







观前提示:AIStudio 上体验更佳~
背景及工具介绍
本项目为初次体验 PaddleGAN v0.1.0,并且在体验过程中利用 VisualDL 的可视化功能为我们做一些结果的展示,通过可视化结果来帮助我们更好的体验PaddleGAN;
PaddleGAN:飞桨生成对抗网络开发套件–PaddleGAN,为开发者提供经典及前沿的生成对抗网络高性能实现,并支撑开发者快速构建、训练及部署生成对抗网络,以供学术、娱乐及产业应用。
我看到 PaddleGAN v0.1.0 中已经将很多强大并且有意思的功能以接口的形式提供了出来,比如 老照片上色,超分辨率等,
我们就在该项目中实际体验一下这些接口,并且我会把在安装 PaddleGAN 时走过的一些坑写出来,让你们能够快速的上手体验
VisualDL 是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等。可帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
支持标量、图结构、数据样本可视化、直方图、PR曲线及高维数据降维呈现等诸多功能,同时VisualDL提供可视化结果保存服务。具体细节大家可以自行去 VisualDL Github 主页查看;更多其他功能的使用也可以参考我的其他项目
在该项目中我们利用 VisualDL-Image 功能做一些结果的可视化展示,并且通过 VisualDL-Service 共享可视化结果,体会一下 VisualDL 带来的好处。
如果大家觉得这两个套件好用的话,希望大家能够去 PaddleGANGithub、 VisualDl Github 上给它们点一下 star,让官方能够有动力把这些套件做的越来越好!

安装 PaddleGAN
安装遇到的困难:
- 官方套件下载的慢?
我已经将 PaddleGAN 下载好了,因为PaddleGAN 正在高速迭代,如果你想体验最新版本,你可以通过下面的方法可以加速 clone
git clone https://hub.fastgit.org/PaddlePaddle/PaddleGAN.git
- 编译时比较慢?
因为目前在编译的过程中会安装 requirements.txt 中的环境依赖,你可能会因为网络的原因卡在下载的环节;
我们可以通过手动安装依赖来加速编译;在编译前执行下面的代码
!pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple/
- CPU环境下不能安装并且会使项目崩溃?
这个问题目前已经被官方解决了,原因是之前的版本会安装某些必须有GPU才能安装的包;
如果你现在仍然存在这种问题,那么请下载最新版本,该项目中的版本不会有这种问题;
但是编译好之后我建议采用GPU环境,这样运行起来会快一点;
下面我们进行解压安装并切换至工作目录进行编译
当你看到输出中最后是下面这一行,表示环境就安装好了;
