






Adversarial Camera Alignment Network for Unsupervised Cross-camera Person Re-identification
Lei Qi, Lei Wang, Jing Huo, Yinghuan Shi, Yang Gao 2019 CVPR?
1. Motivation
引入了“无监督跨摄像机行人ReID任务”,它只需要相机内的标签信息,而不需要相机间的标签信息,降低了标注成本(相机内标注只需要用追踪算法就能很好的标注同一人的图像了)。在这种情况下,主要的挑战来自不同姿态、遮挡、分辨率、光照条件和不同像机的噪声造成的分布差异。 针对这种情况,本文提出了一种新的Adversarial Camera Alignment Network(ACAN)。它由像机对齐任务和相机内监督学习任务组成。为了实现相机对齐,作者提出了一种多摄像机对抗性学习(MCAL)方法,将不同摄像机的图像映射到一个共享的子空间中(类似于跨域中将不同域图像编码到域不变性空间的做法)。此外还提出GRL(梯度反转层,之前就有)和“其他摄像机等概率”(OCE)策略,以进行多摄像机对抗任务。基于这个共享子空间,利用相机内标签来训练网络。
2. 介绍
本文与单纯有监督或单纯无监督的设置不同,提出了一种无监督的跨相机reid任务(可视为一种半监督ReID)。 只有相机内标签,但没有相机间标签信息。在实践中,通过使用跟踪算法和进行少量的人工标记,就可以更容易地获取这些相机内的标签信息。对于这种半监督的ReID设置,主要问题是缺乏跨摄像头的标签信息。如果仅用相机内标签数据来训练模型,就可能会导致相机视图的泛化能力较差。有一些无监督的方法就对未标记数据贴伪标签来解决这一问题,还有一些方法利用其他标记数据集(例如源域)来增强模型在未标记目标域中的泛化能力(如MAR,PAUL等跨域无监督方法)。而本文不同,我们不需要任何其他标记数据集来帮助训练模型。相反,我们专注于通过对抗的方式来探索潜在信息。
现实世界中,不同相机风格往往存在聚类现象(同一相机的图像聚在一起而不是同一人的图像聚在一起),如图1所示:

而本文引入的ACAN网络在Motivation中就介绍过了,这里不再介绍,等后面再详细讨论。
贡献:
- 无监督跨相机行人ReID任务的提出,只有相机内的行人ID信息,不同相机内各自打一套标注
- ACAN,MCAL和GRL,OCE方法
3. 方法

