







文章目录
- 1. python基础语法
- 1.1 怎么让两个list或者其它可以迭代的放到一起
- 1.2 random.choice(x, n, replace=True) numpy中从某个数据集中选择
- 1.3 如何根据key返回字典的value
- 1.4 The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
- 1.5 到底是.xxx呢还是.xxx()呢??
- 1.6 list and generator and any(iterable) all(iterable)
- 1.7 globals 获取全局的变量/函数/类
- 1.8 a = a.append(3)这件事
- 1.9 <class "NoneType">
- 1.10时间格式的整理
- 2. numpy
- 3. pandas
- 3.1 查看某行是不是有重复值
- 3.2 df.value_counts(normalize: bool = False,sort: bool = True,ascending: bool = False,bins=None, dropna: bool = True)
- 3.3 报错 Traceback (most recent call last): parser = TextFileReader(filepath_or_buffer, **kwds) self._engine = self._make_engine(self.engine)
- 3.4 存储为csv后科学计数法的问题
- 3.5 读json格式
- 3.6 查看完整的错误信息
- 3.7 多条件索引
- 3.8 读excel某几行
- 3.9 df['xxx'].values
- 3.10 df.dtypes
- 3.11 删除多列同时为0的行
- 3.12创建dataframe的方式
- 3.13 Series访问
- 3.14 iloc和loc
1. python基础语法
1.1 怎么让两个list或者其它可以迭代的放到一起
可以使用zip
可以使用索引
for i in range(len(xxx)):
list[i]
1.2 random.choice(x, n, replace=True) numpy中从某个数据集中选择
不是随机random.int() 而是从既有数据集中选择!
1.3 如何根据key返回字典的value
精髓就在于,直接封装成方法!
这样就可以直接调用了!!
def return_key(levels_dict, target):
for key, value in levels_dict.items():
if value == target:
return key
return "ERROR"
return_key(levels_dict, val)
1.4 The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。
注意针对的是可迭代的对象!
1.5 到底是.xxx呢还是.xxx()呢??
是不是经常会有疑问,到底加不加括号!
其实这个可以通过经验来获得!
如果我们想返回的是值,比如df.columns,那么多半是不加括号的;
而如果是一个功能,比如sort,那么就需要加括号
1.6 list and generator and any(iterable) all(iterable)
如果是any和all则选用generator
因为只要判断了第一个满足条件或者不满足条件就可以返回了,list则要全部访问完
any(i for i in range(n)) # 就是一个括号
any([i for i in range(n)])
1.7 globals 获取全局的变量/函数/类
一句话: 就是会返回所有全局变量的一个字典, key值为该变量的命名;
这里的全局变量包含了:
**导入的包! 导入的函数! **
如果是在某个函数中,则包含了局部变量(参数);
如果是在类中,则包含了定义的实例变量.
在调用的时候,由于globals()是一个字典,所以先加key值,再写参数
train_dataset = globals()[dataset_name](
conf, conf.data.train_json_files, generate_dict=True)
1.8 a = a.append(3)这件事
loc_level = [level_levelid[i][0] for i in range(idx+1)]\
.append(ll[1])
print(loc_level) # None
## 正确
loc_level = [level_levelid[i][0] for i in range(idx+1)]
loc_level .append(ll[1])
print(loc_level) #
好像没错,但是其实错了 ! 因为这个时候a被赋值是append()函数
这个函数是inplace的,不需要重新定义,没有返回值,肯定为None
1.9 <class “NoneType”>
一般是函数的输出会是NoneType
判断方式:
a is None
1.10时间格式的整理
时间格式转换 str --> datetime or datetime --> str
需要的函数:
import datetime
时间格式的加减(加秒/加小时/加天/周/月等)
datetime.timedelta(
[days
[, seconds
[, microseconds
[, milliseconds
[, minutes
[, hours
[, weeks
]]]]]]])
now=datetime.datetime.now()
now
datetime.datetime(2018, 1, 20, 11, 5, 18, 227000)
delta=datetime.timedelta(days=1)
delta
datetime.timedelta(1)
newtime=now+delta
时间格式的提取(比如将dataframe中某一列设为周)
2. numpy
2.1 numpy中如何使得维度降低维度
降低维度到1维
x = x.reshape(-1)
x = x.flatten()
2.2. np.bincount()
-
解释
这是一个加权对同类累加的函数 ! 当然是同类的加权! 同时是降序返回 -
参数
x
weights(optional): array of the same shape asx,默认是1
minlength(optional): -
举例
x: array([2, 2, 0, 2, 0, 0, 1, 1, 2, 1, 1, 0, 1, 1, 0, 1, 2, 2, 0])
weights: array([0.4, 0.4, 0.2,0.2, …])
x * weights 后对同类进行累加并返回
所以返回的是三个数 [x_1, x_2, x_3] 2/1、0的加权和
- 应用场景
一般用在求概率上!