Finished processing dependencies for ppgan==0.1.0
# 解压安装
!unzip /home/aistudio/data/data63960/PaddleGAN.zip -d work/
# 切换至工作目录
%cd work/PaddleGAN/
# 安装依赖
!pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple/
# 进行编译
!python setup.py develop
PaddleGAN 接口介绍
ppgan.apps包含超分、插帧、上色、换妆、图像动画生成、人脸解析等应用,接口使用简洁,并内置了已训练好的模型,可以直接用来做应用。
所有接口的详细参数说明可以参考官方文档:https://github.com/PaddlePaddle/PaddleGAN/blob/master/docs/zh_CN/apis/apps.md
下面我们就一一体验一下这些接口,请注意在首次运行时会下载预训练模型。
环境配置
如果打开的是GPU环境,那么接口默认会使用GPU进行推理,你也可以通过如下的方法来切换 CPU、GPU
本项目建议你采用 32G GPU环境;
import paddle
#paddle.set_device('cpu')
paddle.set_device('gpu')
老照片上色
通过接口 ppgan.apps.DeOldifyPredictor 实现,
接口简单说明如下,详细说明参考文档:
DeOldify是一个基于GAN的老照片上色模型。该接口可以对图片或视频做上色。建议视频使用mp4格式。
参数
- output (str): 设置输出图片的保存路径,默认是output。注意,保存路径为设置output/DeOldify。
- weight_path (str): 指定模型路径,默认是None,则会自动下载内置的已经训练好的模型。
- artistic (bool): 是否使用偏"艺术性"的模型。"艺术性"的模型有可能产生一些有趣的颜色,但是毛刺比较多。
- render_factor (int): 图片渲染上色时的缩放因子,图片会缩放到边长为16xrender_factor的正方形, 再上色,例如render_factor默认值为32,输入图片先缩放到(16x32=512) 512x512大小的图片。通常来说,render_factor越小,计算速度越快,颜色看起来也更鲜活。较旧和较低质量的图像通常会因降低渲染因子而受益。渲染因子越高,图像质量越好,但颜色可能会稍微褪色。
在执行预测时,我们可以使用 run,run_image 或者 run_video, 其中run对图片与视频都可以用;具体的参数及返回值请参考文档使用;
在 work/imgs 目录下有一些图片,我是从网上找来的,我们对利用接口对这些图片测试一下;测试代码 …/code/test_deoldify.py 如下:
from ppgan.apps import DeOldifyPredictor
