







概念
正则化(Regularization)是在机器学习模型中避免过拟合的一种技术。它通过引入一个惩罚项(即正则项)来限制模型的复杂度,以此来提防模型过度依赖训练数据,捕获数据中的噪音信息而导致过拟合现象。简单来说
当你的模型出现过拟合时,会发生什么?过拟合意味着模型具有很高的方差(高方差意味着模型对训练数据中的微小变化非常敏感),当你的模型中的参数越多,模型的灵活性就越大(拟合能力强),在模型中调整的东西越多,就越有可能有高方差。此时正则化就有用了。正则化是限制模型灵活性的一种方法,可以避免过拟合,具体就是降低网络中的权重。
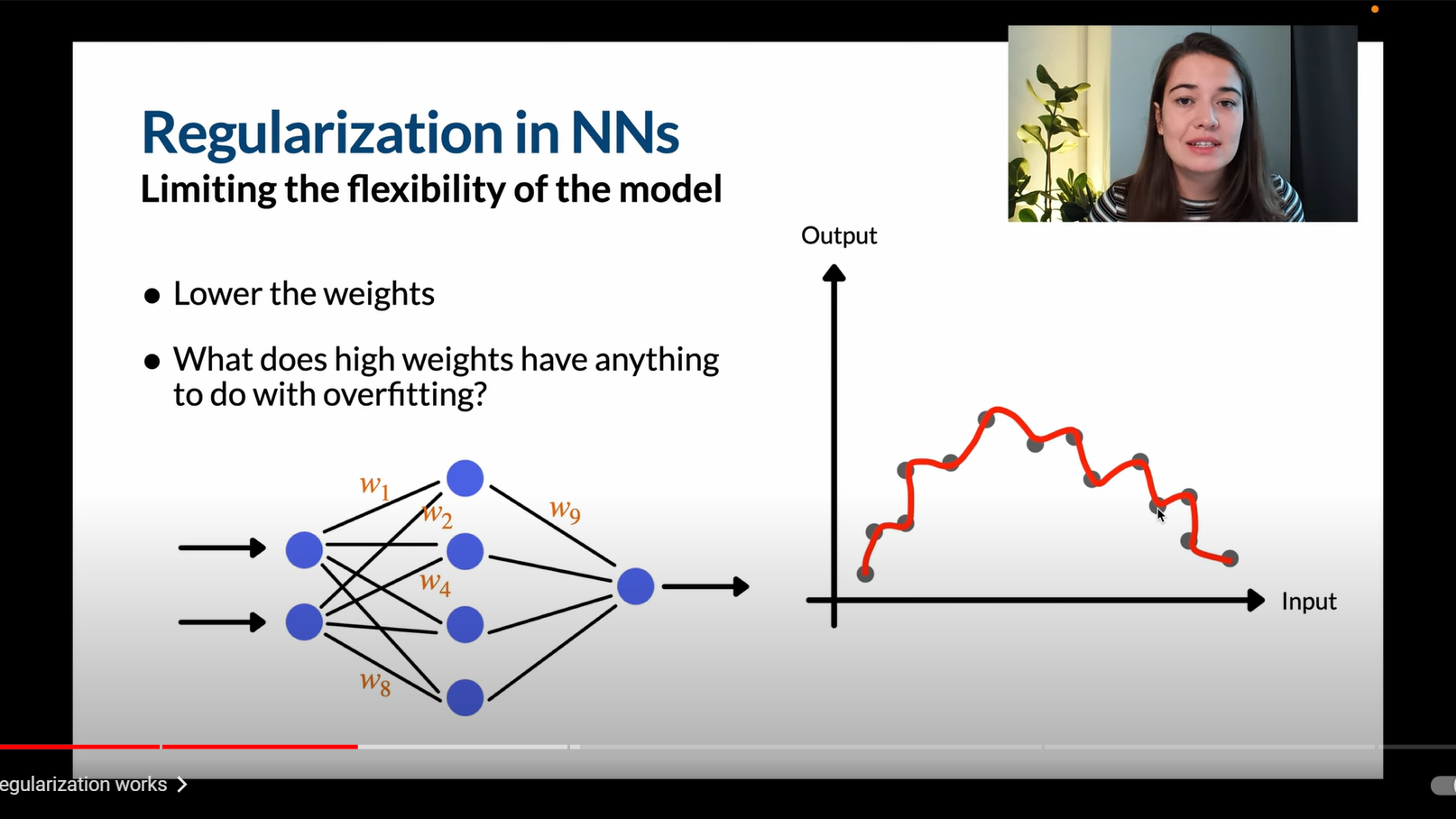