比如gini系数!
def gini(y):
# Gini impurity (local entropy) of a label sequence
hist = np.bincount(y)
N = np.sum(hist)
return 1 - sum([(i / N) ** 2 for i in hist])
2.3 numpy里的高级索引
- 支持索引查找
x[[1,2,3], [2,3,4]]
或者是x[1,2,3] 表示取的是array x的索引为1,2,3的数组
2.4. np.unique()
去重以及排序
2.5 re.sub(pattern, repl, string, count=0, flags=0)
re.sub的参数:5个参数
参数1:pattern
表示正则中的模式字符串。
参数2:repl
就是replacement,表示被替换的字符串,可以是字符串也可以是函数。
参数3:string
表示要被处理和替换的原始字符串
参数4:count
可选参数,表示是要替换的最大次数,而且必须是非负整数,该参数默认为0,即所有的匹配都会被替换;
参数5:flags
可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
import re
re.sub('[,]', ',', str1) #
a = ' (rr 我)#1 (d 只是)#1 (p 以)#1 (vi 笑) (v 作答)#1#2#3 (。 。)'
a = re.sub(u"[\u4e00-\u9fa5]+", '*', a) # 匹配多个连续汉字,替换为*
2.6 设置展示行(列也是同理的,可以自己去查)
pd.options.display.max_rows = None
pd.set_option('display.max_rows', 200)
每次运行前都要重新设置!
2.7 ~的作用
~就是取反,只能用于numpy,list是不行的! 当然用到dataframe也是可以的,因为它每个单元格都是ndarray
~np.array([True, ])
3. pandas
3.1 查看某行是不是有重复值
是否有重复行
any(df.duplicated())
可以用于某一列有重复值
查看重复的行
df[df.duplicated()]
去除重复行
df.drop_duplicats(subset = [‘price’,‘cnt’],keep=‘last’,inplace=True)
drop_duplicats参数说明:
subset subset用来指定特定的列,默认所有列
keep keep可以为first和last,表示是选择最前一项还是最后一项保留,默认first
inplace inplace是直接在原来数据上修改还是保留一个副本,默认为False
3.2 df.value_counts(normalize: bool = False,sort: bool = True,ascending: bool = False,bins=None, dropna: bool = True)
记住返回的是series! int类型,虽然显示的是text + id
还可以实现mean!
Examples
--------
>>> index = pd.Index([3, 1, 2, 3, 4, np.nan])
>>> index.value_counts()
3.0 2
1.0 1
2.0 1
4.0 1
dtype: int64
With `normalize` set to `True`, returns the relative frequency by
dividing all values by the sum of values.
>>> s = pd.Series([3, 1, 2, 3, 4, np.nan])
>>> s.value_counts(normalize=True)
3.0 0.4
1.0 0.2
2.0 0.2
4.0 0.2
dtype: float64
**bins**
Bins can be useful for going from a continuous variable to a
categorical variable; instead of counting unique
apparitions of values, divide the index in the specified
number of half-open bins.
>>> s.value_counts(bins=3)
(0.996, 2.0] 2
(2.0, 3.0] 2
(3.0, 4.0] 1
dtype: int64
**dropna**
With `dropna` set to `False` we can also see NaN index values.