deoldify = DeOldifyPredictor()
pred = deoldify.run_image("../imgs/test_old.jpg")
pred.save('deoldify_result.jpg')
注意 :这里提醒一点,因为接口都是创建预测器进行预测的,如果在notebook中直接调用接口的话,运行结束并不会释放显存,可能会导致显存不够用,我将代码写到了…/code/ 文件夹下的py脚本中,在notebook中执行py脚本;
# 生成的结果在 PaddleGAN/deoldify_result.jpg
!python ../code/test_deoldify.py
利用 VisualDL-Image 进行参数选择
上面我们简单体验了一下接口,将生成的图片保存了下来,如果你对照片效果不满意,你可能需要多次调整参数,通过对比这些结果来选择最满意的那一张;
但是这样一次次试,不仅要花很多时间而且结果对比起来还很麻烦,当然你也可以写一些脚本来实现你的需求,
但是利用 VisualDL-Image 这个功能你可以通过短短几行代码就完成这个任务,下面我们看一下到底怎么用, 代码在 …/code/test_deoldify_with_vdl.py;
from ppgan.apps import DeOldifyPredictor
import numpy as np
import cv2
from visualdl import LogWriter
with LogWriter(logdir="./log/", file_name='vdlrecords.1607330610.log') as writer:
render_params = [4, 8, 16, 32, 64]
origin_img = cv2.imread('../imgs/test_old.jpg')
writer.add_image(tag="deoldify/origin",
img=cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB),
step=0)
for step in range(5):
deoldify = DeOldifyPredictor(render_factor=render_params[step])
writer.add_image(tag="deoldify/render",
img=np.asarray(deoldify.run_image("../imgs/test_old.jpg")),
step=step)
# 测试不同的 render 参数, 参数不要选择太大,否则可能会显存不足
!python ../code/test_deoldify_with_vdl.py
执行完上面的代码之后,我们打开左侧标签栏 可视化->设置logdir->选择 work/PaddleGAN/log/ -> 启动VisualDL服务 -> 打开VisualDL,在打开的网页中,点击样本数据-图像,就可以看到我们不同参数下的结果了;
