







文章目录
PaddlePaddle简介
- PaddlePaddle(飞浆)是百度开发的国产深度学习框架。
- 用PaddlePaddle的好处是可以用AI Studio平台提供的GPU算力进行模型训练,不仅节约时间而且还是免费的。
- PaddlePaddle也提供了像PaddleSeg等一些套件,对于新手上手深度学习模型的项目很友好。
PaddlePaddle GPU版本安装
Step1:创建虚拟环境
conda create -n paddle_gpu python=3.7
Step2:进入创建的环境。
activate paddle_gpu
Step3:安装paddlepaddle(GPU版本),CUDA10.1以及与之配套的cuDNN。
conda install paddlepaddle-gpu==2.2.2 cudatoolkit=10.1 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
出现“done”,说明安装完成。
(CPU版)“conda install paddlepaddle==2.2.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/”
Step4:测试是否安装成功。
依次输入python,import paddle,paddle.utils.run_check()
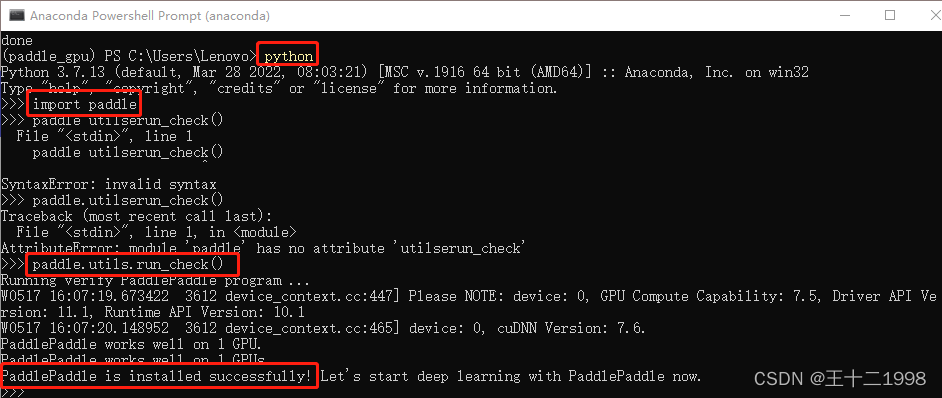
使用PaddlePaddle做线性回归
① 引入库
import paddle
import numpy as np
paddle.__version__
‘2.2.2’
② 定义训练和测试数据
# 定义训练和测试数据
x_data = np.array([[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[2.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[3.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[4.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[5.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]).astype('float32')
y_data = np.array([[3.0], [5.0], [7.0], [9.0], [11.0]]).astype('float32')
test_data = np.array([[6.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]).astype('float32')
- 定义一个简单的线性网络,这个网络非常简单,结构是:
-
更具体的就是一个输出大小为100的全连接层、之后接激活函数ReLU和一个输出大小为1的全连接层,就这样构建了一个非常简单的网络。
-
这里定义输入层的形状为13,这是因为波士顿房价数据集的每条数据有13个属性,我们之后自定义的数据集也是为了符合这一个维度。
③ 定义一个简单的线性网络
# 定义一个简单的线性网络
net = paddle.nn.Sequential(
paddle.nn.Linear(13, 100),
paddle.nn.ReLU(),
paddle.nn.Linear(100, 1)
)
- 接着是定义训练使用的优化方法,这里使用的是
随机梯度下降优化方法。 - PaddlePaddle提供了大量的优化函数接口,除了本项目使用的随机梯度下降法(SGD),还有Momentum、Adagrad等等。
④ 定义优化方法
# 定义优化方法
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=net.parameters())
- 这次训练了10个pass,可根据情况设置更多的训练轮数,通常来说训练的次数和模型收敛有一定的关系。
- 因为本项目是一个线性回归任务,所以我们在训练的时候使用的是平方差损失函数。
- 因为
paddle.nn.functional.square_error_cost求的是一个Batch的损失值,所以我们还要对他求一个平均值。 - PaddlePaddle提供了很多的损失函数的接口,比如交叉熵损失函数
paddle.nn.CrossEntropyLoss。 - 在训练过程中,我们可以看到输出的损失值在不断减小,证明我们的模型在不断收敛。
⑤ 开始训练
# 将numpy类型数据转换成tensor之后才能用于模型训练
inputs = paddle.to_tensor(x_data)
labels = paddle.to_tensor(y_data)
# 开始训练100个pass
for pass_id in range(10):
out = net(inputs)
loss = paddle.mean(paddle.nn.functional.square_error_cost(out, labels))
loss.backward()
optimizer.step()
optimizer.clear_grad()
print("Pass:%d, Cost:%0.5f" % (pass_id, loss))
Pass:0, Cost:0.02406
Pass:1, Cost:0.02354
Pass:2, Cost:0.02302
Pass:3, Cost:0.02252
Pass:4, Cost:0.02202
Pass:5, Cost:0.02154
Pass:6, Cost:0.02107
Pass:7, Cost:0.02061
Pass:8, Cost:0.02016
Pass:9, Cost:0.01972
loss.backward()是将损失loss 向输入侧进行反向传播。
optimizer.step()是优化器对x的值进行更新。
optimizer.zero_grad()清除了优化器中所有x的x.grad。