>>> s.value_counts(dropna=False)
3.0 2
1.0 1
2.0 1
4.0 1
NaN 1
dtype: int64
"""
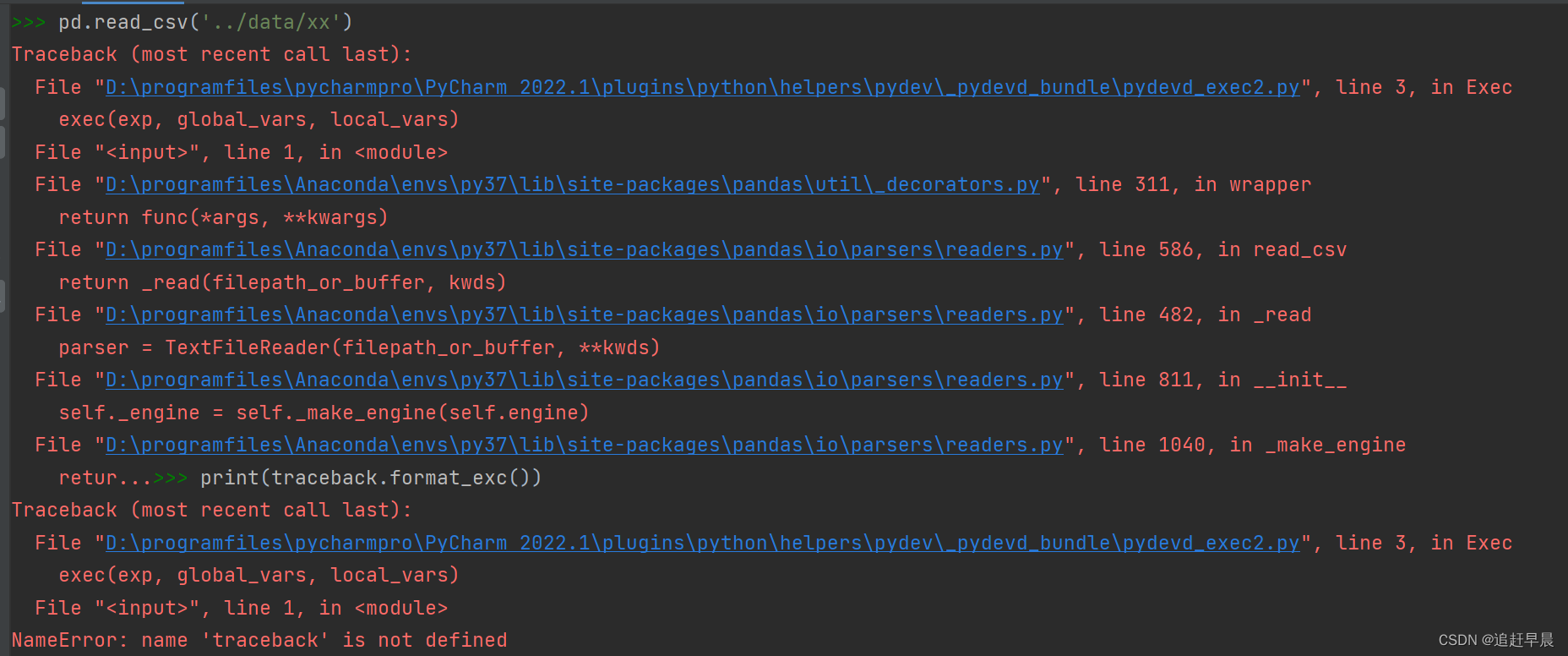
3.3 报错 Traceback (most recent call last): parser = TextFileReader(filepath_or_buffer, **kwds) self._engine = self._make_engine(self.engine)
- 错误分析
这是因为pd.read_csv()代码运行出错!
最可气的是出现上面的错误,pandas不显示全部的出错信息,而且出奇的一致,你也不知道你哪个参数写错了!
但是注意这里出错只有一种可能是你的参数写错了!
- 运行代码
pd.read_csv('../data/type_count2.csv', encoding='GBK')
或者
pd.read_csv('../data/type_count2.csv', encoding='utf-8')
或者
pd.read_csv('../data/type_count2.csv', encoding='utf-8', sep='\t')
-
出错原因:
-
第一: 最重要的看看路径!!!!
