







文章目录
- 1. sklearn
- 3. scipy
- 4. cv2
1. sklearn
sklearn类库基于Numpy 和 Scipy构建;
Numpy拓展了Python以支持大数组和多维矩阵更高效的操作(基本元素都是array);
Scipy提供了用于科学计算的模块;(有出名的稀疏矩阵)
matplotlib也经常会联合一起使用
包含了转换器和估计器
1.1 sklearn.preprocessing 之 fit 和 transform 以及 fit_transform
这三个方法是所有特征预处理中都会有的!
sklearn.preprocessing 中都是保存了各种特征处理函数!
里面主要是fit 和 transform以及 fit_transform
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
lb = LabelBinarizer()
y_train_binarized = lb.fit_transform(y_train)
y_train_binarized
# Out[5]:
array([[1],
[1],
[1],
[0],
[0]])
- fit
fit方法进行了一些转换准备工作,比如将标签字符串映射成整数; - transform
将映射关系运用于输入标签(Y_train) - fit_transform
同时调用fit和transform
1.2 算法之 fit 和 predict和predict_proba
每一个估计器(也就是每个算法),估计器基于观测到的数据预测一个值,在scikit-learn中,所有的估计器都实现了fit方法和predict方法。
前者实现了学习模型的参数,并且返回实例本身(self)!
precit_proba则是将
predict则是将predict_proba的结果进行排序输出
1.3 predict_proba
1.4 各种评测指标
1.4.1 R 2 R^2 R2
- 概述
R
2
R^2
R2 R方,被称为决定系数,它用来衡量数据和回归线的贴近程度;
在线性回归模型中,R方等于皮尔森积数相关系数的平方,也称为皮尔森相关系数r的平方。
R方对异常值很敏感,当新的特征增加到模型中时,它常常会异样的增长。
首先计算平方总和:
S
S
t
o
t
=
∑
i
=
1
n
(
y
i
−
y
‾
)
SS_{tot}=\sum_{i=1}^n(y_i-\overline{y})
SStot=i=1∑n(yi−y)
后者为观测值的均值
再次计算RSS:
S
S
r
e
s
=
∑
i
=
1
n
(
y
i
−
f
(
x
i
)
SS_{res}=\sum_{i=1}^n(y_i-f(x_i)
SSres=i=1∑n(yi−f(xi)
后者为预测值
R
2
=
1
−
S
S
r
e
s
S
S
t
o
t
R^2=1-\frac{SS_{res}}{SS_{tot}}
R2=1−SStotSSres
- 代码:
代码和其它的指标是不一样的!
这里没有预测标签! 而且只用在线性回归中
model = LinearRegression()
model.fit(X_train, y_train)
r_squared = model.score(X_test,y_test)
1.4.2 准确度、精准率、召回率
这几个的解释,请移步这里
注意第一个是y_test真实值, y_precit是预测值
from sklearn.preprocessiong import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, precision_score, matthews_corrcoef, classification_report
from sklearn.metrics import accuracy_score
# 给定原数据(二分类),如果类别没有转为数字,那么我们可以使用LabelBinarizer
# 来转换; 它的解释在上面
lb = LabelBinarizer()
y_train_binarized = lb.fit_transform(y_train)
clf = KNeighborsClassifier(n_neighbors=K)
clf.fit(X_train, y_train_binarized.reshape(-1)) #看情况需要不需要变换维度
predictions_binarized = clf.predict(X_test)
# 准确率
accuracy= accuracy_score(y_test_binarized, predictions_binarized )
# 精准率
# 混淆矩阵竖着看,预测为正的样本中,预测正确的为多少! 分母为预测为正的所有样本
precision = precision_score(y_test_binarized, predictions_binarized )
# 召回率
# 混淆矩阵横着看,真实标签就为正的样本中,预测正确的为多少! 分母是真实标签就为正的! 所有和精确率的区别就是分母不同
recall = recall_score(y_test_binarized, predictions_binarized)
# F1得分
# 用一个变量来总结精准率和召回率,这是一个统计变量
f1_score = f1_score(y_test_binarized, predictions_binarized)
# MCC 马修斯相关系数
# 是除F1得分之外,另一种对二元分类器性能进行衡量的选择,一个完美分类器的MCC值为1,随机预测的分类器得分为0; 完全预测错误为-1。即使类别不平衡,MCC也很用。
m_corrcoef = matthews_corrcoef(y_test_binarized, predictions_binarized)
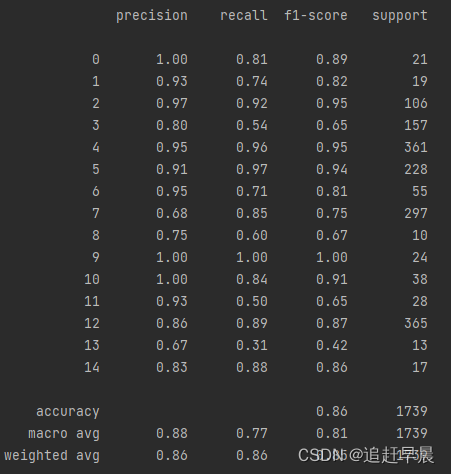
# classification_report 用于生成精准率、召回率和F1得分报表
c_report = classification_report (y_test_binarized, predictions_binarized, target_name=['male'], labels=[1]) # 表示的是正例的分类报告; 在最后一行会展示平均值
下图展示的是多分类的分类报告
1.4.3 平均绝对误差(MAE)和均方误差(MSE)
M
A
E
=
1
n
∑
i
=
0
n
−
1
∣
y
i
−
y
^
∣
MAE=\frac{1}{n}\sum_{i=0}^{n-1}|y_i-\widehat{y}|
MAE=n1i=0∑n−1∣yi−y
∣
A: Absolute
M
A
E
=
1
n
∑
i
=
0
n
−
1
(
y
i
−
y
^
)
2
MAE=\frac{1}{n}\sum_{i=0}^{n-1}(y_i-\widehat{y})^2
MAE=n1i=0∑n−1(yi−y
)2
S:square
对于回归模型,忽略误差的方向非常重要,否则一个回归模型中正负方向的误差将会互相抵消。 对于一个较大的误差值,平方会加大对它的惩罚力度。
所以MSE会对一些问题很有用。
但是呢,同R^2,它对异常值也是很敏感的! 比如出现特殊的outliers,那么MSE会表小,但是整体的正确率会很高的情况。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
clf = KNeighborsClassifier(n_neighbors=K)
#训练
clf.fit(X_train, y_train) # 这里我们不再转为数字,默认已经数字化
# 预测
predictions = clf.predict(X_test)
# r2_score
r2 = r2_score(y_test, predictions)
# MAE
mae = mean_absolute_error(y_test, predictions)
# MSE
mse = mean_squared_error(y_test, predictions)
1.5 特征缩放 StandardScaler
对于几个特征而言,我们不知道哪个特征会对预测结果的影响更大,但是不同的取值范围会对预测结果的影响更大。 这样说有些晦涩,我们举个栗子:
比如我们已知特征 【身高,性别】, 预测【体重】,其中身高是连续值,性别则为离散值。
每个实例值减去均值,除以特征标准差
- 身高可以取米,厘米,毫米不同的数值范围,很显然不同的范围对预测结果影响不同。
- 性别为离散值,如果处理为和身高同等范围的连续值呢!
