






向量化——When ever possible, avoid explicit for-loops.
向量化计算意味着你可以在数组上执行操作,而不需要明确地循环遍历其元素,这样可以极大提高效率
将矩阵或者向量的运算用np这个库去运算要比自己写循环运算快一百倍左右,比如:
import numpy as np
import time
a = np.array([1, 2, 3, 4])
print(a)
b = np.random.rand(1000000)
c = np.random.rand(1000000)
tic = time.time()
d = np.dot(b, c)
toc = time.time()
print(d)
print("vectorized version:" + str(1000 * (toc - tic)) + "ms")
d = 0
tic = time.time()
for i in range(1000000):
d += c[i] * b[i]
toc = time.time()
print(d)
print("unvectorized version:" + str(1000 * (toc - tic)) + "ms")
这里的输出结果为:
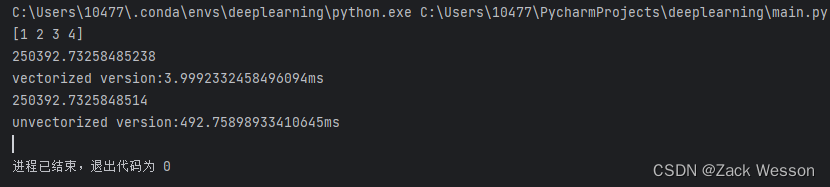
可以看到对两个向量点乘得到相同的结果,但是运行时间大有不同。大概的原理是因为numpy能够充分利用CPU和GPU的并行化去完成程序。
相同的用法还有:
np.exp(v) np.log(v) np.abs(v)-绝对值 np.Maxium(v,0)-与0相比求最大值
np.transpose() - 转置数组 np.dot() - 计算点积(也用于矩阵乘法)
所以在上一节中,由于特征数量很多,因此在for循环中需要再嵌套一个for循环来遍历每个特征值的操作就可以简化为:
用np.zero(n_x,1)将W声明成为一个列向量,然后直接计算
逻辑回归的向量化实现
在逻辑回归中,不同的x[i]会根据sigmoid公式得到不同的a[i]值,从而得到不同的预测结果y[i]. 这些不同的x[i]可以表示为多个列向量,因此可以用一个m行i列的矩阵来表示.
所以基于此,在最开始计算sigmoid函数的指数项时可以将结果表示为一个行向量
,用来保存每次计算的
值(实际上每次计算的
值都是一个列向量). 因此,原先计算
的公式可以表示为
在python里,可以用
Z=np.dot(W^T*X)+b来表示,这里的b可以是一个实数,在运算中python会自动的将其变为向量,也就是broadcasting.
在反向传播中也如此,定义一个1*m的矩阵
用来保存然后有
db=(1/m)np.sum(dZ)
dW=(1/m)Xdz^T总的向量化的反向传播的步骤为:

Python中的广播(Broadcasting)
前提:
- 两个数组在该维度的大小相同。
- 其中一个数组在该维度的大小为1.
作用:将做形式上不可运算的矩阵自动填充为可以运算的形式并计算,比如一个2*3的矩阵加上一个2*1的矩阵,在广播之后python会自动地将后者填充为2*3的矩阵(复制第一列到后两列).
以下是例子:
import numpy as np
import time
A = np.array([[56.0, 0.0, 4.4, 68.0],
[1.2, 104.0, 52.0, 8.0],
[1.8, 135.0, 99.0, 0.9]])
A_T = np.transpose(A)
cal = A.sum(axis=0)
percentage = A / cal.reshape(1, 4)
# print(percentage)
"""由于 NumPy 的广播特性,无论你是否显式地使用 .reshape(1,4),cal 都会被广播到与 A
相同的形状,所以在这种情况下,加不加 .reshape(1,4) 都不会影响结果。"""
A = np.array([[0, 1, 0, 1], [1, 0, 1, 0]])
B = np.zeros((4, 4))
print(B)
arr = A
A = np.vstack((arr, arr)) # 垂直堆叠,参数表示怎样堆叠
C = A + B
print(C)向量的注释
在使用np表示向量的过程过程中,如果我们使用一个数组来表示向量的话就会出现以下问题:
import numpy as np
a = np.random.rand(5)
print(a)
print(a.shape)
a_T = np.transpose(a)
print(a_T)
会发现数组经过转置之后仍然没有变化,而且没有报错. 这是因为在python中,一个一维数组被视为一个向量(在这里(5, )表示这个数组有5个元素,但是什么向量都不是),但是没有确定到底是一个行向量还是一个列向量,所以自然就不存在转置,但是没有报错提示就可能会导致一些隐藏的bug出现,因此我们在创建随机向量时一般使用
np.random.rand(5,1)来创建一个指定维数的确定的向量,如果不确定向量的形式,可以用
assert a.shape == (m,n)
来检查向量的形式
扩展:
数组的秩 (Tensor Rank):在 NumPy 中,数组的“秩”指的是数组的维度数。例如,对于一个形状为 (5,) 的一维数组,其秩为1。对于一个形状为 (5, 3) 的二维数组,其秩为2。对于一个形状为 (4, 3, 2) 的三维数组,其秩为3。以此类推。
使用 numpy.ndim 可以获得数组的秩
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