一般都是路径引起的!! 给我回去一层一层的看 -
第二: encoding
如果上面没有错误,那么请看编码问题! UTF-8或者是GBK -
第三: sep
默认是逗号,如果有问题,一定尝试别的’\t’ -
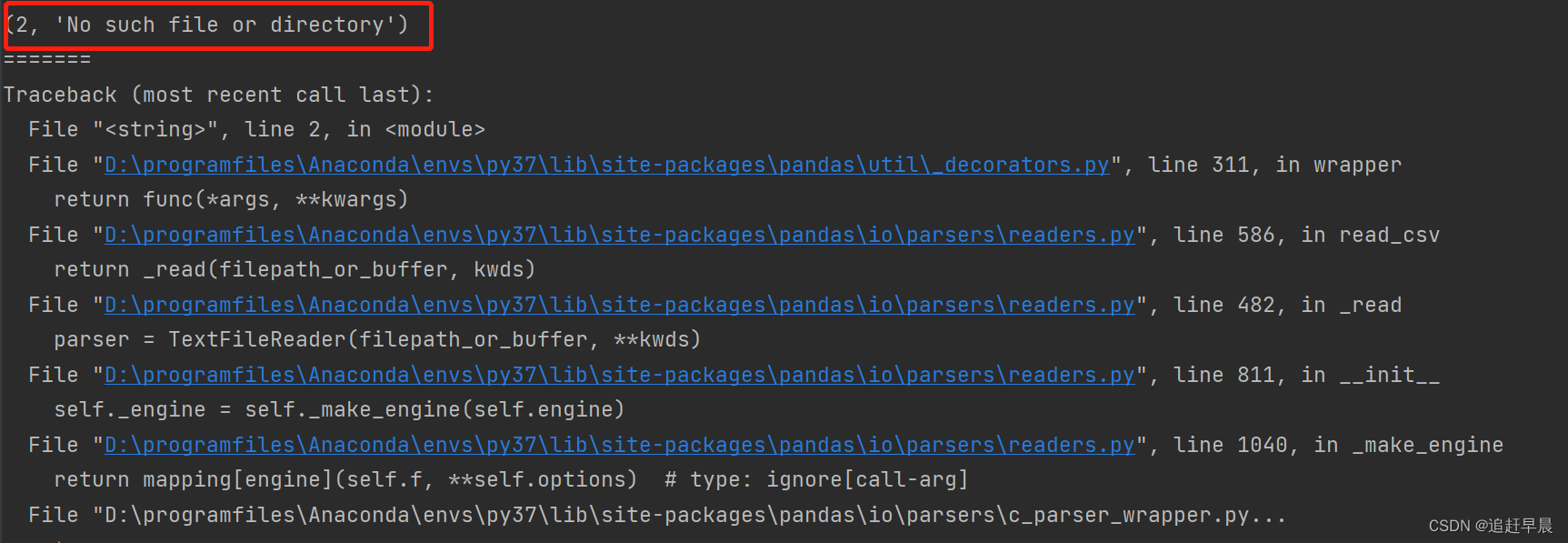
小技巧:查看完整错误信息
try:
pd.read_csv('../data/xx')
except Exception as e:
print(e.args)
print('=======')
print(traceback.format_exc())
3.4 存储为csv后科学计数法的问题
- 场景分析
主要是想保存csv或者是excel,但是某一列既有字符串,又有(int),而且int还是长int; 由于csv中自动保存使用科学计数法!
这是csv或者excel的显示问题,不是

方法解决:
- 方法一:就这样吧
链接
Excel打开CSV数字显示为科学计数法解决办法
压根不要着急! 虽然它在csv或者是excel中是科学计数法,但是精度并没有丢失!!!!!!
前提是你不要点ctrl+s;
你读的时候数据还是原封不动的,所以没有必要慌张
如果点ctrl+S保存,会直接保存更改精度后的数据!!
- 方法二:转变csv的格式
如果真的想保存为非科学计数法,可以尝试这个方法
分隔符选择为’,'(因为to_csv默认是逗号)

注意三列都需要设置哦!!!