以上的ab都是很常规的操作,学到的c中的不同相机的特征也是常规操作,本文的操作仅仅是c中AL的做法和如何用学习到的不同相机的特征来构建一个共享的特征空间,而d就是后面的reid过程。
其中AL为:
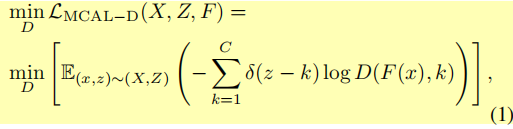
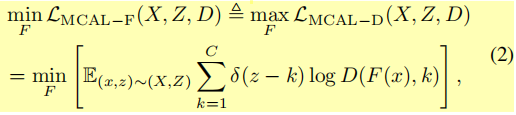
其实就是普通的对抗损失
D替换成了这里的F,是图2中的b,即特征提取器,用于提取一个特征,最小化式2表示为了鉴别器D不能将来自不同相机的图像x提的特征F(x)正确分类为k相机,这样就保证了了不同相机的图像会聚类到不同区域。其中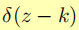
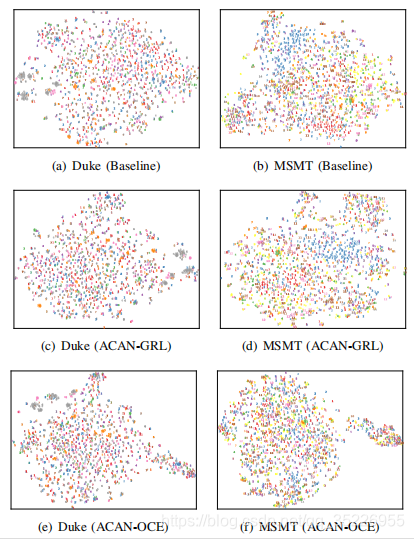
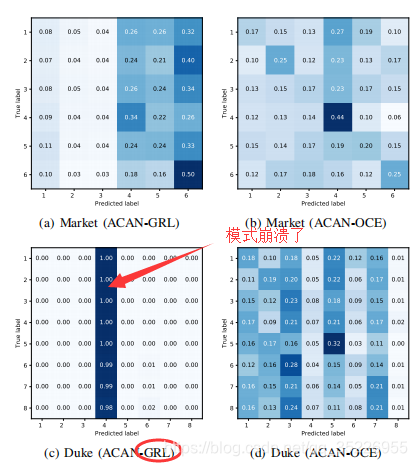
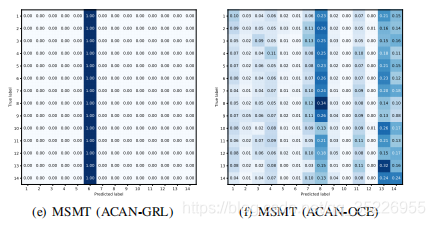
是冲击函数,在z=k时结果为1,即预测相机label等 于真实相机label时,结果为1;否则为0。而最小化式1就是最大化式2,只不过作者将普通的对抗损失拆成了两部分而已。而最小化式1也就是让鉴别器能区别来自不同相机的图像,将它们正确分类到不同相机中。如此进行D和F的博弈,会得到一个不错的共享特征空间,保证在这个空间中,不同相机的图像都混乱散布而不是聚类到不同区域。就像下图这样(下图是最终算法的结果):
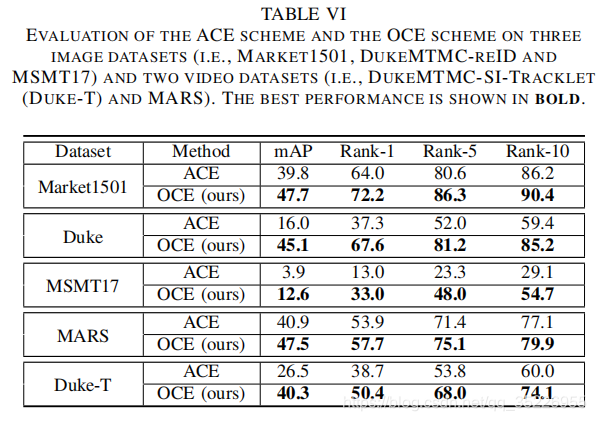
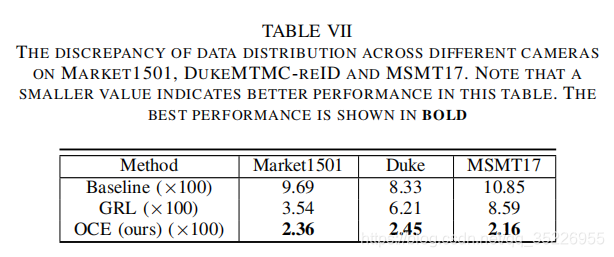
然后就是引入了GRL和OCE两种策略求解上述问题。其中GRL广泛用于减小域间分布差异,将不同相机视为不同域就可将GRL嵌入到模型中,但这一策略是通过最大化鉴别器损失来完成这一目的的(即式2),就相当于只尽量让鉴别器不能正确区分图像来自哪个相机,也就是式2对应的让F更能提取到一个好的共享空间,就是实现式2的一种手段而已,但这会导致将所有相机的图像都分类到同一类,即产生模式崩溃。于是引入了OCE策略(替换GRL而已),其基于下面这个定理:

从而有:

最终任务为:
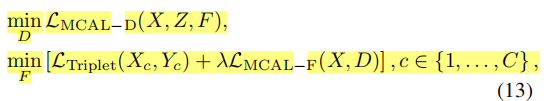
其中下式的三元组损失是图2d中的reid模型的三元组损失,而第二项来自式10,替换了式2。
然后就是反向传播了,基于GRL的为:
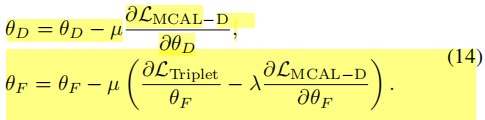
基于OCE的为:

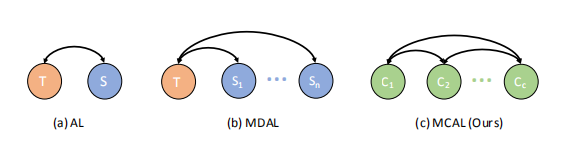
三种任务对比:
4. 实验
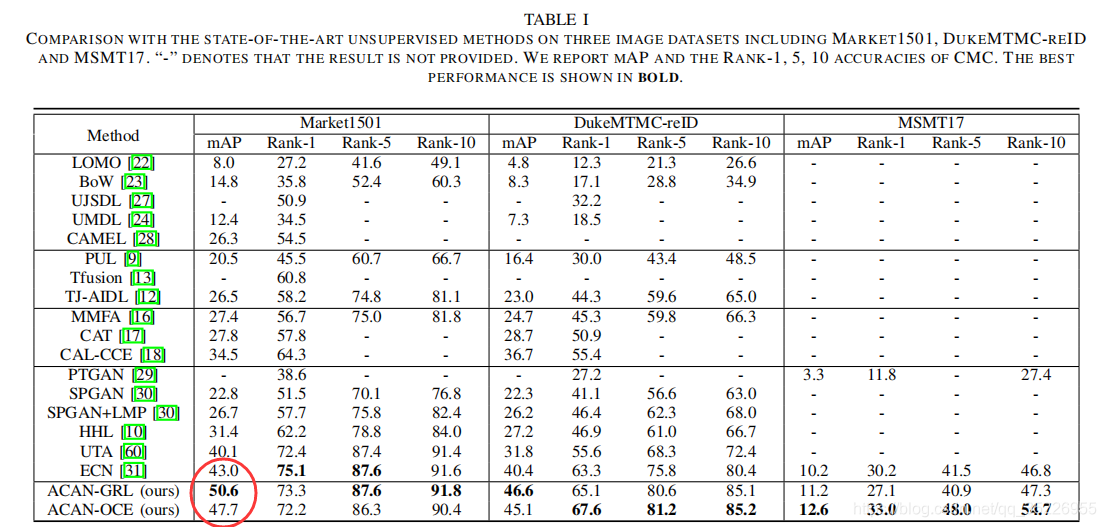
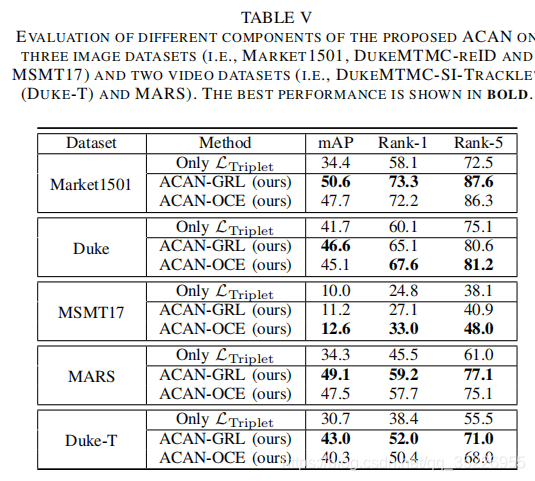
可看到比ECN还高很多。
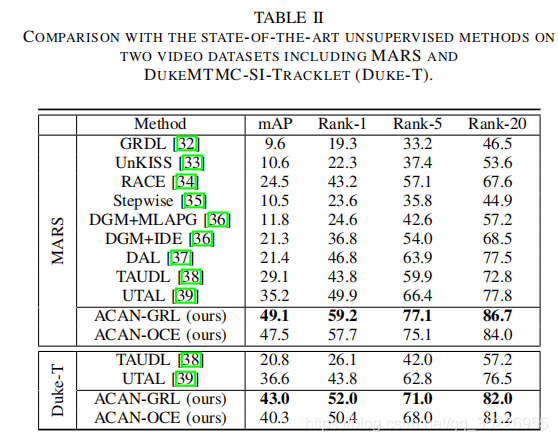
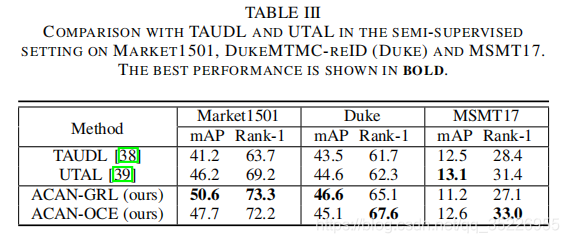
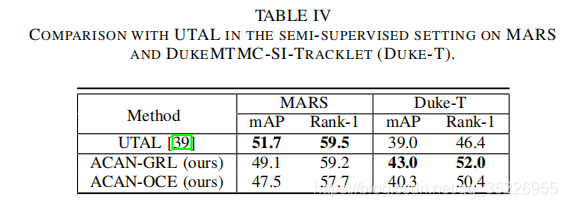
















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