如图,上面这个神经网络的权重意味着输入的重要性,右图是单输入单输出,这个函数很接近输入值,所以过拟合时夸大了某个输入的重要性。如果降低权重,那么就可以缓解过拟合了,这也就是第一种正则化方式。
还有一种降低权重进而缓解过拟合的理解方式:
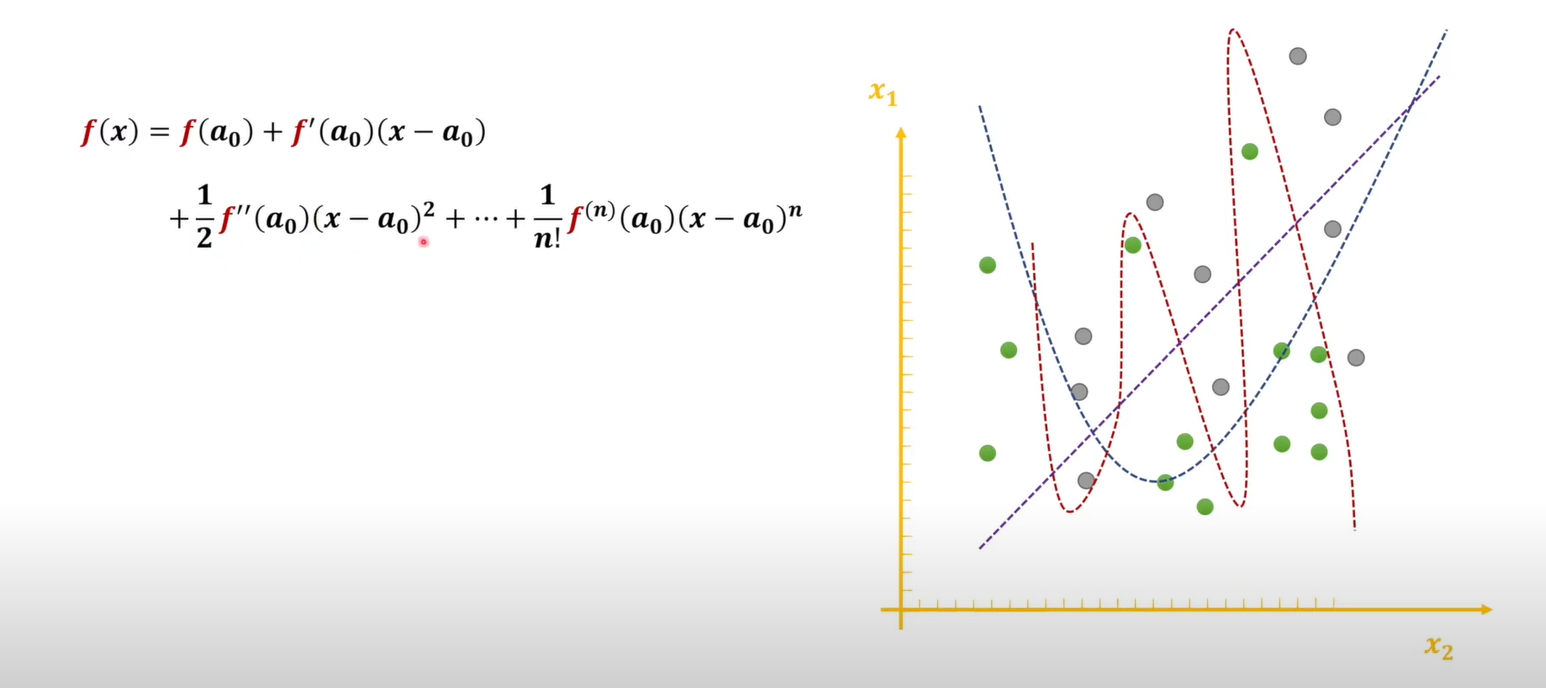
例如我们现在要把右图的灰色和绿色点区分开,需要使用神经网络进行拟合函数,若函数有n次项,那么预测函数就会有n个弯曲点,弯曲点越多在某种程度上表示拟合度更大,所以我们需要减少高次项或者其权重(高次项的系数)。高次项系数越小,那么弯曲程度约不明显,也就缓解了过拟合。
正则化有两种方式,第一种是限制模型的灵活性,例如有L1正则化,L2正则化,Dropout和Early Stoping。第二种是数据增强。