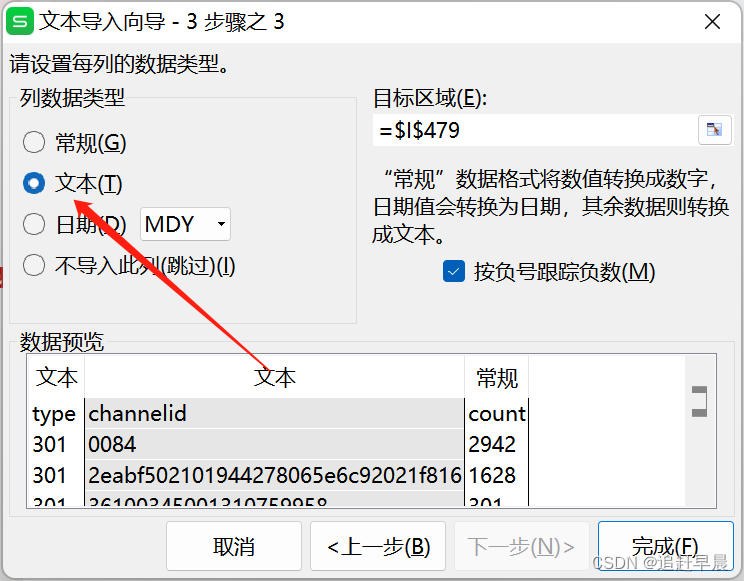
这样就可以了!!
- 方法三:保存为txt格式
这种直接保存为txt格式,就不会受到csv格式的制约了!
df_.to_csv('tt.txt', endoing='utf-8', sep='\t')
- 方法四: 对每一行多一个字符
如果我们在保存的时候多加一个字符自动转为字符串!
注意,就算我们使用
df['xxx'] = df['xxx'].astype(str)
或者是
df['xxx'] = df['xxx'].apply(lambda x: str(x))
都是无济于事的
因为它本来就是str,但是在转为csv的时候还是会以同样的方式把它认为int! giao!
所以要这样
# 写端:
df['xxx'] = df['xxx'].apply(lambda x: str(x) + '\t')
或者是
df['xxx'] = df['xxx'].apply(lambda x: str(x) + ' ')
# 读端:
df['xxx'] = df['xxx'].apply(lambda x: s.strip()
这样你保存的时候就不会显示为科学计数法了!!
3.5 读json格式
panads同样可以读json! 不需要用json.loads(xxx)
前提:json中每个字典对象都要有相同的ziduan
with open('tt.json', 'r', encoding='utf-8') as file:
json_info = file.read()
df = pd.read_json(json_info)
- groupby + reset_index + sort_values
df2_ = df.groupby(['channelid','type',])['count'].sum().reset_index().sort_values(['type', 'count'], ascending=False)
使用某两列进行分组生成了groupby对象,该对象以[‘channelid’,‘type’] 为索引, 属性是其它属性,然后再对count列求和!!!
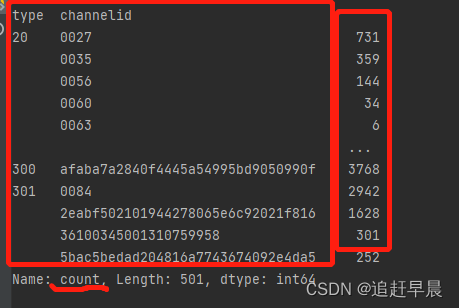
reset_index()使得index为列!
再以两列排序!!
3.6 查看完整的错误信息
try:
pd.read_csv('../data/xx')
except Exception as e:
print(e.args)
print('=======')
print(traceback.format_exc())
3.7 多条件索引
必须使用 “&”, 而不是and
data_counts[(data_counts['数量']>100) & (data_counts['数量']<500)]
3.8 读excel某几行
pandas.read_excel(io,
sheet_name=0,
header=0, # 第几行为列名
names=None, # 新的列名
index_col=None,
usecols=None, # 几列
squeeze=False,
dtype=None,
engine=None,converters=None,true_values=None,
false_values=None,
skiprows=None, # 跳过第几行
nrows=None, # 读多少行
na_values=None,keep_default_na=True,
verbose=False,parse_dates=False,date_parser=None,
thousands=None,
comment=None,skip_footer=0,skipfooter=0,
convert_float=True,mangle_dupe_cols=True,**kwds)
如果只读某几行,比如第一行我们是不需要的,那么就skiprows = 1

3.9 df[‘xxx’].values
- dataframe格式
我们在展示某列的时候不想要其index,只想获得值,这个时候就可以使用values - series格式
其实,某一列就是要给series,series就相当于是一个有index的array,当取values的时候,就和array一样的!
