用DDP包装我们的模型,只需一行代码,几乎不需要修改;
将模型移动到特定的gpu,然后用DDP类包装它。下面的函数接受一个参数rank,rank等于gpu id。
from torch.nn.parallel import DistributedDataParallel as DDP
def main(rank, world_size):
# setup the process groups
setup(rank, world_size)
# prepare the dataloader
dataloader = prepare(rank, world_size)
# instantiate the model(it's your own model) and move it to the right device
model = Model().to(rank)
# wrap the model with DDP
# device_ids tell DDP where is your model
# output_device tells DDP where to output, in our case, it is rank
# find_unused_parameters=True instructs DDP to find unused output of the forward() function of any module in the model
model = DDP(model, device_ids=[rank], output_device=rank, find_unused_parameters=True)
当我们想访问DDP包装模型的一些自定义属性时,必须使用model.module。也就是说,我们的模型实例被保存为DDP模型的module属性。如果我们将某些属性赋值xxx而不是内置属性或函数,则必须通过model.module.xxx访问它们。
# save
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
---------------------------------------------------------------
# load
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
当我们保存DDP模型时,state_dict会为所有参数添加一个模块前缀。因此,如果我们想将保存了DDP的模型加载到非DDP模型中,我们必须手动去除额外的前缀。
# in case we load a DDP model checkpoint to a non-DDP model
model_dict = OrderedDict()
pattern = re.compile('module.')
for k,v in state_dict.items():
if re.search("module", k):
model_dict[re.sub(pattern, '', k)] = v
else:
model_dict = state_dict
model.load_state_dict(model_dict)
- 训练/测试我们的模型,这与在一个gpu上相同;
def main(rank, world_size):
# setup the process groups
setup(rank, world_size)
# prepare the dataloader
dataloader = prepare(rank, world_size)
# instantiate the model(it's your own model) and move it to the right device
model = Your_Model().to(rank)
# wrap the model with DDP
# device_ids tell DDP where is your model
# output_device tells DDP where to output, in our case, it is rank
# find_unused_parameters=True instructs DDP to find unused output of the forward() function of any module in the model
model = DDP(model, device_ids=[rank], output_device=rank, find_unused_parameters=True)
#################### The above is defined previously
optimizer = Your_Optimizer()
loss_fn = Your_Loss()
for epoch in epochs:
# if we are using DistributedSampler, we have to tell it which epoch this is
# https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler
dataloader.sampler.set_epoch(epoch)
for step, x in enumerate(dataloader):
optimizer.zero_grad(set_to_none=True)
pred = model(x)
label = x['label']
loss = loss_fn(pred, label)
loss.backward()
optimizer.step()
cleanup()
import torch.multiprocessing as mp
if __name__ == '__main__':
# suppose we have 3 gpus
world_size = 3
mp.spawn(
main,
args=(world_size),
nprocs=world_size
)
- 清理进程组(如C中的free),只需一行代码;
def cleanup():
dist.destroy_process_group()
- 可选:在进程之间收集额外的数据,这基本上是一行代码;
有时我们需要从所有过程中收集一些数据,例如测试结果。我们可以轻松地通过dist.all_gather收集张量,通过dist.all_gather_object收集对象。为了不失通用性,我假设我们想收集python对象。对象的唯一限制是它必须是可序列化的,这在python中基本上就是一切。在使用all_gather_xxx之前,应该始终分配torch.cuda.set_device(rank)。而且,如果我们想要在对象中存储一个张量,它必须位于output_device。
def main(rank, world_size):
torch.cuda.set_device(rank)
data = {
'tensor': torch.ones(3,device=rank) + rank,
'list': [1,2,3] + rank,
'dict': {'rank':rank}
}
# we have to create enough room to store the collected objects
outputs = [None for _ in range(world_size)]
# the first argument is the collected lists, the second argument is the data unique in each process
dist.all_gather_object(outputs, data)
# we only want to operate on the collected objects at master node
if rank == 0:
print(outputs)
DDP实现模型并行
DDP也适用于多gpu模型。在训练具有大量数据的大型模型时,DDP包装多gpu模型特别有用。
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
当传递一个多gpu模型给DDP时,device_ids和output_device不能被设置。输入和输出数据将通过应用程序或模型的forward()方法放置到适当的设备中。
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
# setup mp_model and devices for this process
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
# outputs will be on dev1
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
run_demo(demo_basic, world_size)