第一种正则化方式
L1和L2正则化的想法是把权重添加到损失计算或成本函数中,用来惩罚有高权重的网络。L1和L2的区别就是L1是把所有参数的绝对值之和作为惩罚,而L2是把所有参数的平方和作为惩罚。
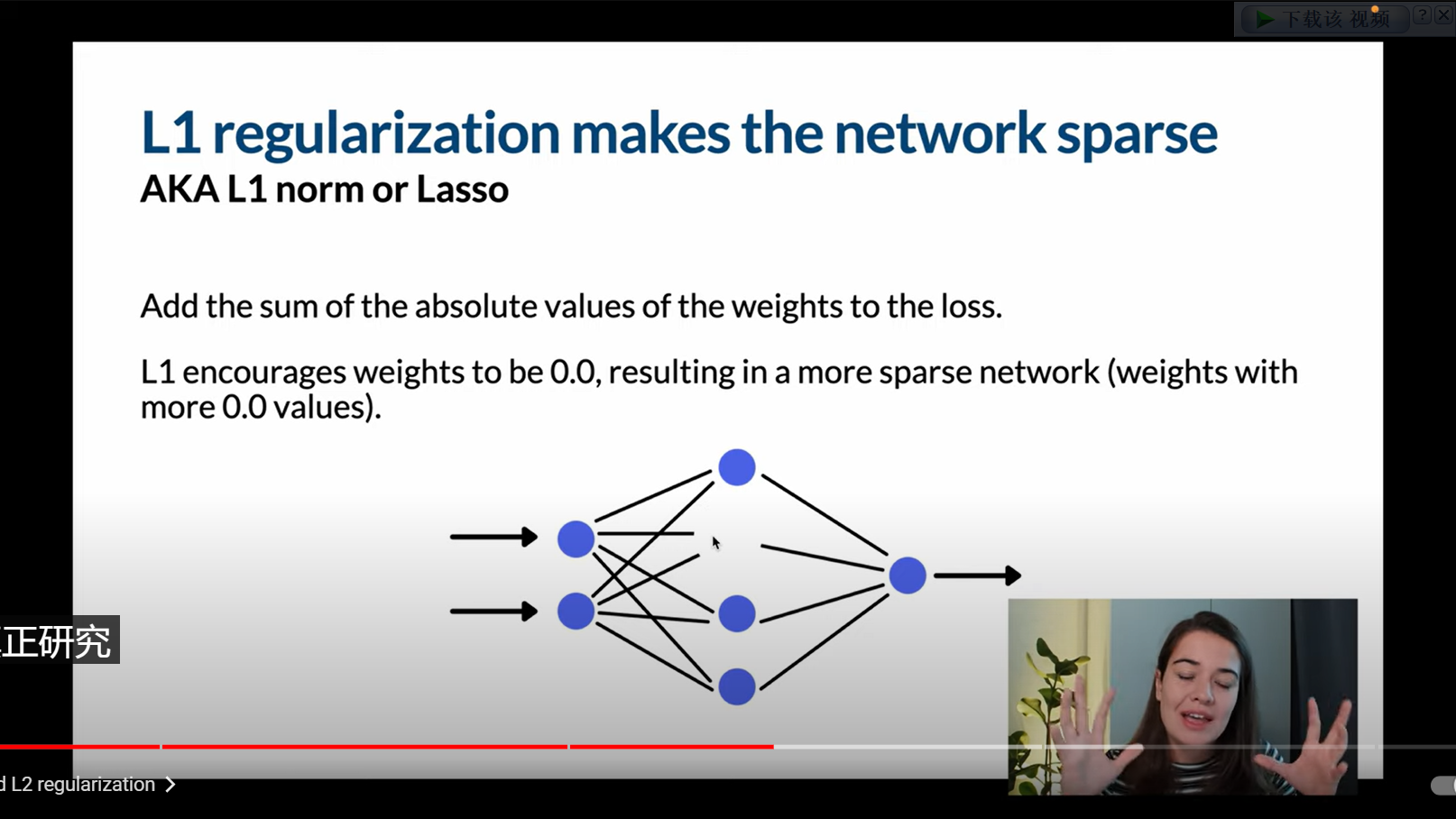
L1正则化
L1正则化鼓励网络把权重降低到0,这样的话某些输出甚至就不会在网络中被计算了。这样的结果就是得到了更稀疏的网络。
L2正则化
而L2正则化会得到参数的平方和,平方相比于小参数,会夸大那些本来就很大的参数。这样的话网络中的权重会有差异,但是L2正则化结束后不会真正的得到稀疏的网络,而是时参数均匀减小。
这两种正则化都有一个名为α的参数,调整α会改变惩罚的力度。