from scipy.spatial.distance import euclidean
# 不同的身高范围对预测结果的影响
X_train = np.array([
[1700, 1],
[1600, 0]])
X_test = np.array([1640, 1]).reshape(1,-1)
print(euclidean(X_train [0,:], x_test)) # 8.0
print(euclidean(X_train [1,:], x_test)) # 2.236
X_train = np.array([
[1.7, 1],
[1.6, 0]])
X_test = np.array([164, 1]).reshape(1,-1)
print(euclidean(X_train [0,:], x_test)) # 160.3
print(euclidean(X_train [1,:], x_test)) # 160.40311
# 很显然,如果采用不同的取值范围影响会很大!!
StandardScaler和前面的LabelBinarizer一样,也是参数化和映射
# StandardScaler
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train_scaled = ss.fit_transform(X_train)
print(X_train)
print(X_train_scaled )
X_test_scaled = ss.fit_transform(X_test)
clf.fit(X_train_scaled , y_train)
clf.predict(X_test_scaled)
# 后面再计算f2_score/MAE/MSE的不同,不写了
1.6 提取特征
所有的方法出自feature_extraction ;
同样集成了fit_transform();
生成的都是稀疏矩阵,所以需要toarray()
1.6.1 ont-hot编码
注意没有按照顺序生成;
这种不会考虑某个类的权重,有些类权重不高,没有意义;
同时会促使模型对没有没有意义的类进行比较;
from sklearn.feature_extraction import DictVectorizer
onehot_encoder = DictVectorizer()
X = [
{'city':'a'},
{'city':'b'},
{'city':'c'}
]
print(onehot_encoder.fit_transform(X).toarray())
#Out[1]:
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]]
1.6.2 特征标准化
标准化:零平均值和单位方差;
零平均值指的变量相对于原点居中;
单位方差,所有特征的方差处于相同量级,则拥有单位方差。
如果某个特征有较大方差,那么反向传播是往梯度下降最快的方向,那么其它特征会受到影响。
除了前面的StandardScaler,scale函数也会对数据的任何轴进行标准化
每个实例值减去均值,除以特征标准差
from sklearn.preprocessing import scale
print(scale(X))
1.6.3 从文本中提取特征
两种最常用的是词袋模型和词向量
词袋模型 CountVectorizer
词袋模型类似于one-hot编码, 包含类似单词的文档经常有相似的含义。
一个文档的集合被成为了语料库。 就是所有样本集合。
具体什么是词袋模型,这里不讲解了,就是基本的词袋是set(words),就是所有的单词不重样。
CountVectorizer转换器可以将一个字符串或者文件中生成词包表示。 默认情况下,它会将文档中的字符转换为小写并对文档进行词汇切分。
词汇切分就是分词。 并且提取长度大于等于两个字符的字符序列进行统计。
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'aa bb cc dd ee ff',
'22 33 44 55 66'
] # 语料库只要是可以迭代的就行,每个元素是一个实例; 或者是Dataframe格式
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(corpus).todense())
print(vectorizer.vocabulary_) # 展示词表和词的数量
# Out[2]
[
[1 1 ...]
[........]
