






1.为什么提前终止训练相当于正则化
左边是提前终止的效果,右边是正则化的效果

可见,只要适当选择停止时的w~,就可以得到类似正则化的效果
从数学角度怎么分析呢?
与分析L2正则化时类似,我们把J的最小值w*附近近似为二次函数
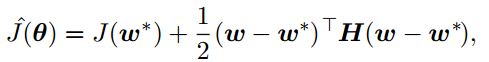
这样可以得到第τ次迭代和第τ-1次迭代的递推表达式
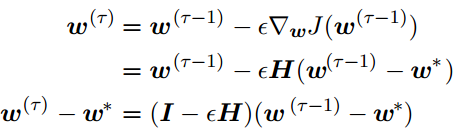
特征值分解
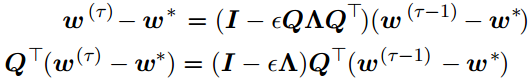
假设
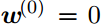
那么可得
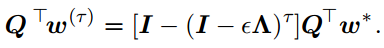
而L2正则化
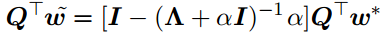
对比可看出,当
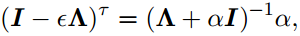
时,正则化和提前终止训练时等价的。
两边取对数,并且在
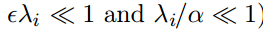
时可以利用级数来分析,把式子近似为
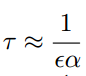
也就是说,训练次数和L2正则化参数是成反比的。也就是说训练次数越多,相当于正则化参数越小,那么正则化效果就会变小。
2.稀疏表示
L1正则化时对参数W进行系数表示,还可以对x进行稀疏表示(比如dropout)
3.集成方法
Bagging方法:构造原数据集的K个不同数据集,每个数据集从原始的数据集中重复采样而成,训练不同的模型。神经网络的解可以从模型平均中受益。
Boosting方法:很多集成方法是为了提高正则化,而Boosting方法为了提高网络容量(拟合各种函数的能力),比如增加隐藏层
4.感知机学习算法
1.分析线性可分模型一定可以经过有限次迭代来求出参数
基于两个条件
a.假设模型是线性可分的
b.数据集带有label
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