3.10 df.dtypes
展示df每一列的数据类型
3.11 删除多列同时为0的行
dropna: 用于删除异常值的,包含NA的
drop: 同上
columns = ['xx', 'xxx', ....]
data[(data.loc[:, columns]!=0).any(1)] #
any() : 用于判断一个迭代对象是不是全部为True,否则为False
any(iterable)
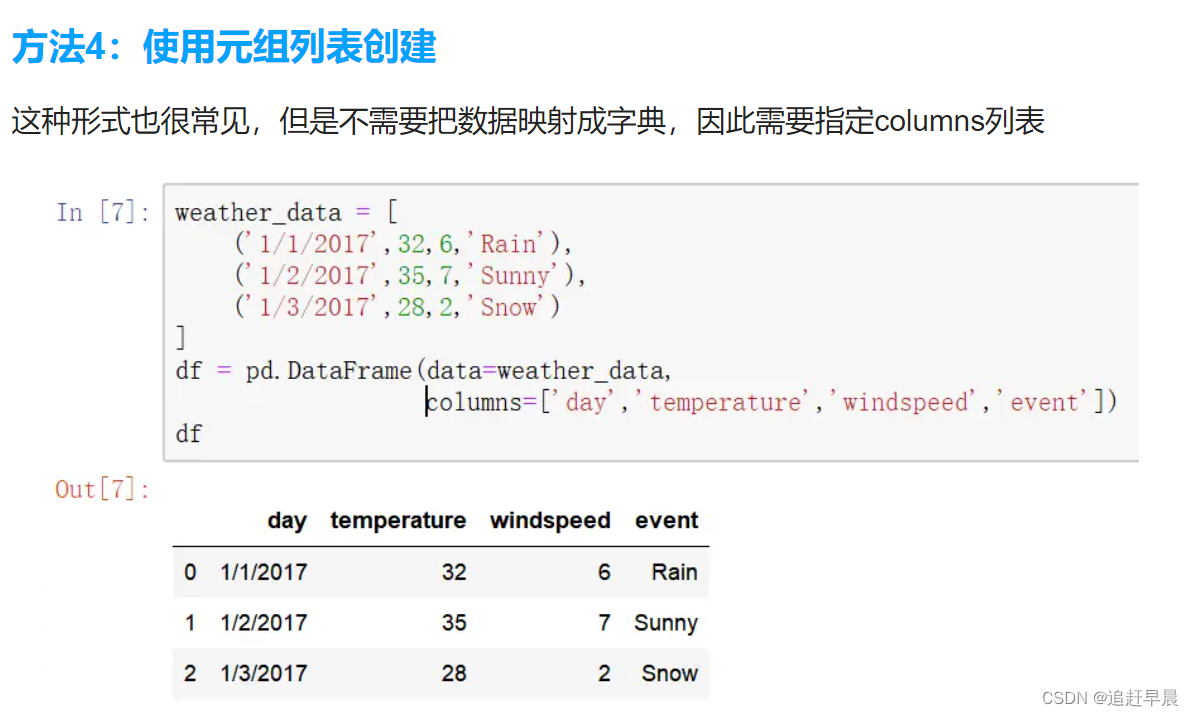
3.12创建dataframe的方式

3.13 Series访问
series的索引访问! 都说series和ndarray一样, 但是其实也不一样! 因为ndarray通过切片下标来高级索引, 但是series还是得通过iloc或者loc****索引访问;
其次要清楚, 索引(高级索引)返回的是拷贝;
而切片访问返回的是视图!!!
series.iloc[[x, x, xx, x]] # 只需要写一个行就行,不需要全部!
3.14 iloc和loc
iloc和loc都是通过所以来获取值的! 也就是行索引和列索引!
如果是完全根据索引顺序访问, 每次在访问的时候一定要reset_index一下!
如果本身索引带了类别属性, 那么就自己考虑吧














 3435
3435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