]
{'aa': 1, 'bb': 1, ......}
计算文档距离之欧几里得距离| L 2 L^2 L2范数
两个向量的欧几里得距离等于两个向量差值的欧几里得范数,又叫做
L
2
L^2
L2范数;
一个向量的欧几里得距离等于这个向量的量级; (每个向量元素平方后开根号)
# 接上个代码
from sklearn.metrics.pairwise import euclidean_distances
X = vectorizer.fit_transform(corpus).todense()
ed = euclidean_distances(X[0], x[1])
但是数据量大了之后会导致稀疏向量; 被称为维度诅咒;既占用内存,又有很多无意义的表示。
我们可以通过Scipy表示稀疏向量,同时可以通过降低维度来拟合数据。
停用词过滤
词干提取和词形还原
上面两个在CountVectorizer只存在stop_words=‘English’
而且没有词干提取和词形还原
tf-idf
词包创建特征向量,这些特征向量不会编码语法、单词顺序或者词频。
一个单词在文档中出现的频率可以表明该文档与单词的相关程度。
和某个单词只出现一次的长文档相比,同样的单词出现很多次的文档可能讨论的是完全不同的主题。
import numpy as np
corpus = ['aa bb cc aa bb dd ee ff gg hh']
vectorizer = CountVectorizer()
frequencies = np.array(vectorizer.fit_transform(corpus).todence())[0]
print(frequencies) # 单词频度
print(vectorizer.vocabulary_) # 每个单词 + 其频度
在特征向量中对单词项的真实频度进行编码可以对文档的意义提供额外的信息,单前提需要所有文档有相似的长度。 许多单词也许在两个文档中出现的频数相同,但是一个文档长度比另一个文档大数倍,两个文档仍然有很大差别。
TfdfTransformer类可以通过将单词频数向量矩阵转换为一个标准化单词频数权重矩阵来缓和这个问题。
TfdfTransformer类对真实频数做光滑化处理,并对其运用
L
2
L^2
L2范数。
t
f
(
t
,
d
)
=
f
(
t
,
d
)
∣
∣
x
∣
∣
tf(t,d)=\frac{f(t,d)}{||x||}
tf(t,d)=∣∣x∣∣f(t,d)
分子表示单词在文档中出现的频数,分母是单词频数向量的
L
2
L^2
L2范数。
t
f
(
t
,
d
)
=
1
+
l
o
g
f
(
t
,
d
)
tf(t,d)=1+logf(t,d)
tf(t,d)=1+logf(t,d)
也可以计算单词频数的对数,通过sublinear_tf = True来设置。
但是即使一个单词在一篇文档中疯狂出现,但是上面的没有考虑该单词在其它文档中的作用,也就是逆文档频率(IDF)
IDF可衡量一个单词在语料库中是不是稀疏;
i
d
f
(
t
,
D
)
=
l
o
g
N
1
+
∣
d
∈
D
:
t
∈
d
∣
idf(t,D)=log\frac{N}{1+|d\in{D}:t\in{d}|}
idf(t,D)=log1+∣d∈D:t∈d∣N
分子是文档总数,分母是包含该单词的文档总数。
因此tf-idf是其单词频数和逆单词文档指数的乘积。
当user_idf = True时,TfdfTransformer返回tf-idf权重。
由于CountVectorizer 和 TfdfTransformer需要一起使用,所以sklearn封装了两者为TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'aa bb cc dd ee ff',
'22 33 44 55 66'
]
vectorizer = TfidfVectorizer() # stop_words='english'
print(vectorizer.fit_transform(corpus).todense())
空间有效特征向量化与哈希技巧
前面都有一个字典来映射,然而创建该字典两次遍历语料库,第一次用于创造字典,第二次用于为文档创建特征向量; 其次,字典必须放到内存中。
我们通过对标记使用哈希函数决定其在特征向量中的索引来避免创建字典,这叫做哈希技巧
from sklearn.feature_extraction.text import HashingVectorizer
corpus = [
'aa bb cc dd ee ff',
'22 33 44 55 66'
]
vectorizer = HashingVectorizer(n_features=6)
print(vectorizer.transform(corpus).todense())
n_features是可选的,默认为
2
10
2^{10}
210, 我们现在选择为6,因为语料库不大!
哈希冲突会使得一些索引为负数! 创建的过程就是数据结构中的创建!
词向量
import gensim
model = gensim.models.KeyVectors.load_word2vec_format('./xxxx')
embedding = model.word_vec('cat')
print(model.similarity('cat', 'dog'))
1.7 从线性回归到逻辑回归
泛线性模型:简单线性回归,多元线性回归和多项式线性回归。
它比普通线性回归需要更少的假设!
逻辑回归不同于其它回归,是分类任务。
1.7.1 逻辑回归进行二元分类
普通的线性回归假设变量符合正态分布。 正态分布就是高斯分布,是描述任何一个观测值对应一个位于两个实数之间值的概率的函数。 正态分布数据是对称的。 其均值、中位数和众数都相等。 比如身高就是正态分布;
但是抛硬币中响应变量就不符合正态分布; 而是符合伯努利分布,其描述了一个只能取概率为P的正向情况或者概率为1-P的负向情况的随机变量的概率分布。
如果一个**响应变量(预测值)**代表一个概率,它只能限制再【0,1】之间。
线性回归假设要给特征值的同等变化将造成响应变量上的同等变化,然而如果响应变量是一个概率,则该假设不成立。
泛化的线性模型通过使用一个连接函数将特征的线性组合和响应变量相关联来去除假设。
我们可以使用一个不同的连接函数来连接特征的线性组合和一个非正态分布响应变量。
逻辑回归中,响应变量描述了结果是正向情况的概率。 如果是响应变量等于或者超出了一个阈值,则为正,相反为负。
该连接函数为逻辑函数。
F ( t ) = 1 1 + e − t F(t) = \frac{1}{1+e^{-t}} F(t)=1+e−t1
t是解释变量(特征)的线性组合;
效用函数是逻辑函数的逆:
g
(
x
)
=
l
n
F
(
x
)
1
−
F
(
x
)
=
β
0
+
β
∗
x
g(x)=ln\frac{F(x)}{1-F(x)}=\beta_0 + \beta*x
g(x)=ln1−F(x)F(x)=β0+β∗x
而且F(t)的导数可求的,所以它可以反向求导
1.7.2 垃圾邮件过滤
就是利用tf-idf然后使用逻辑回归,不想写了
1.7.3 二分类性能指标
不能使用线性回归的性能指标。
准确率、精准率、召回率、F1值以及ROC、AUC得分;
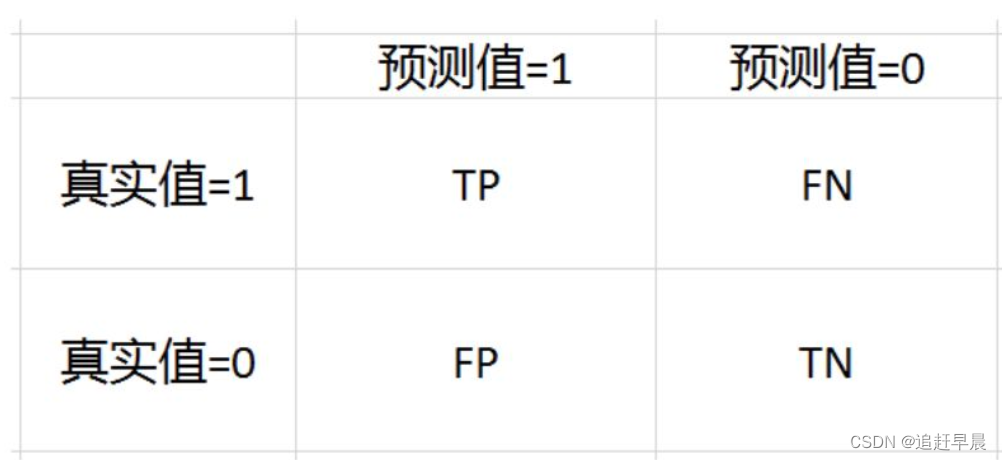
都是基于真假阳性阴性来的。
准确率衡量了分类器的整体正确性,但是不能区分假阳性错误和假阴性错误。 (都是竖着看的,预测为阳性的真正有多少是阳性的; 预测为负的真正有多少是负的)
