






原文链接: kaggle 数字识别 自编码全连接分类网咯
上一篇: python itertools 模块 迭代相关工具和函数
下一篇: webstorm 手机 调试
玄学调参,激活函数一般relu就行,图像大小的选择是八的倍数,但是自编码网络的收敛还是不确定。。。
有时候全连接的效果很好,有时候很差
对图片不需要做太多处理,比如二值化,形态学操作等,因为会丢失信息,效果会很差
自编码网络的分类器,由于自编码网络已经能够提取到图片的特征,所以全连接分类网络前期很容易收敛到一个较高的值
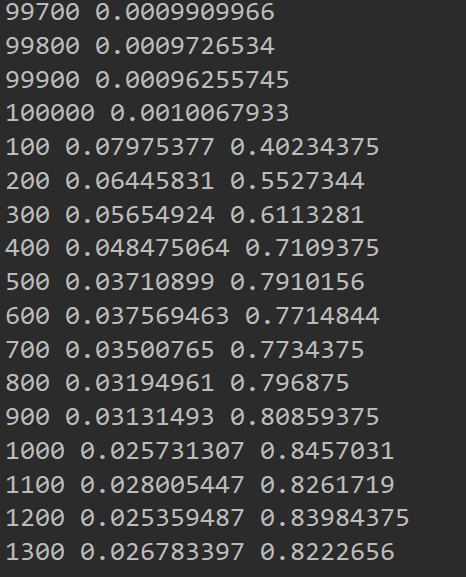
在之前的椭圆分类中用交叉熵效果差点,但在这个里面用交叉熵貌似还行
使用relu代替relu6感觉也会好一点,果然大家说的一般都对
由于三层网络提取特征时需要图片大小为8的倍数,所以将原来28*28转化为32*32
使用中型数据规模,进行训练
自编码的特征提取很是关键,如果能够提取到准确的特征,全连接的分类会好很多
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim
import cv2 as cv
TRAIN_PATH = "D:/data/Digit Recognizer/train.csv"
TEST_PATH = "D:/data/Digit Recognizer/test.csv"
learning_rate = .0001
TRAIN_STEP = 30000
# 大样本
BATCH_SIZE = 256
TEST_SIZE = 512
SHOW_STEP = 100
# 增大特征数据量
IMAGE_SIZE = 32
# 预处理返回的是28*28的图像,需要进行reshape
def preprocessing(img):
img = cv.resize(img, (IMAGE_SIZE, IMAGE_SIZE)).astype(np.float32)
img /= 255.
img = img.reshape((IMAGE_SIZE, IMAGE_SIZE, 1))
return img
in_x = tf.placeholder(tf.float32, (None, IMAGE_SIZE, IMAGE_SIZE, 1))
in_y = tf.placeholder(tf.float32, (None, IMAGE_SIZE, IMAGE_SIZE, 1))
in_y2 = tf.placeholder(tf.float32, (None, 10))
kernel = (5, 5)
# 自编码网络
# 浅一点的网络效果稍微好点。。。
# 层数比较多的话提取的信息时需要使用大样本128
# 导致后面全连接分类效果比较差,误差跳动很厉害
# relu 函数比relu6的效果好一点。。。
with slim.arg_scope(
[slim.conv2d, slim.conv2d_transpose],
activation_fn=tf.nn.relu,
# activation_fn=tf.nn.relu6,
):
print(in_x.shape)
net = slim.conv2d(in_x, 32, kernel, stride=2)
print(net.shape)
net = slim.conv2d(net, 16, kernel, stride=2)
print(net.shape)
core = slim.conv2d(net, 8, kernel, stride=2)
print(core.shape)
net = slim.conv2d_transpose(core, 16, kernel, stride=2)
print(net.shape)
net = slim.conv2d_transpose(net, 32, kernel, stride=2)
print(net.shape)
out_y = slim.conv2d_transpose(net, 1, kernel, stride=2)
print(out_y.shape)
# 自编码loss和train
loss_code = tf.reduce_mean((out_y - in_y) ** 2)
train_code = tf.train.AdamOptimizer(learning_rate).minimize(loss_code)
# 分类网络
with slim.arg_scope(
[slim.fully_connected],
activation_fn=tf.nn.relu,
):
net2 = slim.flatten(core)
print(net2.shape)
net2 = slim.fully_connected(net2, 128)
print(net2.shape)
net2 = slim.fully_connected(net2, 64)
print(net2.shape)
net2 = slim.fully_connected(net2, 32)
print(net2.shape)
net2 = slim.fully_connected(net2, 10)
print(net2.shape)
# 交叉熵效果更好
# 均方误差0.6953125
# loss2 = tf.reduce_mean((net2 - in_y2) ** 2)
# 交叉熵可以达到.98
loss2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=in_y2, logits=net2))
train2 = tf.train.AdamOptimizer(learning_rate).minimize(loss2)
predict = tf.equal(tf.argmax(net2, 1), tf.argmax(in_y2, 1))
accuracy = tf.reduce_mean(tf.cast(predict, tf.float32))
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 训练数据获取
data = np.loadtxt(TRAIN_PATH, dtype=np.str, delimiter=',')
image_data = data[1:, 1:].reshape((-1, 28, 28, 1)).astype(np.uint8)
image_data = np.stack(
[
preprocessing(img)
for img in image_data
]
)
label_data = tf.keras.utils.to_categorical(data[1:, 0], 10).astype(np.float32)
# 训练自编码
id_list = range(len(image_data))
for i in range(1, 1 + TRAIN_STEP):
ids = np.random.choice(id_list, BATCH_SIZE, False)
batch_x = image_data[ids]
batch_y = label_data[ids]
sess.run(train_code, {
in_x: batch_x,
in_y: batch_x,
})
if not i % SHOW_STEP:
ids = np.random.choice(id_list, TEST_SIZE, False)
batch_x = image_data[ids]
batch_y = label_data[ids]
loss_val = sess.run(loss_code, {
in_x: batch_x,
in_y: batch_x,
})
print(i, loss_val)
# 训练全连接分类网
for i in range(1, 1 + TRAIN_STEP):
ids = np.random.choice(id_list, BATCH_SIZE, False)
batch_x = image_data[ids]
batch_y = label_data[ids]
sess.run(train2, {
in_x: batch_x,
in_y2: batch_y,
})
if not i % SHOW_STEP:
ids = np.random.choice(id_list, TEST_SIZE, False)
batch_x = image_data[ids]
batch_y = label_data[ids]
loss_val, accuracy_val = sess.run([loss2, accuracy], {
in_x: batch_x,
in_y2: batch_y,
})
print(i, loss_val, accuracy_val)
# 输出
test_data = np.loadtxt(TEST_PATH, dtype=np.str, delimiter=',')
image_data = test_data[1:, :].reshape((-1, 28, 28, 1)).astype(np.uint8)
image_data = np.stack(
[
preprocessing(img)
for img in image_data
]
)
# 分批次计算,然后聚合结果
ans = []
# 必须整除
for batch in np.split(image_data, 100):
ret = sess.run(
net2, {
in_x: batch
}
)
ret = np.argmax(ret, axis=1)
ans.append(ret)
ans = np.hstack(ans)
print(ans.shape)
# 将结果写入文件
with open('ans.txt', mode='w+', encoding='utf8') as f:
f.write('ImageId,Label\n')
for i, j in enumerate(ans):
f.write(f"{i+1},{j}\n")















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









