






Re-Identification with Consistent Attentive Siamese Networks
Meng Zheng, Srikrishna Karanam, Ziyan Wu, and Richard J. Radke 2019 CVPR
1. Motivation
空间定位和视点不变性表示学习对于鲁棒的交叉视点匹配仍然是一个关键的、尚未解决的问题。本文提出一个 attention驱动的Consistent Attentive Siamese Network(CASN)解决这一问题,特点:仅有ID监督的灵活网络;显示机制强制相同ID图像之间的attention一致性学习;新的Siamese网络以集成attention和attention一致性
2.介绍

CASN网络是两分支结构:训练时不需要除ID外的任何其他信息和特殊设计的结构就能产生注意力区域;显示强制同一人的这些注意力区域保持一致;将注意力和注意力的一致性作为学习过程中的一个明确而有原则的部分;学习跨视点匹配的鲁棒性表示。
贡献:
- 空间定位出感兴趣的行人部分,端到端,只需要ID监督
- 强制同一人的不同图像之间的注意力一致性
- 在一个网络中联合了注意力一致性和孪生网络
- 第一个孪生注意力一致性网络,能为ID预测提供更好的理论解释
3. CASN网络

特征提取模块可以是简单的IDE,也可以是PCB,不限制
3.1. ID模块 图2中的两个蓝色框
针对其中一个蓝色框分析,另一个同理。

预测ID的交叉熵损失为:
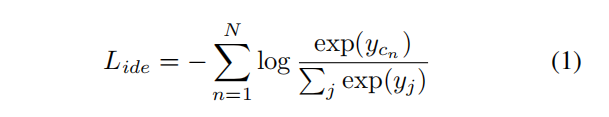
其中
y
c
n
y_{c_n}
ycn表示将输入图像
I
n
I_n
In预测为GT类别
c
n
c_n
cn的概率。
而如果能空间定位(HW维度上表示空间信息,而C表示channel信息)到重要的行人区域,那对reid提点很有帮助,且应该以端到端的方式实现。给定
I
n
I_n
In和
c
n
c_n
cn,用Grad-CAM【AANet中提到了CAM的用法】从IDE/PCB等模型分类器的预测中获取attention map,记为
M
n
M_n
Mn,但此时只关注了少数最具鉴别性的区域,如图4第二列。然后将
I
n
I_n
In中最具鉴别性的区域(
M
n
M_n
Mn中的高响应处)给mask掉,得到:
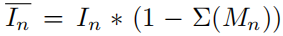
其中:

表示一种soft的mask方式。于是由于将
M
n
M_n
Mnmask out掉了,则
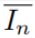
表示的其实就是那些原分类器认为“不易于分类”的那些区域,此时,我们用其来做预测,其预测正确的概率为

我们再构建损失:

最小化这个损失时也就让那些原先认为“不易于分类”的区域也慢慢变得受到关注,激活值/响应变大,变得有利于分类,如图4第四列所示。

attention越大,激活越强,越易于分类。
这就是本文的attention部分,但存在几个问题:
- 如果只有以上部分,就没有机制保证对同一人的不同图像获得一致的attention。
- 以上部分没有机制来学习不同摄像机视图的不变性表示。
- 由于测试图像的ID未知,无法计算其注意力图 M n M_n Mn,所以在推理时也就不能通过attention mask操作来获取训练时那些扩大的attention。
于是下面就是本文提到的attention还要一致的Siamese模块用于解决上述问题。
3.2. Siamese模块 图2中的红色框

首先是对学到的两张图像对应的特征进行减操作,即:
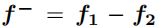
首先计算BCE损失(same/diff person?),损失为:
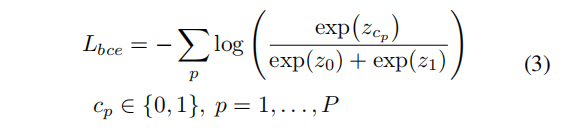
其中
z
0
z_0
z0和
z
1
z_1
z1分别表示不同人和相同人。而
z
c
p
z_{c_p}
zcp则是预测结果表示相同(
c
p
=
1
c_p=1
cp=1)或不同人(
c
p
=
0
c_p=0
cp=0)的概率。
然后就是利用结果实现注意力一致的Siamese Attention机制:
假设BCE分类器预测输入的两张图像为相同人,即以
z
c
p
=
z
1
z_{c_p}=z_1
zcp=z1为例讨论以下问题(
z
c
p
=
z
0
z_{c_p}=z_0
zcp=z0时同理),首先是计算得到:
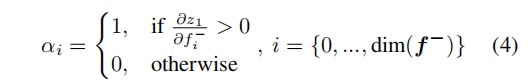
然后基于上式,得到:
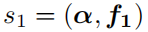
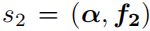
其中,括号表示做点积运算。然后,
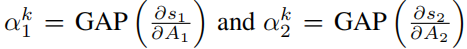
以找到channel重要性权重,其中A1和A2是输入图像
I
1
I_1
I1和
I
2
I_2
I2的最后一个卷积层对应的特征图。进一步,得到attention map为:
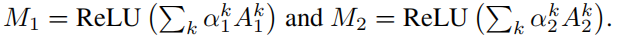
于是这一模块的损失为:
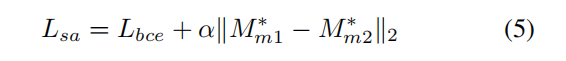
其中,
α
\alpha
α表示一个超参,设置为0.2,而不是式中的那个
α
\alpha
α。而
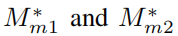
是
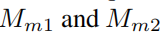
经过对齐后再resize的结果。这一模块的过程如图6所示:

整个模型的整体损失为:
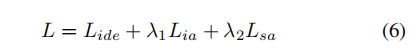
4. 实验
4.1 实验细节

4.2 和SOTA比较


很高,而MGN更高,关于MGN可参考:MGN
4.3. 消融

IA和SA各自提点都很大。
4.4. 示例


attention变广了且相同人的图像的attention还一致,性能提升很大。
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