而且样本比例不均衡,准确率也不行;
比如信用卡公司更愿意冒险验证交易是否合法,也就是关注假阴性。
受试者操作特征(ROC)起源于外国对飞行员的测试,ROC曲线表明了分类器对所有阈值的性能。
ROC曲线描绘了分类器召回率(recall)和假阳性率的关系。
假阳性率 = 假阳性数量除以所有阴性数量的值
F
=
F
P
T
N
+
F
P
F=\frac{FP}{TN+FP}
F=TN+FPFP
TN: true negative;
FP: False positive
AUC 则是ROC曲线下面的面积。 高于实曲线则高于随机猜测的分类器
- 混淆矩阵
# X_train_raw, X_test_raw, y_train, y_test
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.fit_transform(X_test_raw)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test_raw)
# 混淆矩阵
cofusion_matrix = confusion_matrix(y_test, y_pred)
print(cofusion_matrix)
plt.matshow(cofusion_matrix)
plt.title('Confusion matrix')
plt.colorbar()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
# 准确率
scores = cross_val_score(classifier, X_train, y_train, cv=5)
print('Accuracies: %s' % scores)
print('Mean Accuracy: %s'np.mean(scores))
# 精准率、召回率和F1分数
precisions = cross_val_score(classifier, X_train, y_train, cv=5, scoring='Precision')
print('Mean precision: %s'np.mean(precisions))
recalls = cross_val_score((classifier, X_train, y_train, cv=5, scoring='recall')
print('Mean Recall: %s'np.mean(recalls))
r1s = cross_val_score((classifier, X_train, y_train, cv=5, scoring='f1')
print('Mean f1: %s'np.mean(r1s ))
# ROC AUC
predictions = classifier.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test, predicitons[:,1])
roc_auc = auc(false_positive_rate, recall)
plt.title('Receiver Operating Characteristic')
plt.plot(false_positive_rate, recall, 'b', label='AUC = %0.2f' %roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1], [0,1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
1.7.4 使用网格搜索微调模型
模型的超参数市学习算法无法估计的参数,比如逻辑回归短信分类器超参数有移除频率过高或者过低的单词临界值。
在sklearn中超参数通过估计器和转换器的构造函数设置。 如果我们不设置超参数,那么就会使用默认值,当然这只是一个好的开端,不能得到最优的模型。
网格搜索接受一个包含所有应该被微调的超参数的可能取值集合,并评估在该集合中的笛卡尔乘积的每一个元素上训练的模型的性能。 这会耗费大量的算力,但是还好这是个并行的,进程之间不会同步阻塞。
GridSearchCV类接受一个估计器、参数空间和一个性能衡量指标。 njobs表明并发工作的最大数量,默认为-1,表示调用所有的CPU资源。 为了生成额外的进行,fit必须在python的主模块运行。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model._logistic import LogisticRegression
from sklearn.model_selection import KFold, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score,recall_score,accuracy_score
pipeline = Pipeline([
('vect', TfidfVectorizer(stop_words='english')),
('clf', LogisticRegression)
])
parameters = {
'vect__max_df':(0.25, 0.5, 0.75),
'vect__stop_words':('english', None),
'vect__max_features':(2500, 5000, 10000, None),
'vect__ngram_range':((1, 1), (1, 2)),
'vect__use_idf':(True, False),
'vect__norm':('l1', 'l2'),
'clf__penalty':('l1', 'l2'),
'clf__c': (0.01, 0.1, 1. 10)
}
df = pd.read_csv('XXXX', header=None, sep='\t') #数据集就用自己的吧,满足特征列(可以多列)和标签列就行
X = df[1].values
y = df[0].values
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
x_train, X_test, y_train, y_test = train_test_split(X, y)
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1, verbose=1, scoring='accuracy', cv=3)
grid_search.fit(X_train, y_train)
print('Best score: %0.3f' % grid_search.best_score_)
print('Best parameters set:)
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('t%s: %r' % (param_name , best_parameters[param_name ] ))
predictions = grid_search.predict(X_test)
print('Accuracy:', accuracy_score(y_test, predictions))
print('Precision:', precision_score(y_test, predictions))
print('Recall:', recall_score(y_test, predictions))
1.7.5 多类别分类
sklearn中提供了一对全和一对剩余两种分类策略!