L1和L2正则化如何惩罚神经网络?L1 和 L2 正则化通过在损失函数中加入参数的绝对值和或平方和,分别惩罚模型的参数。这两种正则化方法可以有效防止过拟合,提高模型的泛化能力。
Dropout正则化
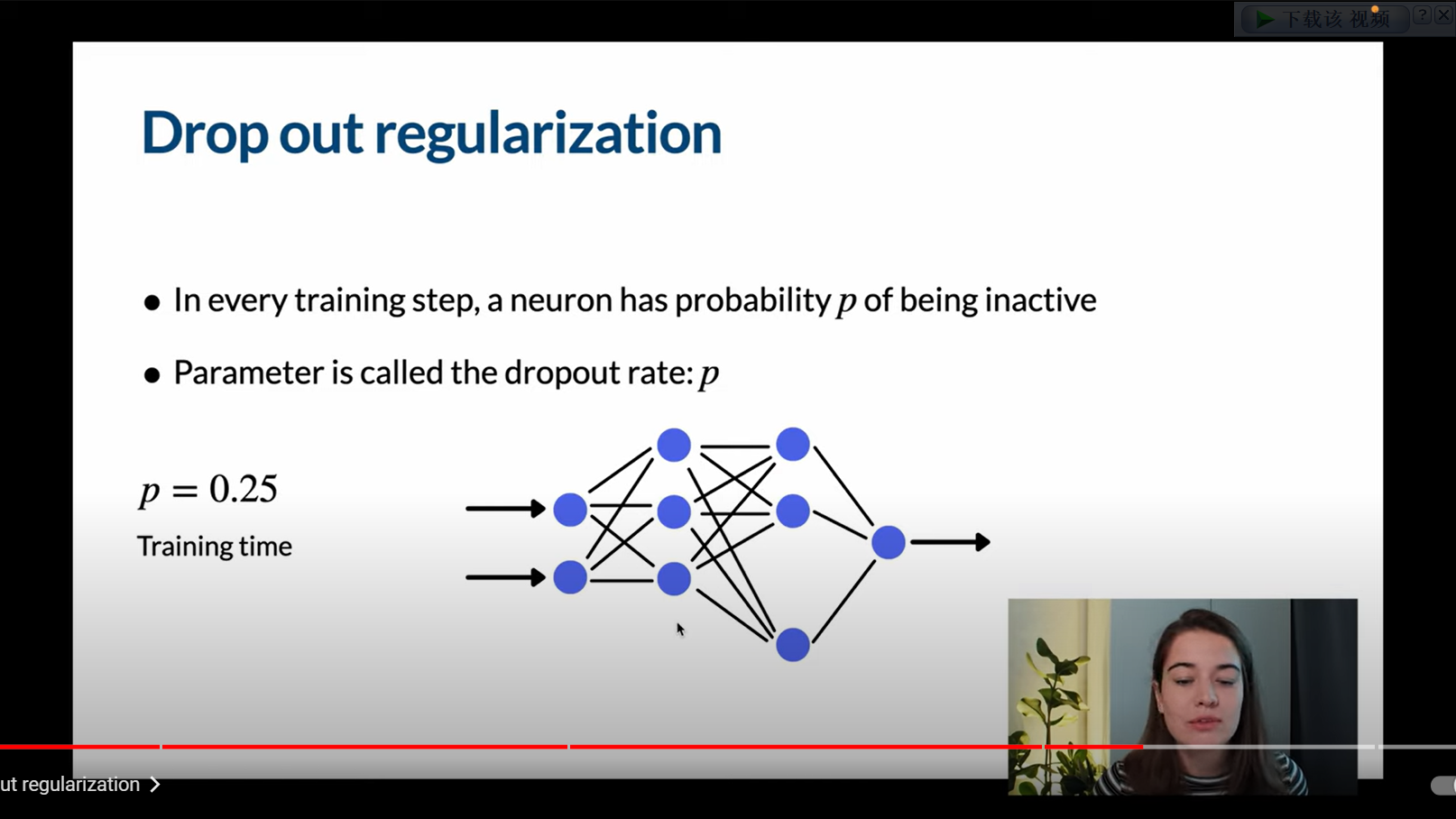
Dropout正则化是在每个训练的步骤中,每个神经元都有丢弃率(Dropout Rate)p的机会是被激活或者不被激活的。需要注意的是,Dropout是在训练时会使神经元失活,而测试时不会。
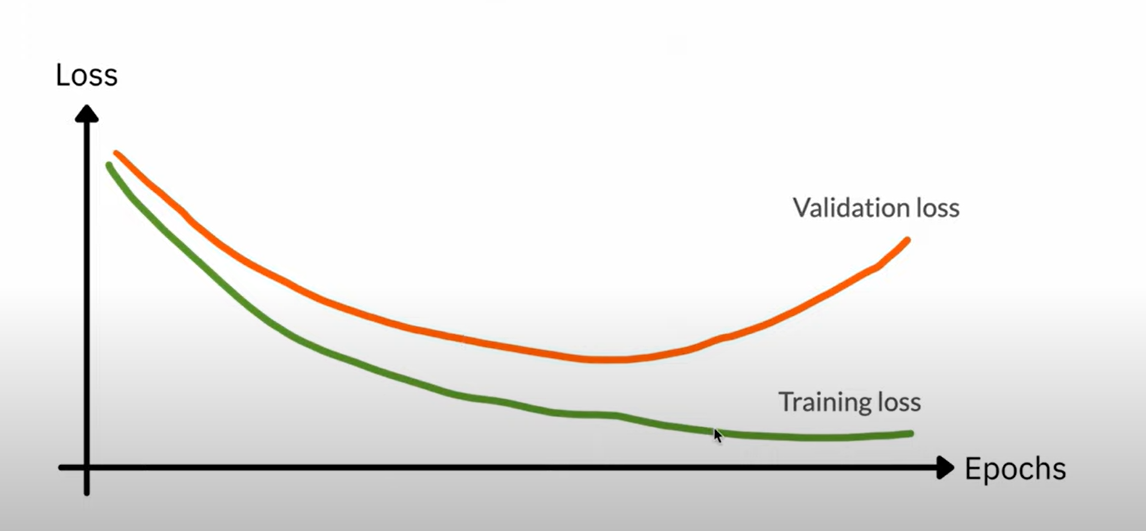
Early Stoping
Early Stoping就是在Test Loss升高之前停止训练,这样的话模型也不会过拟合。
第二种正则化方式
数据增强
数据增强通过在现有的训练样本上应用随机修改,比如旋转、缩放、裁剪或水平翻转,来增加训练数据的多样性。这样可以让模型在不同的场景中都能做出正确的预测,增强模型的泛化能力。

例如:如果我们正在训练一个图像分类器来识别狗,可能会遇到如下的问题:训练数据只包含了狗正面的图片,但我们希望模型能够识别所有角度的狗。这时,我们可以对训练图片进行旋转、翻转等操作,生成不同角度的狗的图片,然后把这些图片加入到训练数据中。这样,即使在测试阶段遇到了从未见过的狗的角度,模型也能给出正确的预测。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









