









perf简介
Perf(Performance Event)是Linux 2.6.31后内置的性能分析工具,它相较其它Prof工具最大的优势在于与Linux Kernel紧密结合,可以进行内核甚至硬件级的性能分析。通过它,应用程序可以利用 PMU(Performance Monitor Unit)、tracepoint 和内核中的特殊计数器来进行性能统计,它不但可以分析指定应用程序的性能问题,也可以分析内核的性能问题,从而可以全面理解应用程序中的性能瓶颈。
perf编译配置及安装
在 Linux 内核源码中编译并安装:
#cd 内核源码根目录
#cd tools/perf/
#make && make install
#cp perf target_filesystem/bin/
内核配置要求
几个关键的内核配置项
180:CONFIG_HAVE_PERF_EVENTS=y
186:CONFIG_PERF_EVENTS=y
196:CONFIG_PROFILING=y
414:CONFIG_HW_PERF_EVENTS=y
2029:CONFIG_ARM_PMU=y
- performance 选项
General Setup ->
Kernel Performance Events And Counters ->
[*]Kernel performance events and counters
内核配置选项: PERF_EVENTS [=y] - profile 选项
General Setup ->
[*]Profiling support
内核配置选项: PROFILING [=y] - drivers 选项
Device Drivers->
Performance monitor support->
[*]ARM PMU framework
内核配置选项:ARM PMU framework[=y] - 设备树 pmu 节点要求
编辑 ft2000plus.dts,在/节点下添加 pmu 节点:
pmu {
compatible = “arm,armv8-pmuv3”;
interrupts = <1 7 4>;
};
说明:PMU(Performance Monitoring Unit) 是各CPU厂商随CPU提供的硬件,它允许软件针对某种CPU硬件事件(如cache miss, branch-misses, instructions)设置counter,并且统计该事件次数,当次数到达counter值后,产生中断。软件通过捕获这些中断来考察CPU使用情况。
perf常用命令
perf stat
perf stat 是用于运行指令,并分析其统计结果,可以完整统计应用整个生命周期的信息。
命令格式为:perf stat [ options] [command]
tat means statistic or counting.
其实就是统计、计数。
常用的选项:
• -a: counting for entire system.
• -I: Print count deltas every N milliseconds (minimum: 1ms)
• -C: 指定core.
perf top
显示各函数占用cpu比例。