一对全:对每一个可能的类使用一个二元分类器。
假如你想观看一部电影,但是你对烂片有一种强烈的厌恶感,你可以阅读评论来找出评论更好的。
每一个短语被分为:负向,略负向,中立,略正向,正向。
可以从kaggle中下载sentiment-analysis-on-movie-reviews数据集;
通过类别分析,我们可以看出,中立的有超过50%的实例,一个很差的分类器将所有实例都预测为中立,那么准确率也有50%,所以只用准确率肯定不行。
import pandas as pd
# 数据类别分析
df = pd.read_csv('./train.tsv', header=0, sep='\t')
print(df.count()) # 查看所有列的个数
print(df.head()) # 查看数据类型
print(df['Phrase'].head(10)) # 我们不需要PharaseId和SenrenceId列
print(df['Sentiment'].describe()) # 查看类别列的平均值等
print(df['Sentiment'].value_counts()) # 查看类别列各种类别的数量
print(df['Sentiment'].value_counts()/df['Sentiment'].count())
# 模型预测
X, y = df['Phrase'], df['Sentiment'].as_matrix()
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5)
grid_search = main(X_train, y_train)
pipeline = Pipeline([
('vect', TfidfVectorizer(stop_words='english')),
('clf', LogisticRegression)
])
parameters = {
'vect__max_df':(0.25, 0.5),
'vect__ngram_range':((1, 1), (1, 2)),
'vect__use_idf':(True, False),
'vect__norm':('l1', 'l2'),
'clf__c': ( 0.1, 1. 10)
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1, verbose=1, scoring='accuracy', cv=3)
grid_search.fit(X_train, y_train)
print('Best score: %0.3f' % grid_search.best_score_)
print('Best parameters set:)
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('t%s: %r' % (param_name , best_parameters[param_name ] ))
## 混淆矩阵
predictions = grid_search.predict(X_test)
Accuracy
cofusion_matrix
Classification Report
cofusion_matrix = confusion_matrix(y_test, y_pred)
1.8 朴素贝叶斯
KNN和逻辑回归可以做分类,朴素贝叶斯也是可以的!
其名字来源于一个朴素的假设,所有的特征都相互独立于其他给定的响应变量。
朴素贝叶斯就是我们要讨论的第一个生成模型。
1.8.1 朴素贝叶斯定理
P
(
A
∣
B
)
=
P
(
B
∣
A
)
A
P
(
B
)
P(A|B)=\frac{P(B|A){A}}{P(B)}
P(A∣B)=P(B)P(B∣A)A
在分类任务中,我们的目标就是基于B特征,预测A类别!
这是基于先验知识的!
1.8.2 生成模型和判别模型
判别模型: 学习一个决策边界对类进行判别。 概率判别模型: 它能学习区估计条件概率,会根据给定的输入值去估计最有可能的类。 如逻辑回归; 非概率判别模型,会直接把特征映射到类,如KNN。
生成模型:不会直接学习一个决策边界。 相反,生成模型对特征和类的联合概率分布P(x,y)进行建模。 这等价于对类的概率和给定类的情况下特征的概率进行建模。 也就是说生成模型对类如何生成特征进行建模。 贝叶斯定理就可以运用于生成模型来估计给定特征情况下一个类的条件概率。
分类任务就是将特征映射到类,需要一个中间的步骤。 生成模型可以生成数据,所以在数据缺乏时候,生成数据比较有效,以为它对类如何生成数据进行建模, 生成模型相比于判别模型有更大的偏差。 但是这个中间步骤引入了更多的假设,这些假设前提下,生成模型可以更稳健地扰乱训练数据,并在训练数据很缺乏时比判别模型更佳。
生成模型地缺点是这些假设可能会阻止生成模型进行学习,随着训练实例数量地增加,判别模型性能优于生成模型。
1.8.3 朴素贝叶斯
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A|B)=\frac{P(B|A)P(A)}{P(B)}
P(A∣B)=P(B)P(B∣A)P(A)
P
(
y
∣
x
1
,
.
.
.
.
.
,
x
n
)
=
P
(
x
1
,
.
.
.
,
x
n
∣
y
)
P
(
y
)
P
(
x
1
,
.
.
.
,
x
n
)
P(y|x_1,.....,x_n)=\frac{P(x_1, ..., x_n|y)P(y)}{P(x_1, ..., x_n)}
P(y∣x1,.....,xn)=P(x1,...,xn)P(x1,...,xn∣y)P(y)
这里的B我们转为各种特征,
x
1
{x_1}
x1表示的是实例的第一个特征,以此类推。
P(B)表示的是类别。 是一个常量。 可以忽略。
先验概率
P
(
y
)
P(y)
P(y)以及条件概率
P
(
x
1
,
.
.
.
,
x
n
∣
y
)
{P(x_1, ..., x_n|y)}
P(x1,...,xn∣y)。 朴素贝叶斯通过极大化一个后验估计来估计这两个。 前者表示的是训练集中每个类出现的概率,后者属于该类训练实例的特征的频率。 它通过
P
^
(
x
i
∣
y
)
=
N
x
i
,
y
j
N
y
j
\widehat{P}(x_i|y) = \frac{N_{x_i, y_j}}{N_{y_j}}
P
(xi∣y)=NyjNxi,yj
所以朴素贝叶斯就是最大化
y
^
=
a
r
g
m
a
x
y
P
(
y
)
∏
i
=
1
n
P
(
x
i
∣
y
)
\widehat{y}=argmax_yP(y)\prod_{i=1}^nP(x_i|y)
y
=argmaxyP(y)i=1∏nP(xi∣y)
需要注意的是,即使一个朴素贝叶斯分类好像表现的很好,估计的类概率的准确率也会很低。
朴素贝叶斯的变体最可能在于对于P(x_i|y)的假设上不同,也就是特征的分布不同,因此他们能够学习的特征类型不同。
多项式朴素贝叶斯适合类别特征; 词频被认为是一个变量;
高斯朴素贝叶斯适合连续特征; 它假设每个特征对每个类都符合正态分布;
伯努利朴素贝叶斯适合于所有特征为二元值的情形。
分别对应着GaussianNB BernoulliNB和MultinormialNB
朴素来源就是各个特征相互独立,但是这个条件很难满足,即使不满足也没关系,同样在数据缺乏时优于判别模型。 也就是下面几个式子都满足。
P
(
x
i
∣
y
)
=
P
(
x
i
∣
y
,
x
j
)
P(x_i|y)= P(x_i|y,x_j)
P(xi∣y)=P(xi∣y,xj)
P
(
x
i
)
=
P
(
x
i
∣
x
j
)
P(x_i)=P(x_i|x_j)
P(xi)=P(xi∣xj)
P
(
x
i
,
x
j
)
=
P
(
x
i
)
∗
P
(
x
j
)
P(x_i, x_j)=P(x_i) * P(x_j)
P(xi,xj)=P(xi)∗P(xj)
比如新闻分类中,一篇关于体育板块的,我们假设的是出现“篮球”并不会影响“库里”的出现,同时不会影响到“NBA”单词的出现,然鹅这是不可能的,这三个是会有几率影响的,也就是说不完全是独立的。 以为它肯定不会出现“三明治”。
同时朴素贝叶斯也会假设特征都是满足独立同分布的。。 满足同一个分布!