你可以对比一下不同参数的结果,选择自己最满意的那一张,点击左下角的下载按钮进行下载;
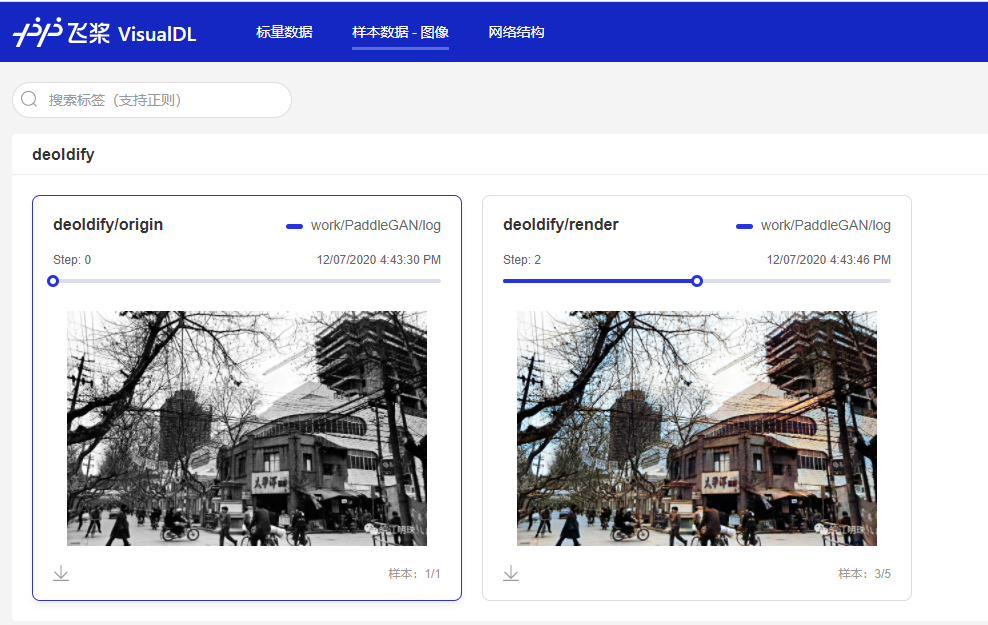
下面接着测试一下 artisitic, 同时我们将这里的原图以及生成的结果也存入上面的 log 文件中,通过指定 LogWriter 的参数 file_name 为刚才的log文件名就可以了;
注意这里的 file_name 要替换为你自己的日志文件名;
from ppgan.apps import DeOldifyPredictor
import numpy as np
from visualdl import LogWriter
with LogWriter(logdir='./log/', file_name='vdlrecords.1607330610.log') as writer:
render_params = [4, 8, 16, 32, 64]
for step in range(5):
deoldify_artistic = DeOldifyPredictor(render_factor=render_params[step], artistic=True)
writer.add_image(tag="deoldify/artistic",
img=np.asarray(deoldify_artistic.run_image("../imgs/test_old.jpg")),
step=step)
# 在不同 render 参数的基础上测试 artisitic 参数,如果你是16G显存,可能会出现显存不足的情况,可以通过减小单次测试的参数量解决
小单次测试的参数量解决
!python ../code/test_deoldify_artisitic.py
如果你刚才没有停止服务,那么你刷新打开的页面(或者等待它自动同步)就可以看到,我们新的图片已经添加进去了;如果不小心关闭了,也可以按照上面的方式重新打开页面,看到如下的结果:
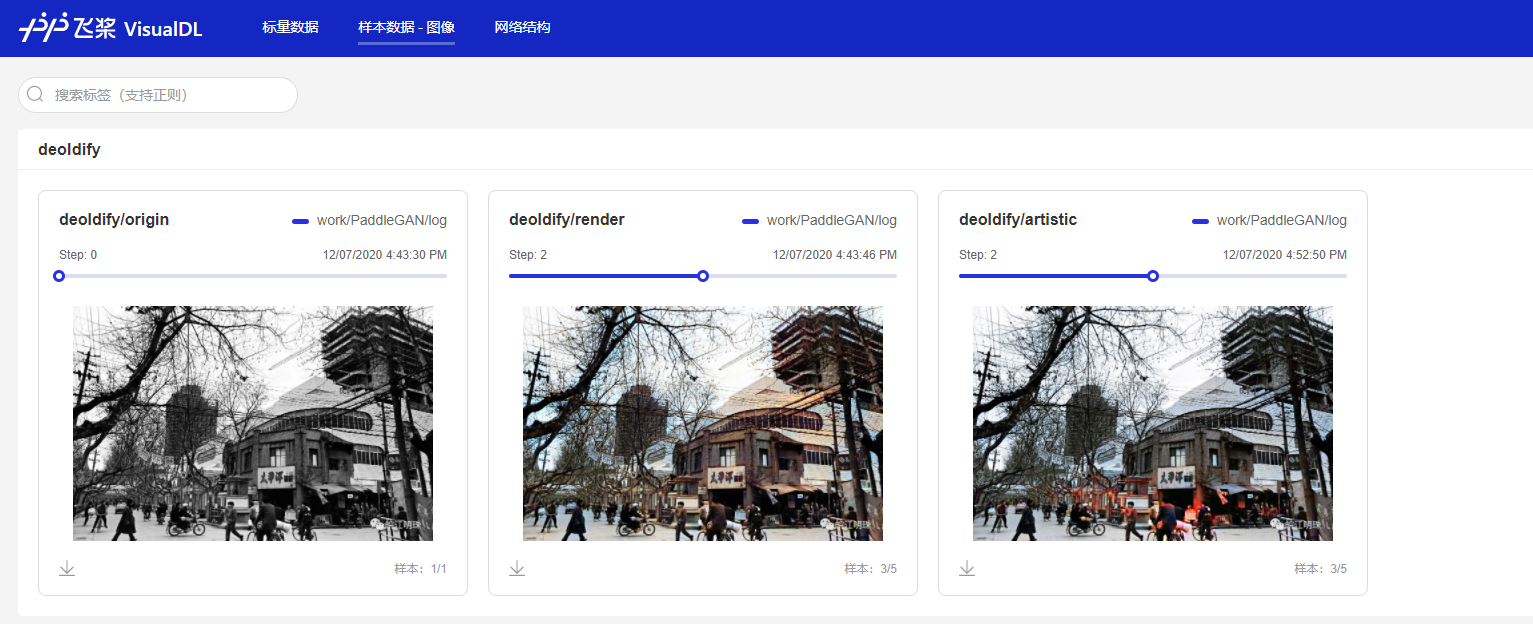
超分辨率
通过接口 ppgan.apps.RealSRPredictor 实现
此接口对输入图片或视频做4倍的超分辨率。建议视频使用mp4格式。具体参数细节请参考文档;
我们把输入图片与超分辨率处理之后的图片都存入上面的log 文件中进行对比,记得要创建新的标签;代码在 …/code/test_sr.py
from ppgan.apps import RealSRPredictor
import numpy as np
import cv2
from visualdl import LogWriter
with LogWriter(logdir='./log/', file_name='vdlrecords.1607330610.log') as writer:
sr = RealSRPredictor()
origin_img = cv2.imread('../imgs/test_sr.jpg')
writer.add_image(tag="sr/origin",
img=cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB),
step=0)
writer.add_image(tag="sr/result",
img=np.asarray(sr.run_image("../imgs/test_sr.jpg")),
step=0)
!python ../code/test_sr.py
如果你刚才没有停止服务,那么你刷新打开的页面(或者等待它自动同步)就可以看到,我们新的图片已经添加进去了;如果不小心关闭了,也可以按照上面的方式重新打开页面,看到如下的结果:
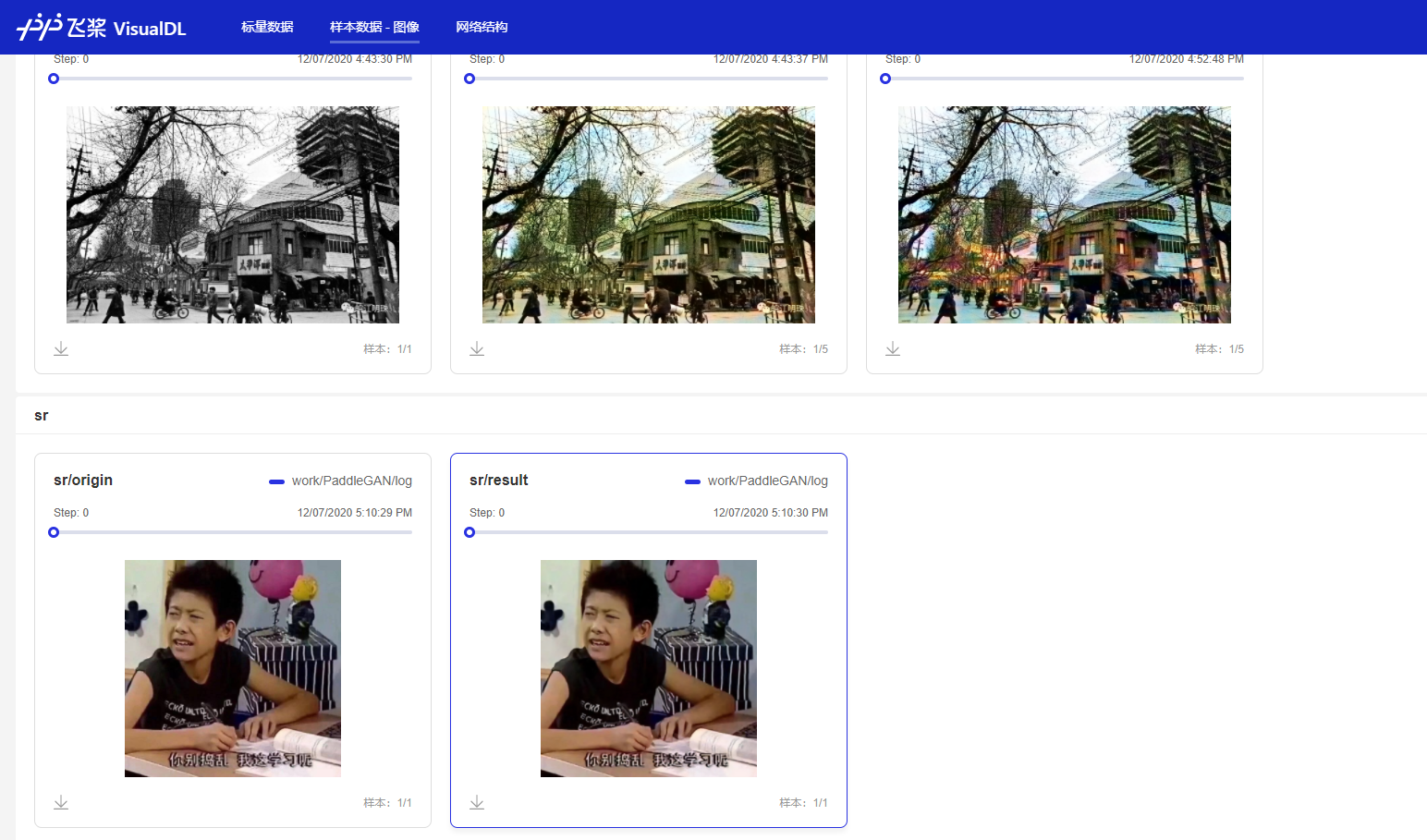
人脸解析
给定一个输入的人脸图像,人脸解析将为每个语义成分(如头发、嘴唇、鼻子、耳朵等);
通过接口 ppgan.apps.FaceParsePredictor 实现,参数比较简单,初始化预测器时接收保存路径,执行预测时接收输入图片路径;
跟之前一样,我们也存入 log 中, 代码如下:
from ppgan.apps import FaceParsePredictor
import numpy as np
import cv2
from visualdl import LogWriter
with LogWriter(logdir='./log/', file_name='vdlrecords.1607330610.log') as writer:
parser = FaceParsePredictor()
origin_img = cv2.imread('../imgs/test_face_parse.png')
writer.add_image(tag="test_face_parse/origin",
img=cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB),
step=0)
writer.add_image(tag="test_face_parse/result",
img=np.asarray(parser.run('../imgs/test_face_parse.png')),
step=0)
使用此接口需要GPU环境,并且需要安装 dlib;可能会编译 5 分钟左右;
!pip install dlib -i https://mirror.baidu.com/pypi/simple/
如果这里报错找不到 output_path ,可能是你使用了其他版本的 PaddleGAN,这里有一个小BUG我已经在项目中的版本修改了,如果你坚持要使用其他版本,你需要去ppgan/apps/face_parse_predictor.py 第55行加上 self.
