






思想:
选择合适的值做为阈值,实现最佳二分,遍历所有连续属性值后,计算所有已当前Gini()系数大小,选择最大的
例子,
来看看到底是怎样划分的。给定数据集如下(数据集来自周志华《机器学习》
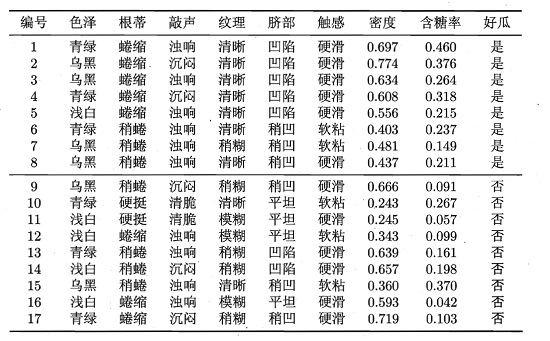
对于数据集中的属性“密度”,决策树开始学习时,根节点包含的17个训练样本在该属性上取值均不同。我们先把“密度”这些值从小到大排序:

根据上面计算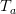
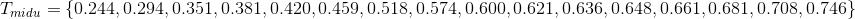
下面开始计算t 取不同值时的信息增益:

选择合适的值做为阈值,实现最佳二分,遍历所有连续属性值后,计算所有已当前Gini()系数大小,选择最大的
来看看到底是怎样划分的。给定数据集如下(数据集来自周志华《机器学习》
对于数据集中的属性“密度”,决策树开始学习时,根节点包含的17个训练样本在该属性上取值均不同。我们先把“密度”这些值从小到大排序:
根据上面计算
下面开始计算t 取不同值时的信息增益:
 1647
1658
1647
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




