1.8.4 代码
两个数据集:威斯康星乳癌数据集和皮马印第安人糖尿病数据集
威斯康星乳癌数据集: 特征:乳房肿块的细针吸入图片中提取到的细胞核的实值特征; 分类:肿块恶性或者是良性; 212个恶性实例和357个良性实例
皮马印第安人糖尿病数据集: 特征:8个特征表示; 分类:该人是不是糖尿病; 268个糖尿病实例和500个非糖尿病实例。
实验设置: 在两个样本数逐渐增大的数据集上比较朴素贝叶斯和逻辑回归分类器的性能。
%matplotlib inline #指的是在jupyter内部显示图片
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussiaNB
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
stratify=y,
test_size=0.2,
random_state=31
) # stratify = y 使得训练集和测试集应该有相同的比例的正向实例和负向实例。 这在类别不平衡上很有用
lr = LogisticRegression()
nb = GaussiaNB()
lr_scores = []
nb_scores = []
train_sizes = range(10, len(X_train), 25)
for train_size in train_sizes:
X_slice, _, y_slice, _ = train_test_split(X_train,
y_train,
stratify=y_train,
train_size=train_size,
random_state=31
)
nb.fit(X_slice, y_slice)
nb.scores.append(nb.score(X_test, y_test))
lr.fit(X_slice, y_slice)
lr.scores.append(lr.score(X_test, y_test))
plt.plot(train_sizes, nb_scores, label='Naive Bayes')
plt.plot(train_sizes, lr_scores, linestyle='--', label='Logistic Regression')
plt.title("Naive Bayes and Logistic Regression Accuracies")
plt.xlabel("Number of training instances")
plt.ylabel("Test set accuracy")
plt.legend()
1.8.5 sklearn参数调节
GridSearchCV
这是将网格搜索和交叉验证放到一块了! CV: cross_Validation
因为都是笛卡尔积! 【参数的个数 * CV】
parameters = {
}
grid_search = GridSearchCV(pipeline, parameters, n_jobs=-1, verbose=1, scoring='accuracy', cv=3)
-
参数:
estimator : 这个表示分类器的! 也可以是Pipeline!
param_grid: 这个是参数字典! 参数名字为keys, 参数的列表作为值!
, : 其他参数! 可以扩展
scoring=None: 可以一个评判标准,str,可以是准确率啊,recall啊; 也可以是多个评判标准,一个列表; 如果是前者则返回一个值,如果后者那么就是返回一个字典,每个字典的key就是评判标准。
n_jobs=Non: -1表示有空闲CPU就会被用
refit=True,
cv=None,
verbose=0,
pre_dispatch="2n_jobs",
error_score=np.nan,
return_train_score=False: 这个设置为True,就会返回参数怎么影响的得分! -
属性
cv_results_ : 返回的是字典或者是ndarray,当然自己可以转为dataframe; 返回的是笛卡尔积的结果 -
方法
自定义参数 + cross_val_score
import numpy as np
#导入交叉验证工具
from sklearn.model_selection import cross_val_score
#设置alpha参数遍历0.01、0.1、1和10
for alpha in [0.01, 0.1, 1, 10.0]:
#最大迭代数遍历100、1000、5000和10000
for max_iter in [100, 1000, 5000, 10000]:
lasso = Lasso(alpha=alpha, max_iter = max_iter)
scores = cross_val_score(lasso, X_train, y_train, cv=6) # 6个交叉验证的得分!
score = np.mean(scores)
# 另最佳分数为所有分数中的最高值
if score > best_score:
best_score = score
# 定义字典,返回最佳参数和最佳最大迭代次数
best_parameters = {'alpha': alpha, '最大迭代数': max_iter}
# 打印结果
print('模型最高分为:{:.3f}'.format(best_score))
print('最佳参数设置:{}'.format(best_parameters))
