






一.transform运行机制
1.transform在什么模块里?
trochvision-计算机视觉工具包,内涵:
torchvision.transforms(提供常用的图像预处理方法);
Torchvision.datasets(提供常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等);
torchvision.model(提供常用的模型预训练,AlexNet,VGG,ResNet,GoogLeNet等)
2.transform.compose的运行顺序

3.运行过程
transform在__getitem__里调用,并且在__getitem__实现数据预处理,然后给到fetch的列表中,不断处理,直到得到一个batchsize大小的数据,然后collate_fn打包成一个data,以下是具体的流程图:
---------------------------------------------------------------------------------------------------------------------------------
DataLoader(进行文件的切分,加载等) |
↓ |
DataLoaderIter(初始化,区分多进程还是单进程) |
↓ |
Samper(采样得到需要加载的文件) → Index(得到目前一个batch的文件的索引) |
↓ ↓ |
DatasetFetcher(根据所给文件索引,组成一个新的文件列表) ↲ |
↓ |
Dataset(将DatasetFetcher的文件索引输入到Dataset里进行处理,同时检测到Dataset里需要进行 transforms) |
↓ |
getitem(从Dataset已经形成的一个batch的数据列表中取得一个元素) |
↓ |
transforms(进行图像除理) |
↓ |
img,Label(对处理好的图像记录其向量形式的元素和标签) |
↓ |
collate_fn(将其打包成一个data) |
↓ |
BatchData(不断循环直到collate_fn打包形成一个完整的batchsize的Batch) |
↓ |
DataLoader(完成一次处理,输入给DataLoader) |
---------------------------------------------------------------------------------------------------------------------------------
2.常用的图像预处理方法
数据中心化,数据标准化;
缩放,裁剪,旋转,翻转,填充;
噪声添加;
灰度变换,线性变换,仿射变换,亮度,饱和度及对比度变换
以下是显示transforms处理过后的图片的代码:
import PIL.ImageShow
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
path = 'test.png'
img = Image.open(path)
img_array = np.array(img) # 要计算均值和方差,需要将图像转化为np的数组形式
mean_values = np.mean(img_array, axis=(0, 1))
std_values = np.std(img_array, axis=(0, 1))
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean_values, std_values)]
)# Compose接收的是一批转化的列表
unnormalize = transforms.Normalize(
mean=-np.array(mean_values) / np.array(std_values),
std=1 / np.array(std_values)) # 定义反标准化操作,因为matplotlib中显示图像数据是[0,255]范围内的,但是transforms会将图像标准化到[0,1]中
class SingleData(Dataset):
def __init__(self, img_path, transform=None):
self.path = img_path
self.transform = transform
self.img = Image.open(self.path)
def __len__(self):
return 1
def __getitem__(self, idx):
if torch.is_tensor(idx): # 必要,因为DataLoader中可能有一些操作需要用列表形式
idx = idx.tolist()
image = self.img
if self.transform: # 必要,判断是否需要transform
image = self.transform(image)
return image
Experiment_dataset = SingleData(path, transform)
Experiment_dataLoader = DataLoader(Experiment_dataset, batch_size=1)
for i, transformed_img in enumerate(Experiment_dataLoader): # enumerate会将DataLoader里的元素列举出来形成一个名为transformed_img的列表,因此直接能够用索引来使用
img_unnormalized = unnormalize(transformed_img[0])
img_np = img_unnormalized.numpy().transpose(1, 2, 0)
img_np = np.clip(img_np, 0, 1)
plt.imshow(img_np)
plt.show()
二.数据标准化-normalize
对图像进行逐个通道进行标准化(将数据分布的均值变为0,标准差变为1)
为什么标准化?
加快收敛速度
*在PyTorch中,图像通常以形状为[C, H, W]的张量形式存在,即首先是颜色通道,然后是高度和宽度。然而,matplotlib期望图像以[H, W, C]的格式,即首先是高度和宽度,然后是颜色通道。permute(1, 2, 0)方法重新排列这些维度,以符合matplotlib的期望格式
*transforms.Compose需要一个transform对象的列表作为输入。
transforms.Normalize(mean,std,inplace=False)
# OUTPUT = (INPUT - mean)/std
# mean:各通道的均值 std:各通道的标准差 inplace:是否原地操作具体的实现步骤是:
1.判断输入图像是否是Tensor,如果不是则直接报错
2.判断是否需要原地计算,如果否则克隆一份(tensor = tensor.clone())
3.将mean和std转化为Tensor形式
4.进行计算,公式为:(tensor-mean)/std并返回
三.数据增强
功能:对训练集进行变换,使得训练集更丰富,从而让模型更具泛化能力
1.裁剪-crop
transforms.CenterCrop((size))
功能:从图像中心裁剪图片
在每次迭代时,每个batch中的data的shape都是一个包含张量的各个维度大小的元组(tuple),四个维度分别为:batchsize,channel,high,wight;而data是一个包含inputs和标签的列表,因此每次操作的元素可以根据inputs的索引来取得,比如inputs[0,..],inputs[1,..]