perf record
perf record 是用于记录粒度更细的统计信息,并保存到文件。比如可以记录单个函数级别的统计信息,
并使用 perf report 来显示统计结果。
命令格式为:perf record [options] [command]
or perf record [options] – command [options]
• -F:采样的频率,通过-F来指定
• -c :Event period to sample.
• -g:记录函数调用栈
perf report
perf report 是将 perf record 生成的文件解析并显示出来。其结果类似于 perf top 的实时显示。
命令格式为:perf report [options]
即对perf record生成的perf.data数据进行展示。
项目中调试用到的一些命令
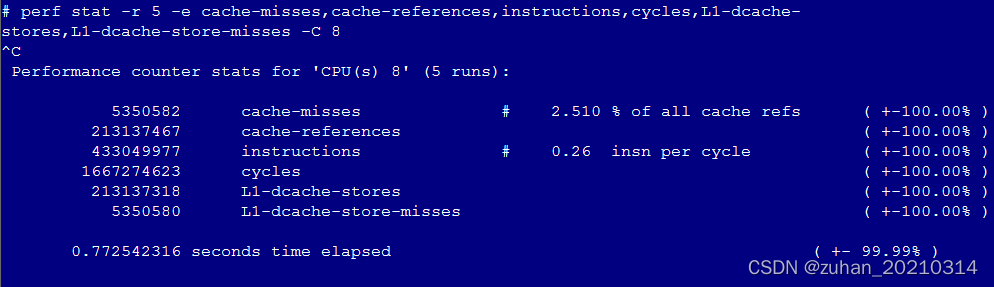
1、
perf stat -r 5 -e cache-misses,cache-references,instructions,cycles,L1-dcache-stores,L1-dcache-store-misses -C 8
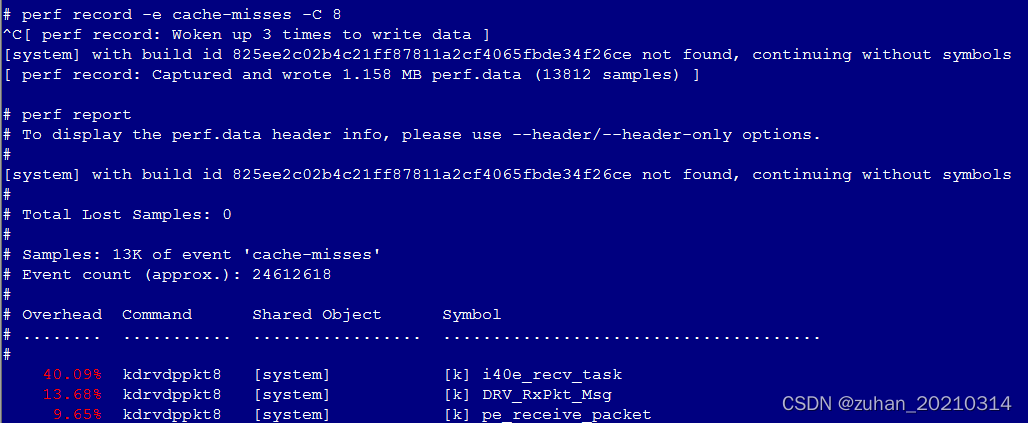
2、
perf record -e cache-misses -C 8
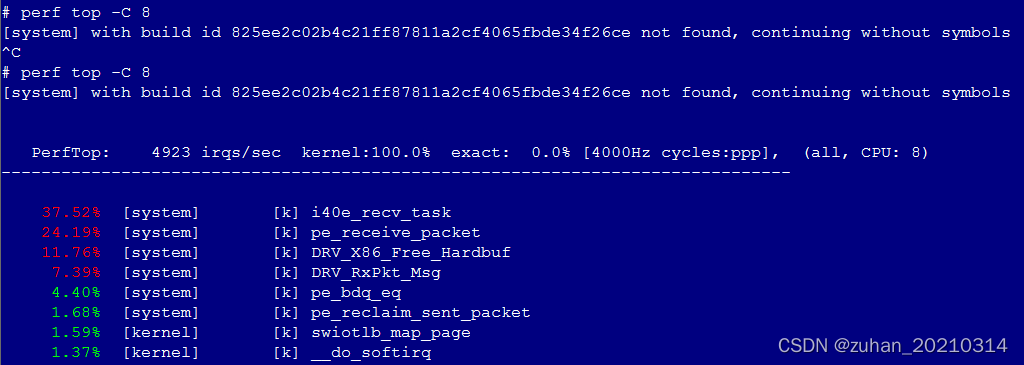
 3、
3、
perf top -C 8
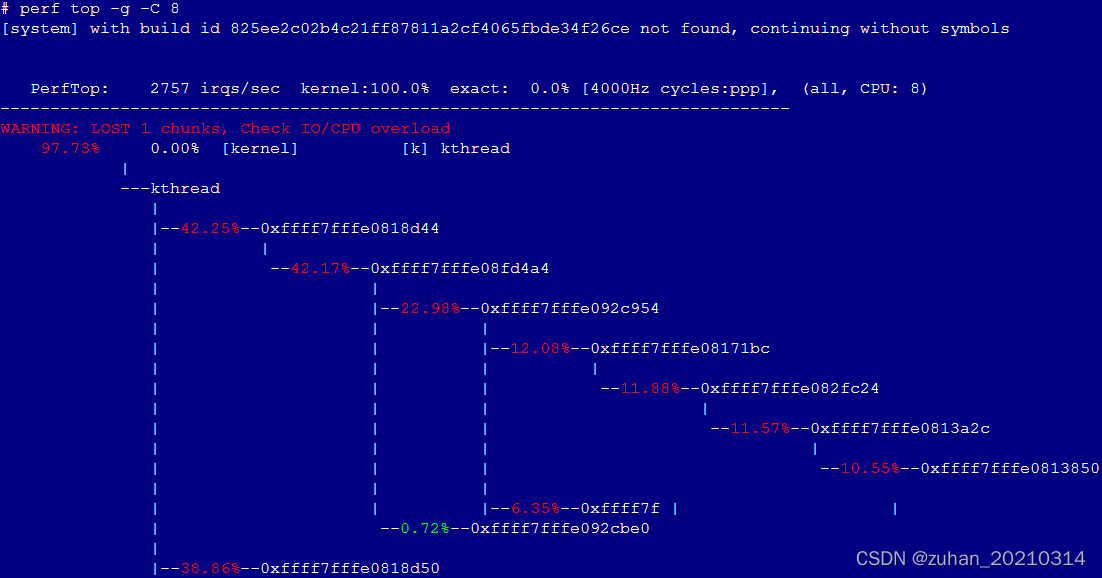
 perf top -g -C 8
perf top -g -C 8
参考链接
视频链接: https://www.bilibili.com/video/BV1hK4y1A7U4?spm_id_from=333.337.search-card.all.click&vd_source=9a8a120f260b2f6555d727c9d48cf27d
perf相关资料:
链接:https://pan.baidu.com/s/15ER6N3azPm0cv1i0mG1QkQ
提取码:lbqq
阿姆达尔定律是指:系统中对某一部件采用更快执行方式所能获得的系统性能改进程度,取决于这种执行方式被使用的频率,或所占总执行时间的比例。”
来自 https://www.baidu.com/s?ie=UTF-8&wd=阿姆达尔定律
- 方法一:使用Linux内核的profile工具,例如profile指出某个支撑组的函数A耗时较多,但是由于安全业务代码较复杂,很多地方都可能调用了函数A,到底是哪个地方导致的性能问题通过profile看不出来,缺乏函数调用流程
- 方法二:把代码的关键路径分为几个大块,使用get_cycles()函数测试每个大块的运行消耗的cycles数量,找出瓶颈,然后再把大块代码继续细分测试cycles数,测试两分钟以上取所有的值累加,也可以取平均值














 7546
7546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