run_demo(demo_checkpoint, world_size)
world_size = n_gpus//2
run_demo(demo_model_parallel, world_size)
DDP中的amp混合训练

完整案例
import os
gpu_list = "0,1,2,3"
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_list
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.distributed as dist
import time
import torchvision
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()
def is_main_process():
return get_rank() == 0
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
def create_data_loader_cifar10():
transform = transforms.Compose(
[
transforms.RandomCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 256
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset=trainset, shuffle=True)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
sampler=train_sampler, num_workers=16, pin_memory=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
test_sampler = torch.utils.data.distributed.DistributedSampler(dataset=testset, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, sampler=test_sampler, num_workers=16)
return trainloader, testloader
def train(net, trainloader):
print("Start training...")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
epochs = 1
num_of_batches = len(trainloader)
for epoch in range(epochs): # loop over the dataset multiple times
trainloader.sampler.set_epoch(epoch) #
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
images, labels = inputs.cuda(), labels.cuda()
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
print(f'[Epoch {epoch + 1}/{epochs}] loss: {running_loss / num_of_batches:.3f}')
print('Finished Training')
def test(net, PATH, testloader):
# if is_main_process:
# net.load_state_dict(torch.load(PATH))
# dist.barrier()
correct = 0
total = 0
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.cuda(), labels.cuda()
# calculate outputs by running images through the network
outputs = net(images)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct // total
print(f'Accuracy of the network on the 10000 test images: {acc} %')
def init_distributed():
# Initializes the distributed backend which will take care of sychronizing nodes/GPUs
dist_url = "env://" # default
# only works with torch.distributed.launch // torch.run
rank = int(os.environ["RANK"])
world_size = int(os.environ['WORLD_SIZE'])
local_rank = int(os.environ['LOCAL_RANK'])
dist.init_process_group(
backend="nccl",
init_method=dist_url,
world_size=world_size,
rank=rank)
# this will make all .cuda() calls work properly
torch.cuda.set_device(local_rank)
# synchronizes all the threads to reach this point before moving on
dist.barrier()
setup_for_distributed(rank == 0)
if __name__ == '__main__':
start = time.time()
init_distributed()
PATH = './cifar_net.pth'
trainloader, testloader = create_data_loader_cifar10()
net = torchvision.models.resnet50(False).cuda()
# Convert BatchNorm to SyncBatchNorm.
net = nn.SyncBatchNorm.convert_sync_batchnorm(net)
local_rank = int(os.environ['LOCAL_RANK'])
net = nn.parallel.DistributedDataParallel(net, device_ids=[local_rank])
start_train = time.time()
train(net, trainloader)
end_train = time.time()
# save
if is_main_process:
save_on_master(net.state_dict(), PATH)
dist.barrier()
# test
test(net, PATH, testloader)
end = time.time()
seconds = (end - start)
seconds_train = (end_train - start_train)
print(f"Total elapsed time: {seconds:.2f} seconds, \
Train 1 epoch {seconds_train:.2f} seconds")
FSDP
后续更新…
今天,如果你们想进行分布式training & evaluation,就使用transformers.Trainer和accelerate.Accelerator。它们是非常方便的工具,功能远远超过DistributedDataParallel。
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
- https://medium.com/codex/a-comprehensive-tutorial-to-pytorch-distributeddataparallel-1f4b42bb1b51
- https://github.com/pytorch/tutorials/blob/main/intermediate_source/ddp_tutorial.rst
- https://pytorch.org/docs/master/notes/ddp.html
- https://zhuanlan.zhihu.com/p/467103734
- https://github.com/chenzomi12/AISystem















 5495
5495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