transforms.RandomCrop(size,padding=None,pad_if_needed = False,fill = 0,padding_mode = 'constant')
功能:从图片中随机裁剪出尺寸为size的图片
size:所需裁剪图片尺寸
padding:设置填充大小-当为a时,上下左右均填充a个像素;当为(a,b)时,上下填充b个像素,左右填充a个像素;当为(a,b,c,d)时,左/上/右/下分别填充abcd
pad_if_need:若图像小于设定size,则填充
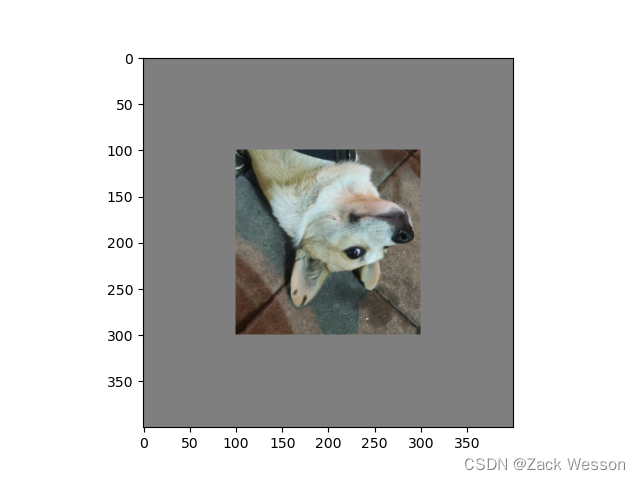
padding_mode:填充模式,有四种模式-
1.constant:像素值由fill设定
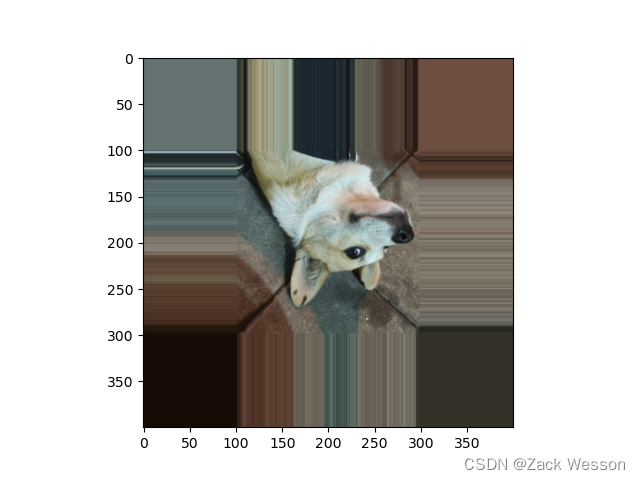
2.edge:像素值由图像边缘像素决定
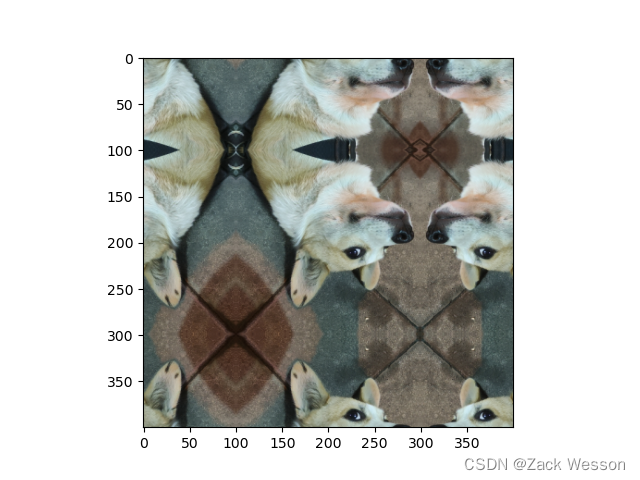
3.reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4]→[3,2,1,2,3,4,3,2]
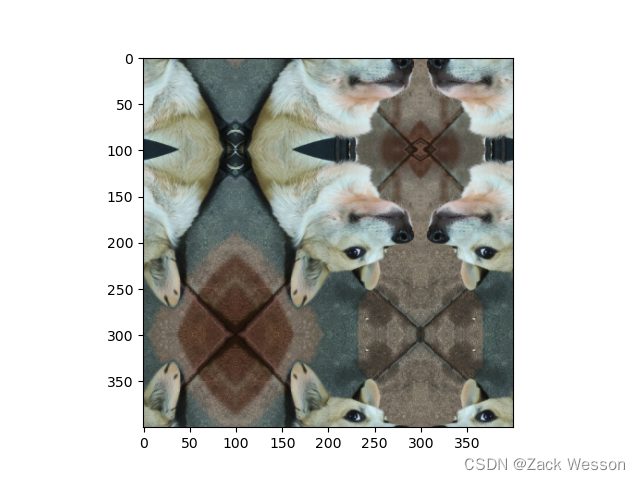
4.symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4]→[2,1,1,2,3,4,4,3]
fill:constant时,设置填充的像素值
transforms.RandomResizedCrop(size,scale=(0.08,1.0),ratio=(3/4,4/3),interpolation)
size:所需裁剪图片尺寸
scale:随机裁剪面积比例
ratio:随机长宽比
interpolation:插值方法-由于裁剪之后的图片尺寸可能会小于size,所以要对裁剪的图片进行插值
transforms.FiveCrop(size)和transforms.TenCrop(size,vertical_flip=False)
在图像的上下左右以及中心裁剪出尺寸为size的五张图片,tencrop对这五张图片进行水平或垂直镜像获得10张图片
注意:FiveCrop返回的形式是一个五维元组(batchsize,crops,H,W,C),因此需要将其转化为tensor或者np.array来显示.
