







混淆矩阵的基本概念
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
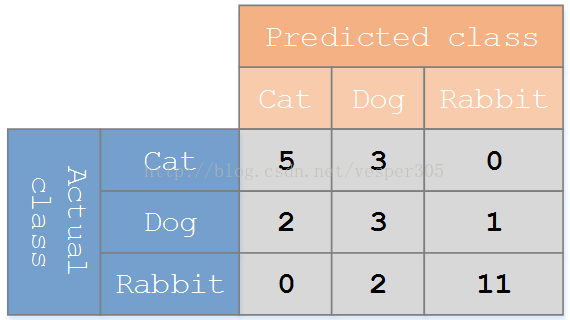
混淆矩阵的结构
混淆矩阵通常以二维表的形式展示,对于二分类问题,结构如下:
| 预测正类 (Positive) | 预测负类 (Negative) | |
|---|---|---|
| 实际正类 (Positive) | TP | FN |
| 实际负类 (Negative) | FP | TN |
这里的正负也就是预测正确和预测错误。
基本用语

Condition Positive § = 测试数据中正例的数量。此处是猫=5。
Condition Negatives (N) = 测试数据中反例的数量。此处是非猫=8。
True Positive (TP) = **是正例,且很幸运我也猜它是正例的数量。**此处4表示有4张图片是猫,且我也猜它是猫。TP越大越好,因为表示我猜对了。这个时候如果你质问我猫不是5张图片吗?那么别急,重新看看TP的定义。然后再看看FN的定义。
False Negative (FN) = **明明是正例,但很不幸,我猜它是反例的数量。**此处1表示有1张图片明明是猫,但我猜它非猫。**FN越小越好,因为FN说明我猜错了。**现在来看5张猫图片是不是全了。其中4张猫我猜是猫,1张猫我猜非猫。
True Negative (TN) = **是反例,且很幸运我也猜它是反例的数量。**此处5表示有5张图片是非猫,且我也猜它是非猫。TN越大越好,因为表示我猜对了。
False Positive (FP) = **明明是反例,但很不幸我猜它是正例的数量。**此处3表示有3张图片是非猫,但我猜它是猫。FP越小越好,因为FP说明我猜错了。
我感觉这么记这些缩写比较好:第一个True or False是指预测对不对,也就是说反斜对角线上开头都是True,正斜对角线上开头都是False。然后第二个Positive or Negative与列索引保持一致即可。
多分类问题的扩展
对于多分类问题,上述指标可以扩展为对每个类别分别计算,然后通过宏平均(macro-average)或微平均(micro-average)等方式综合得到整体指标:
- 宏平均(Macro-average):对每个类别计算指标,然后取平均值,不考虑类别的样本数量。
- 微平均(Micro-average):将所有类别的TP、FP、TN、FN累加后计算指标,考虑了类别的样本数量。
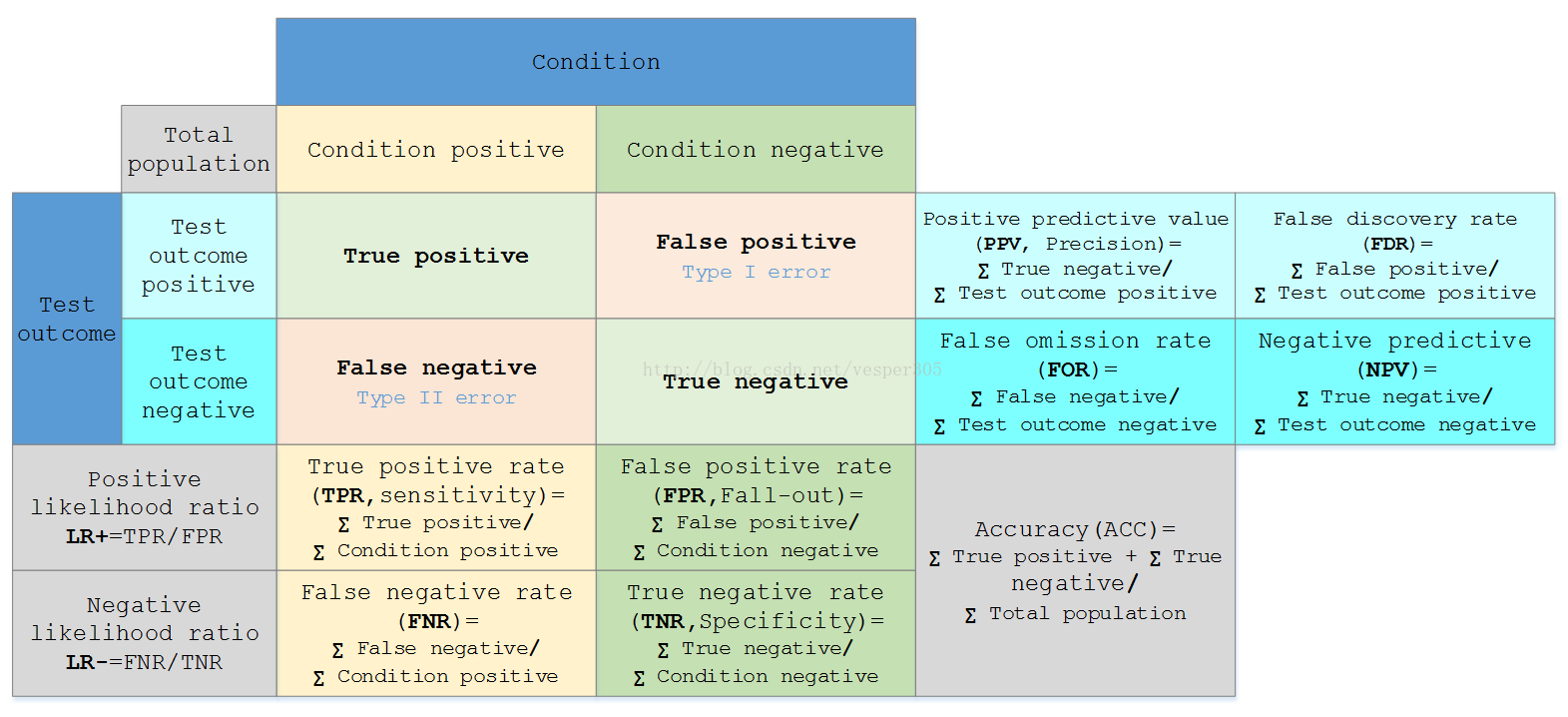
计算评估标准
| 预测正类 (Positive) | 预测负类 (Negative) | |
|---|---|---|
| 实际正类 (Positive) | TP | FN |
| 实际负类 (Negative) | FP | TN |
对着表格看一下以下公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









