







 本文深入解析了BiLSTM-CRF模型的结构及工作原理,重点介绍了BiLSTM和CRF层如何结合实现序列标注任务,尤其强调了CRF层在确保标签序列合法性方面的作用。
本文深入解析了BiLSTM-CRF模型的结构及工作原理,重点介绍了BiLSTM和CRF层如何结合实现序列标注任务,尤其强调了CRF层在确保标签序列合法性方面的作用。
BiLSTM-CRF模型:
- BiLSTM-CRF模型结构

- 1、输入句子x通过字嵌入或词嵌入构成向量。如果是字嵌入,则是随机初始化的(char2id);若是词嵌入,则是通过训练好的词向量得到(如glove)。
- 2、字嵌入或词嵌入构成向量构成BiLSTM模型的输入,输出为句子x中各个字符对应的标签。如下图:

不含CRF层的BiLSTM-Softmax模型
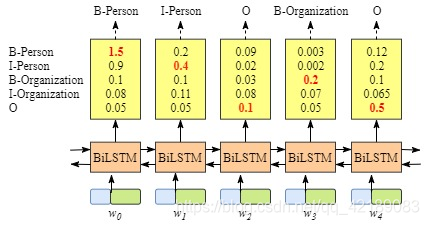
由上图可见,BiLSTM的输出为字符的每一个标签分值。显然,我们仍可以通过挑选每个标签分值最高的作为该字符的标签。例如:图中红色标记的部分作为对应字符的标签。但是,当BiLSTM输出如下结果时:
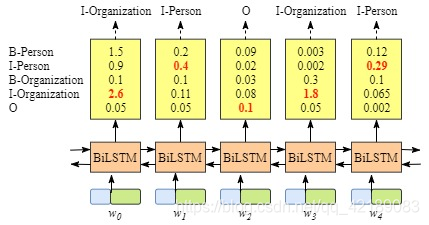
显然,标签序列是"I-Organization I-Person”是错误的。虽然我们可以得到句子x中每个字符的正确标签,但是我们不能保证标签每次都是预测正确的。
CRF层的作用
1、CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习到的。约束可以是:
- I:句子中第一个词总是以标签“B-“ 或 “O”开始,而不是“I-”。
- II:标签“B-label1 I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-Person I-Person” 是合法的序列, 但是“B-Person I-Organization” 是非法标签序列。
- III:标签序列“O I-label” is 非法的.实体标签的首个标签应该是 “B-“ ,而非 “I-“, 换句话说,有效的标签序列应该是“O B-label”。
2、CRF中有转移特征,即它会考虑输出标签之间的顺序性,也会学习一些约束规则
总结
当一个预测序列得分很高时(或概率最大时),并不是取各个位置都是Softmax输出最大概率值对应的标签,还要考虑转移概率相加最大,即还要符合输出规则(B-Person后面不能跟I-Organization),比如假设BiLSTM输出的最有可能序列为(I-O,I-P,O,I-O,I-P),但因为我们的转移概率矩阵中I-O->I-P的概率很小甚至为负,那么根据综合得分(概率),这种序列不会得到最高的分数(概率),即就不是我们想要的序列
reference:


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