2.翻转/旋转--Flip
RandomHorizontalFlip(p=0.5)/RandomVerticalFlip(p=0.5)
依照概率水平(左右),或者垂直(上下)来翻转
RandomRotation(degrees,resample=False,expand=False,center=None)
随机旋转图片,注意:当batch不为1的时候,由于每个图片可能的大小不同,因此需要resize将图片统一大小
degrees:旋转角度,当为a时,在(-a,a)之间选择旋转角度,当为(a,b)时,在(a,b)之间选择旋转角度 resample:重采样方法
expand:是否扩大图片以保持原图信息
center:是否中心旋转
3.自定义transforms
1.pad
功能:对图片边缘进行填充
transforms.Pad(padding,fill=0,padding_mode='constant')
2.ColorJitter
功能:调整亮度,对比度,饱和度和色相
transforms.ColorJitter(brightness=0,contrast=0,saturation=0,hue=0)
brightness:亮度调整,当为a时,从[max(0,1-a),1+a]中随机选择;当为(a,b)时,从[a,b]中随机选择
contrast:对比度,同brightness
saturation:饱和度,同brightness
hue:色相,当为a时,从[-a,a]中选择参数,注意:a∈[0,0.5];当为(a,b)时,从[a,b]中选择参数,注意:a∈[0,0.5],b∈[0,0.5]
3.Grayscale和RandomGrayscale
功能:依概率将图片转为灰度图(不加random则概率为1)
RandomGrayscale(num_output_channels,p=0.1)
Grayscale(num_output_channels)
num_output_channels:输出通道数 注意:要与normalize的通道数相同,否则会报错
p:概率值
4.RandomAffine
功能:对图像进行仿射变换,由五种基本原子变换构成,分别是平移,旋转,缩放,错切,翻转 RandomAffine(degrees,
translate=None,
scale=None,
shear=None,
resample=False,
fillcolor=0)
degrees:旋转角度设置
translate:平移区间设置.如(a,b),a设置宽(width),b设置高(height),图像在宽维度平移区间为
-img_width*a<dx<img_width*a
scale:缩放比例
fill_color:填充颜色设置
shear:错切角度设置,有水平和垂直错切,
若为a,则仅在x轴错切,错切角度在(-a,a)之间,
若为(a,b)则a设置x轴角度,b设置y轴角度
若为(a,b,c,d),则a,b设置x轴角度,c,d,设置y轴角度
resample:重采样方式
6.对图像进行随机遮挡
RandomErasing(p=0.5,scale=(0.02,0.33),ratio=(0.3,3.3),value)
p:概率值
scale:遮挡区域的面积
ratio:遮挡区域的长宽比
value:遮挡区域的像素值(R,G,B)or(Gray) 注意:在进行randomerasing时,需要用totensor转化为向量形式,而在向量形式下,像素值的范围是(0,1),因此在value值中,需要将对应的255像素转化为0,1区间内的像素
7.transforms.Lambda
功能:用户自定义lambda方法
lambd:lambda匿名函数
transforms.Lambda(arg1 [arg2...]: expression)
对transforms的操作
1.transforms.RandomChoice([transforms1,transforms2...])
功能:从一系列的transforms方法中随机挑选一个
2.transforms.RandomApply([transforms1,transforms2...],p=0.5)
功能:按概率执行一组transforms操作
3.transforms.RandomOrder([1,2...])
功能:对一组transforms操作打乱顺序
自定义transforms操作
要素:
1.仅接受一个参数,返回一个参数
2.注意上下游的输入与输出
通过类实现多参数传入:(compse是通过调用call来一个一个提取transform操作的,所以在明明transform类的时候,也需要定义call函数)
class youtransforms(object):
def __init__(self,...):
...
def __call__ (self,img):
...
return img 注意:大部分transform操作都是输出的img,所以我们自定义的图像最好也是输入img,输出img
















 1769
1769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