训练完成之后,我们使用上面克隆主程序得到的预测程序了预测我们刚才定义的预测数据。根据我们上面定义数据时,满足规律y = 2 * x + 1,所以当x为6时,y应该时13,最后输出的结果也是应该接近13的。
⑥ 开始预测
# 开始预测
predict_inputs = paddle.to_tensor(test_data)
result = net(predict_inputs)
print("当x为6.0时,y为:%0.5f" % result)
当x为6.0时,y为:13.21323
使用paddlepaddle解决MNIST问题
Step1:准备数据
1.MINIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字。
2.使用飞桨内置数据集 paddle.vision,datasets.MNIST 定义MNIST数据集的 train_dataset 和 test_dataset。
3.使用 Normalize 接口对图片进行归一化。
import paddle
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')
# 使用transform对数据集做归一化
print('download training data and load training data')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('load finished')
取一条数据,观察一下mnist数据集
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))
Step2:配置网络
以下的代码判断就是定义一个简单的多层感知器,一共有三层,两个大小为100的隐层和一个大小为10的输出层,因为MNIST数据集是手写0到9的灰度图像,类别有10个,所以最后的输出大小是10。最后输出层的激活函数是softmax,所以最后的输出层相当于一个分类器。加上一个输入层的话,多层感知器的结构是:输入层–>>隐层–>>隐层–>>输出层。
# 定义多层感知机
class MultilayerPerceptron(paddle.nn.Layer):
def __init__(self, in_features):
super(MultilayerPerceptron, self).__init__()
# 形状变换,将数据形状从 [] 变为 []
self.flatten = paddle.nn.Flatten()
# 第一个全连接层
self.linear1 = paddle.nn.Linear(in_features=in_features, out_features=100)
# 使用ReLU激活函数
self.act1 = paddle.nn.ReLU()
# 第二个全连接层
self.linear2 = paddle.nn.Linear(in_features=100, out_features=100)
# 使用ReLU激活函数
self.act2 = paddle.nn.ReLU()
# 第三个全连接层
self.linear3 = paddle.nn.Linear(in_features=100, out_features=10)
def forward(self, x):
# x = x.reshape((-1, 1, 28, 28))
x = self.flatten(x)
x = self.linear1(x)
x = self.act1(x)
x = self.linear2(x)
x = self.act2(x)
x = self.linear3(x)
return x
# 使用 paddle.Model 封装 MultilayerPerceptron
model = paddle.Model(MultilayerPerceptron(in_features=784))
# 使用 summary 打印模型结构
model.summary((-1, 1, 28, 28))
配置模型,指定模型训练时所使用的优化算法与损失函数,这里也可以定义计算精度相关的API。
# 配置模型
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()), # 使用Adam算法进行优化
paddle.nn.CrossEntropyLoss(), # 使用CrossEntropyLoss 计算损失
paddle.metric.Accuracy()) # 使用Accuracy 计算精度
Step3:模型训练
在prepare 配置好模型训练的相关算法后,调用fit接口,指定训练的数据集,训练的轮数以及数据的batch_size,可以完成模型的训练。
# 开始模型训练
model.fit(train_dataset, # 设置训练数据集
epochs=5, # 设置训练轮数
batch_size=64, # 设置 batch_size
verbose=1) # 设置日志打印格式
Step4:模型评估
调用evaluate接口并传入验证集。这里我们使用测试集作为验证集。
model.evaluate(test_dataset, verbose=1)
Step5:模型预测
调用 predict 接口并传入测试集。
results = model.predict(test_dataset)
# 获取概率最大的label
lab = np.argsort(results) #argsort函数返回的是result数组值从小到大的索引值
# print(lab)
print("该图片的预测结果的label为: %d" % lab[0][0][0][-1]) #-1代表读取数组中倒数第一列
参考
【飞桨 AI studio】PaddlePaddle快速入门
【飞桨 AI studio】什么是深度学习
【CSDN 社区】「基QI学习」的原创文章-深度学习框架安装(Tensorflow&PyTorch&PaddlePaddle)















 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









