






梯度下降
先从平面坐标系来看,建立W-J(W)坐标系
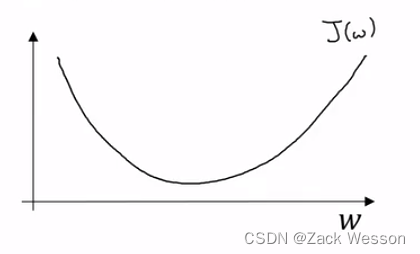
假设代价函数J(W)的图像如图所示,通过以下的公式对每次迭代的W进行更新(上下公式相同)
表示学习率,可以控制我们在每一次迭代或者梯度下降法中的步长大小。这里
代表
对
的导数。因此不断减去导数就会让W的值不断趋近
函数的极值点。
所以在原先的二维函数中,可以用以下公式进行迭代:
这就是所谓的反向传播。
反向传播的目的是根据网络的输出误差来调整网络的权重,使网络的预测更接近实际的标签。
ChatGPT提供的反向传播算法的基本思路如下:
-
前向传播:从输入层开始,通过每一层直到输出层进行计算。每个节点的输出是基于其权重、偏置和激活函数的。
-
计算误差:在输出层,你可以计算网络的预测和实际标签之间的误差。这通常使用损失函数
来完成。
-
反向传播误差:这是算法的核心部分。从输出层开始,计算相对于每个权重的误差梯度。梯度是损失函数的导数,它指向损失最大增加的方向。我们的目标是减少损失,所以我们需要相反的方向来调整权重。
-
权重更新:使用上一步计算出的梯度来更新每一层的权重。这通常使用某种优化算法来完成,例如梯度下降。
-
迭代:重复上述过程(前向传播、计算误差、反向传播误差、权重更新)直到网络的预测误差达到可接受的范围或达到预定的迭代次数。
也就是说在前向传播的基础上,通过梯度下降来回调损失函数的参数,这是反向传播的主要功能。
逻辑回归的梯度下降
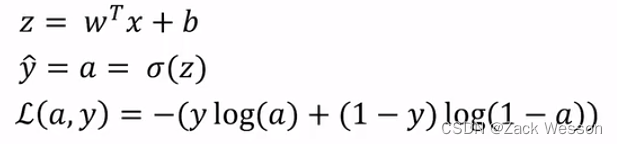
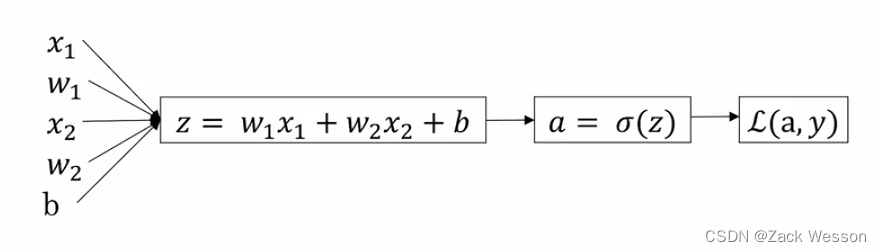
前向传播的流程图如上,此时损失函数是,是一个二元函数,但是我们在模型中的参数只有
(损失函数中的y是指样本)。
因此要进行梯度下降,需要:
1.先计算
2.继续对z求导,往回计算出
3.再根据来计算出
和
在上述例子中,最终:
















 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











