






原文链接: Softmax函数 交叉熵 信息熵
上一篇: TensorFlow 退化学习率
下一篇: TensorFlow 线性分类
参考
https://www.cnblogs.com/yjmyzz/p/7822990.html
https://blog.csdn.net/qian99/article/details/78046329
in_y 表示实际概率,net表示网络计算出的结果
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=in_y, logits=net))
softmax(柔性最大值)函数,一般在神经网络中, softmax可以作为分类任务的输出层。其实可以认为softmax输出的是几个类别选择的概率,比如我有一个分类任务,要分为三个类,softmax函数可以根据它们相对的大小,输出三个类别选取的概率,并且概率和为1。
softmax函数的公式是这种形式:
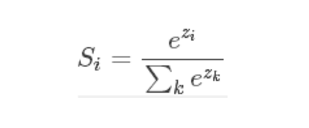
def softmax(x):
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)softmax([1, 2, 3, 4, 5])
array([ 0.01165623, 0.03168492, 0.08612854, 0.23412166, 0.63640865])当数字比较大时,由于阶乘计算增长过快会导致移溢出
进行恒等变化
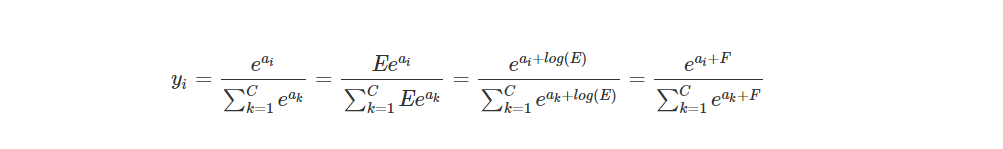
一般取值为
F=−max(a1,a2,...,aC)
这样子将所有的输入平移到0附近(当然需要假设所有输入之间的数值上较为接近),同时,除了最大值,其他输入值都被平移成负数,ee为底的指数函数,越小越接近0,这种方式比得到 nan 的结果更好。
def softmax(x):
shift_x = x - np.max(x)
exp_x = np.exp(shift_x)
return exp_x / np.sum(exp_x)
信息熵
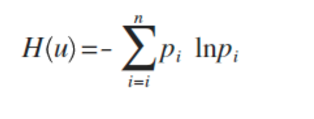
这里p为概率,最后算出来的结果通常以bit为单位。
举例:拿计算机领域最常现的编码问题来说,如果有A、B、C、D这四个字符组成的内容,每个字符出现的概率都是1/4,即概率分布为{1/4,1/4,1/4,1/4},设计一个最短的编码方案来表示一组数据,套用刚才的公式:
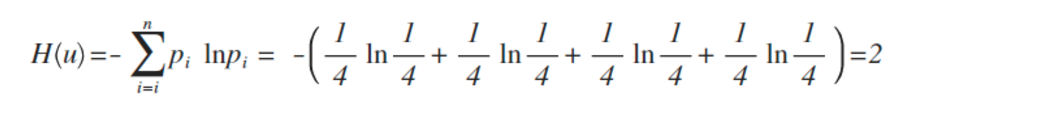
即:2个bit,其实不用算也能想明白,如果第1位0表示A,1表示B;第2位0表示C,1表示D,2位编码搞定。
如果概率变了,比如A、B、C、D出现的概率是{1,1,1/2,1/2},即:每次A、B必然出现,C、D出现机会各占一半,这样只要1位就可以了。1表示C,0表示D,因为AB必然出现,不用表示都知道肯定要附加上AB,套用公式算出来的结果也是如此。
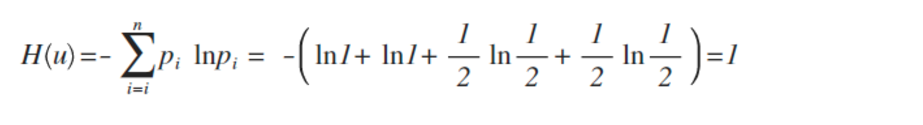
交叉熵
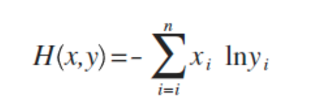
这是公式定义,x、y都是表示概率分布(注:也有很多文章喜欢用p、q来表示),这个东西能干嘛呢?
假设x是正确的概率分布,而y是我们预测出来的概率分布,这个公式算出来的结果,表示y与正确答案x之间的错误程度(即:y错得有多离谱),结果值越小,表示y越准确,与x越接近。
比如:
x的概率分布为:{1/4 ,1/4,1/4,1/4},现在我们通过机器学习,预测出来二组值:
y1的概率分布为 {1/4 , 1/2 , 1/8 , 1/8}
y2的概率分布为 {1/4 , 1/4 , 1/8 , 3/8}
从直觉上看,y2分布中,前2项都100%预测对了,而y1只有第1项100%对,所以y2感觉更准确,看看公式算下来,是不是符合直觉:
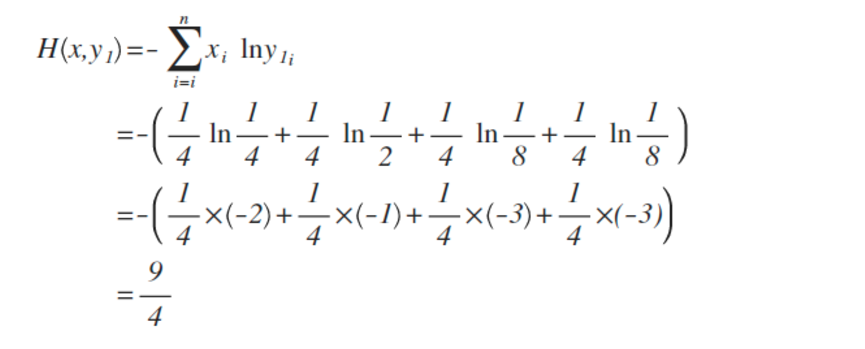
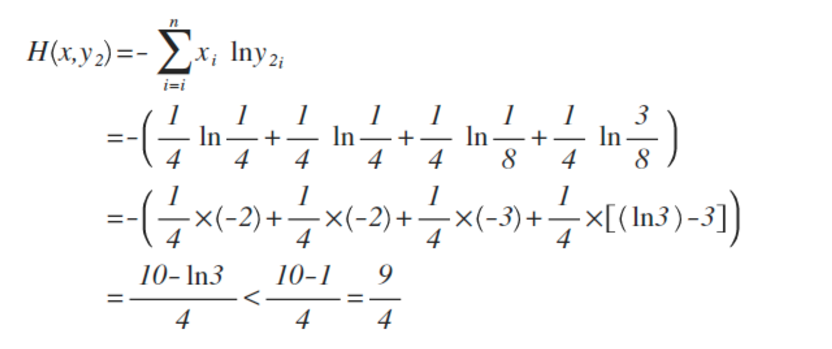
对比结果,H(x,y1)算出来的值为9/4,而H(x,y2)的值略小于9/4,根据刚才的解释,交叉熵越小,表示这二个分布越接近,所以机器学习中,经常拿交叉熵来做为损失函数(loss function)。















 4917
4917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