!python ../code/test_face_parse.py
如果你刚才没有停止服务,那么你刷新打开的页面(或者等待它自动同步)就可以看到,我们新的图片已经添加进去了;如果不小心关闭了,也可以按照上面的方式重新打开页面,看到如下的结果:
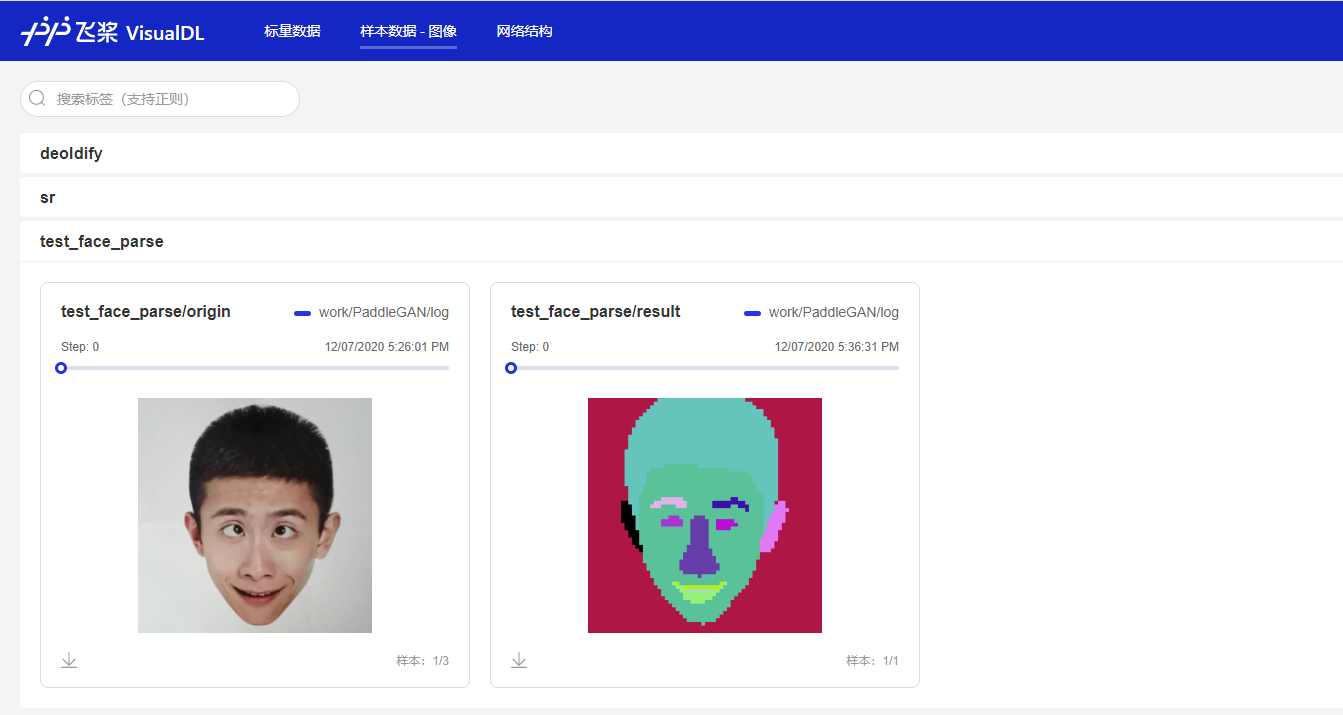
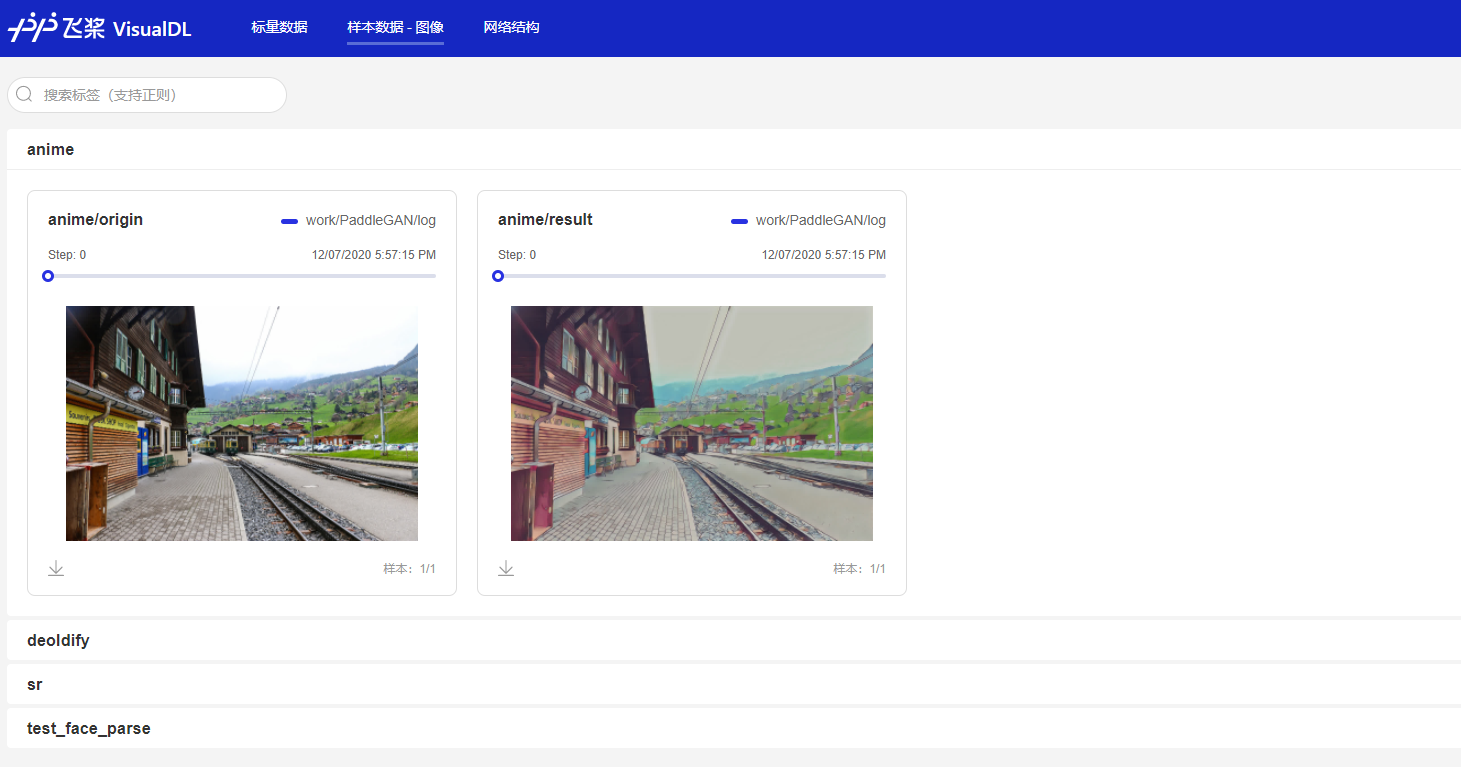
景物动漫化
目前提供的图片应用的接口,还有一个景物动漫化,通过 ppgan.apps.AnimeGANPredictor 实现,
但是这个接口会用到 xx 火炬的一个包,官方目前正在做迁移,该接口可以在本地尝试;这里仅把官方的效果图存入log中,你可以参考官方文档试一下,提示有缺少的包就安装相应的包;
代码在 …/code/add_anime.py 中
import cv2
from visualdl import LogWriter
with LogWriter(logdir='./log/', file_name='vdlrecords.1607330610.log') as writer:
origin_img = cv2.imread('../imgs/animeganv2_test.jpg')
writer.add_image(tag="anime/origin",
img=cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB),
step=0)
result = cv2.imread("../imgs/animeganv2_res.jpg")
writer.add_image(tag="anime/result",
img=cv2.cvtColor(result, cv2.COLOR_BGR2RGB),
step=0)
!python ../code/add_anime.py
如果你刚才没有停止服务,那么你刷新打开的页面(或者等待它自动同步)就可以看到,我们新的图片已经添加进去了;如果不小心关闭了,也可以按照上面的方式重新打开页面,看到如下的结果:
利用VisualDL-Service共享可视化结果
-
此功能是
VisualDL 2.0.4新添加的功能,你需要安装 VisualDL 2.0.4 或者以上的版本,只需要一行代码visualdl service upload即可以将自己的log文件上传到远端, -
非常推荐这个功能,我们上传文件之后,就不再需要在本地保存这些文件,直接访问生成的链接就可以了,十分方便!