# n个参数设置,那么就是笛卡尔积,多个for循环
# 需要记录每个fold的得分
# 记录最佳分数和最佳参数
StratifiedKFold():k折数据按照百分比划分数据集
这里需要自己来定义
from sklearn.model_selection import StratifiedKFold
import numpy as np
# 这里直接切分了2折! 然后每次返回一个训练和测试的索引!
# 然后根据索引来获得训练和测试训练集!
skf = StratifiedKFold(n_splits=2)
for train_index, test_index in skf.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
1.9 F1的micro 和 macro和weighted
链接
首先F1是Recall和Precision的加权平均!!! 区别就在于Recall和Precision的利用!前者是所有类的平均,后者是直接计算每个类的F1,再平均
两者的区别就是:
micro: 先计算每个类的Recall和Precision,然后求所有类的Recall和Precision的平均,再计算F1;
macro: 先计算每个类的Recall和Precision, 先计算每个类的F1的区别!然后求F1的平均
其中micro是先计算Recall
它的最大值是1,最小值是0;
多分类问题中,F1则又分为了micro-F1和macro-F1, 这两种在二分类上是一样的。
-
二分类
F 1 = 2 1 R e c a l l + 1 P r e c i s i o n = 2 R e c a l l ∗ P r e c i s o n R e c a l l + P r e c i s i o n F_1 = \frac{2}{\frac{1}{Recall} + \frac{1}{Precision}} = 2\frac{Recall * Precison}{Recall + Precision} F1=Recall1+Precision12=2Recall+PrecisionRecall∗Precison
因为二分类中,只有一个类的recall和precision,另一个类都是一样的 -
多分类
类别1: Recall1 Pre1 F1-score1
类别2: Recall2 Pre2 F1-score2
类别3: Recall3 Pre3 F1-score3
❤️ micro-F1:
适用环境: 多分类不平衡,若极度不平衡则影响结果
计算方式:
R
e
c
a
l
l
m
i
=
T
P
1
+
T
P
2
+
T
P
3
T
P
1
+
T
P
2
+
T
P
3
+
F
N
1
+
F
N
2
+
F
N
3
Recall_{mi}=\frac{TP_1 + TP_2 + TP_3}{TP_1 + TP_2 + TP_3+FN_1 + FN_2 + FN_3}
Recallmi=TP1+TP2+TP3+FN1+FN2+FN3TP1+TP2+TP3
同理
P
r
e
c
i
s
i
o
n
m
i
Precision_{mi}
Precisionmi也是这么计算的! 只不过分母变成了混淆矩阵中的竖着计算!
所以
m
i
c
r
o
F
1
s
c
o
r
e
=
2
∗
R
e
c
a
l
l
m
i
∗
P
r
e
c
i
s
i
o
n
m
i
R
e
c
a
l
l
m
i
+
P
r
e
c
i
s
i
o
n
m
i
micro F1_{score} =2*\frac{Recall_{mi}*Precision_{mi}}{Recall_{mi} + Precision_{mi}}
microF1score=2∗Recallmi+PrecisionmiRecallmi∗Precisionmi
❤️ macro-F1:
适用环境:多分类问题,不受数据不平衡影响,容易受到识别性高(高recall、高precision)的类别影响;
我们先计算每个类别的
F
1
−
s
c
o
r
e
i
=
2
R
e
c
a
l
l
∗
P
r
e
c
i
s
o
n
R
e
c
a
l
l
+
P
r
e
c
i
s
i
o
n
F_1 - score_i= 2\frac{Recall * Precison}{Recall + Precision}
F1−scorei=2Recall+PrecisionRecall∗Precison
计算:
m
a
c
r
o
F
1
s
c
o
r
e
=
F
1
−
s
c
o
r
e
1
+
F
1
−
s
c
o
r
e
2
+
F
1
−
s
c
o
r
e
3
3
macro F1_{score} = \frac{F1-score_1 + F1-score_2 + F1-score_3}{3}
macroF1score=3F1−score1+F1−score2+F1−score3
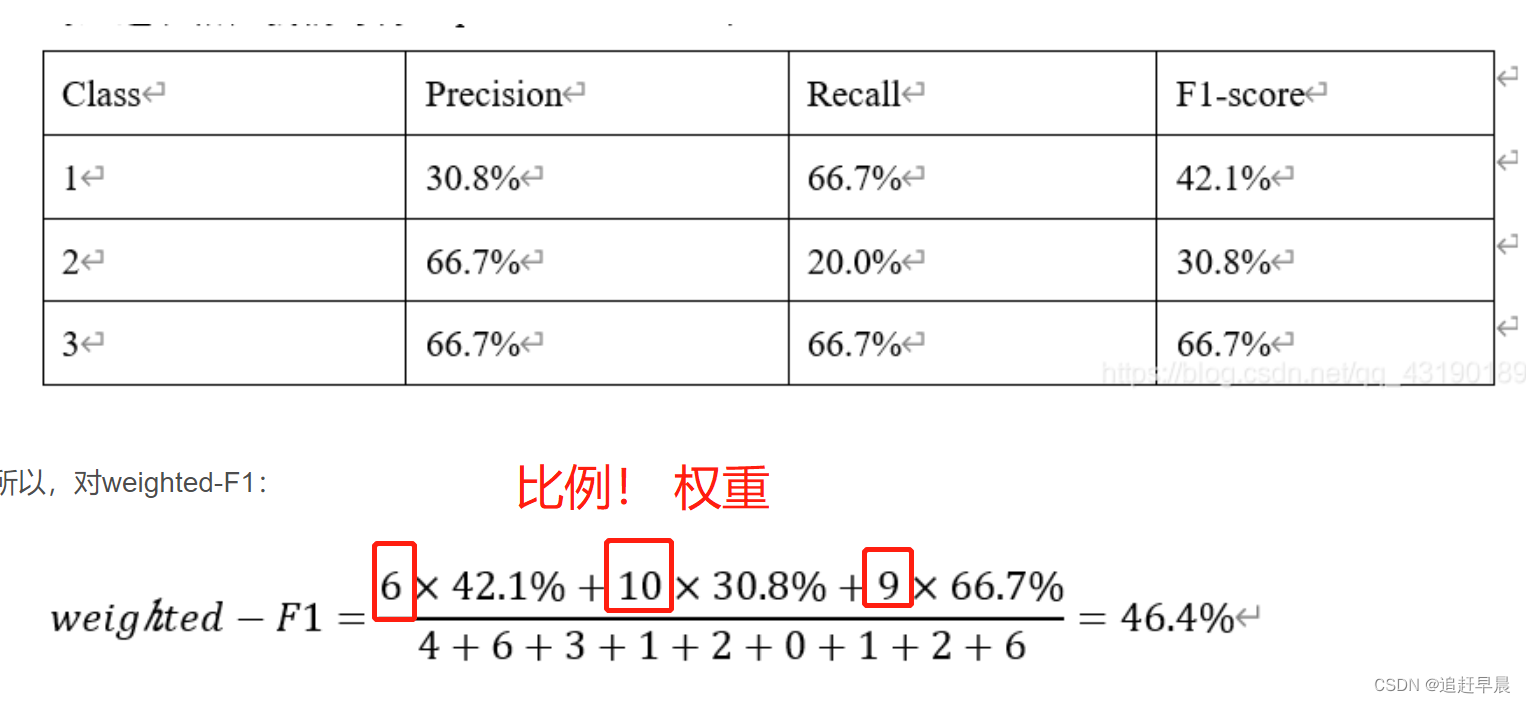
❤️ weighted-F1:
除了micro-F1和macro-F1,还有weighted-F1,是一个将F1-score乘以该类的比例之后相加的结果,也可以看做是macro-F1的变体吧
在调参中,我们要选择"f1_weighted"
grid_search = GridSearchCV(lg, n_jobs=-1, scoring='f1_weighted', param_grid=param_dist, cv=10, verbose=5)
# 还有更多的评分方式可以运行这两行代码获得:
import sklearn.metrics as sm
print(sorted(sm.SCORERS.keys()))
❤️ 总结:
记住! F1分数是recall和precision的融合!由两者得来的!
👎micro 先计算真阳性,假阳性等,再次统计调用F1计算公式! 2 * 。。。。
👍macro,先计算每个分类的F1分数(利用该类的recall和precision),然后再除以分类个数!
👍weighted 在计算时添加了样本比例!!
1.10 绘制多分类的ROC曲线
from sklearn.metrics import precision_recall_curve详解:
意义: 设定一系列的阈值,计算每个阈值下对应的recall和precision。
比如四分类中,其标签被二进制化了,标签为
第一类:【0,0,0,1】
第二类:【0,0,1,0】
第三类:【0,1,0,0】
第四类:【1,0,0,0】
我们将样本放入到模型中,输出预测概率为
【【0.1, 0.2, 0.3, 0.8】,
【0.8, 0.1, 0.2, 0.3 】。。。】(很明显是第四类);
在计算精准率和召回率的时候,我们只会单独考虑某一列!(1 vs rest! 也就是把问题定义为二分类任务)
那么现在我们就获得了所有样本该类的预测率,这个时候就变成二分类问题了
【0.8,
0.3,
0.2,
0.4,
。。。。。】
这个时候我们再多次设置阈值为【0.2,0.5,0.75,1】那么就是大于该阈值的都被认为是该类;
这个时候每个阈值下的预测标签也就都有了,那么不同的阈值下,精准率和准确率也就都可以计算了!!
1.11 多分类的准确率/召回率/精准率关系
经过折腾,我明白了三者关系
在二分类中,
准确率指的是(TP + TN)/所有样本
召回率,特指正样本的 TP / (TP + FP),分母是所有的正样本的数量,其实也可以理解为该样本的自己的全局准确率!
精准率,特指正样本的TP/(TP + FN), 分母是所有预测为正样本的数量;
多分类中,
准确率: 我原来想求每个样本的准确率,但是后面一想,准确率指的是全局的准确率,每个样本的准确率根据定义应该属于召回率! 所以这里的准确率就是指的是全部样本的正确和错误的数量与总体样本的比例
召回率:召回率也是每个样本的准确率
精准率: 每个样本的精准率
1.12 ROC与PR曲线
注意:
ROC曲线横坐标是FPR,纵坐标TPR;
PR曲线则是横坐标召回率,纵坐标精准率;
F
P
R
=
F
P
F
P
+
T
N
FPR = \frac{FP}{FP + TN}
FPR=FP+TNFP
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP}{TP + FN}
TPR=TP+FNTP
说白了就是横向的,查看正样本的正样本的准确率和预测错误的正样本占错误样本的比率!
3. scipy
3. 1 稀疏矩阵
链接
稀疏矩阵的形式
# 只会保存(col, row), value 格式!!
(0, 1) 0.46979138557992045
(0, 2) 0.5802858236844359
(0, 6) 0.38408524091481483
(0, 3) 0.38408524091481483
(0, 8) 0.38408524091481483
(1, 5) 0.5386476208856763
(1, 1) 0.6876235979836938
(1, 6) 0.281088674033753
(1, 3) 0.281088674033753
(1, 8) 0.281088674033753
(2, 4) 0.511848512707169
(2, 7) 0.511848512707169
(2, 0) 0.511848512707169
(2, 6) 0.267103787642168
(2, 3) 0.267103787642168
(2, 8) 0.267103787642168
(3, 1) 0.46979138557992045
(3, 2) 0.5802858236844359
(3, 6) 0.38408524091481483
(3, 3) 0.38408524091481483
(3, 8) 0.38408524091481483
导入 scipy.sparse.csr_matrix
- 实例化方法:
可以2-ndarray!
csr_matrix((data, (row_ind, col_ind)), [shape=(M, N)])
csr_matrix.toarray()
csr_matrix((data, (row, col)), shape=(3, 3)).toarray()
csr_matrix.todense()
转换为稠密矩阵
return numpy.matrix, 2-D
csr_matrix.tocsr(copy=False)
Convert this matrix to Compressed Sparse Row/column format.
csr_matrix.transpose()
变换维度
4. cv2
4.1 NoneType
cv2中就是路径问题:1. 绝对路径 2. 不能有中文
4.2 ocr识别字体实战
注意是按照一个又一个字来的!















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