-
如果你没有安装
VisualDL 2.0.4 +,你需要使用命令pip install visualdl==2.0.4安装 -
执行下面的代码之后,访问生成的链接, 我也将本项目过程中的某些 log 文件通过此功能上传到了云端, 有需要的话可以进行查看对比;
注意:当前版本上传时间间隔有 5min 的限制,上传的模型大小有100M的限制
!pip install visualdl==2.0.5
!visualdl service upload --logdir log/
通过链接:https://paddlepaddle.org.cn/paddle/visualdl/service/app?id=7dcf5d448008771ecd7a7ddc6e09411f 接可以看到我的日志文件了,是不是很方便呢?
接下来都是视频的应用,但是 VisualDL 目前暂不支持视频文件的展示,所以我们就单独使用PaddleGAN查看一下动作迁移的效果,其他视频的接口,可以参考文档自行体验;
如果你觉得 VisualDL 有必要增加记录视频的功能,欢迎到Github上提issue,他们会看情况满足你的愿望!
动作迁移
给定一张源图片和一个驱动视频,生成一段视频,其中主体是源图片,动作是驱动视频中的动作。
参数
- output_path (str): 设置预测输出的保存路径,默认是output。注意,保存路径为设置output/result.mp4。
- weight_path (str): 指定模型路径,默认是None,则会自动下载内置的已经训练好的模型。
- config (dict|str|None): 设置模型的参数,可以是字典类型或YML文件,默认值是None,采用的默认的参数。当权重默认是None时,config也需采用默认值None。否则,这里的配置和对应权重保持一致
- relative (bool): 使用相对还是绝对关键点坐标,默认是False。
- adapt_scale (bool): 是否基于关键点凸包的自适应运动,默认是False。
- find_best_frame (bool): 是否从与源图片最匹配的帧开始生成,仅仅适用于人脸应用,需要人脸对齐的库。
- best_frame (int): 设置起始帧数,默认是None,从第1帧开始(从1开始计数)。
通过以下代码即可以让杜甫唱歌,生成的视频保存在output/result.mp4。
from ppgan.apps import FirstOrderPredictor
animate = FirstOrderPredictor(relative=True)
animate.run("../imgs/dufu.png","./docs/imgs/fom_dv.mp4")
!python ../code/test_firstOrder.py
执行代码结束之后,将 output/result.mp4 下载到本地就可以查看效果了,快去看杜甫唱歌吧!
下面是我生成的视频:
杜甫唱歌--PaddleGAN三行代码搞定
总结
在该项目中,我们利用 VisualDL-Image 的可视化功能帮助我们体验了 PaddleGAN 的接口,是不是觉得这些功能很有意思呢?
因为 PaddleGAN 目前还处于高速迭代当中,免不了会有一些不完善的地方,但这些坑总是要有人踩的,我已经替你们踩了一部分,希望对你们有帮助;
如果 PaddleGAN 的接口惊艳到你或者接口让你不满意的话,希望你可以去Github上给他们点一点 Star,或者提 issue 反馈一下,让他们更有动力,更快的把这个套件做完善;
同时也别忘记 VisualDL 这个强大的可视化工具,这里只展示了它的冰山一角,关于VisualDL的功能如何使用欢迎参考我的其他项目,如果可以的话,给VisualDL也点一点Star!
如果觉得我写的还不错的话,互相点个关注吧!如果觉得我写的有问题,也欢迎在评论区指正!















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









