






1 pytorch模型训练
2 libtorch模型部署
(后续研究一下结合TensorRT)
python模型训练以及模型转换
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, 5, 1)
self.conv2 = nn.Conv2d(10, 20, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 20, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 20)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 定义训练函数
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 定义测试函数
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# 主函数用于训练和测试
def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=16, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=100, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 0, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(), "mnist_cnn.pt")
model = model.to(torch.device("cpu"))
model.eval()
var = torch.ones((1, 1, 28, 28))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("mnist_cnn_jit.pt")
from torchvision.models import resnet101
import torch.nn.functional as F
import torch.nn as nn
import torch
import cv2
# import os
# os.system("pip install opencv-python") # 代码安装opencv
# 讲训练好的模型通过jit进行转换/ 测试单张图片
def test2():
#读取一张图片,并转换成[1,3,224,224]的float张量并归一化
image = cv2.imread("E:/test/0/10.png")
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
resized_image = cv2.resize(gray_image, (28, 28))
# image = cv2.resize(image,(224,224))
input_tensor = torch.tensor(resized_image).unsqueeze(0).unsqueeze(0).float() / 255.0
# input_tensor = torch.tensor(image).permute(2,0,1).unsqueeze(0).float()/225.0
# model = resnet101(pretrained=True)
model = Net()
model.load_state_dict(torch.load("D:\proj\python\dl_demo\mnist_cnn.pt"))
model.eval()
#查看模型预测该付图的结果
output = model(input_tensor)
output = F.softmax(output,1)
print("模型预测结果为第{}类,置信度为{}".format(torch.argmax(output),output.max()))
#生成pt模型,按照官网来即可
model=model.to(torch.device("cpu"))
model.eval()
var=torch.ones((1,1,28,28))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("testModel.pt")
if __name__ == '__main__':
# main()
test2()
QT创建 用软件调用模型
#include "mainwindow.h"
#include "ui_mainwindow.h"
#include <qDebug>
#undef slots
#include <torch/script.h>
#include<torch/torch.h>
#include <iostream>
#include <opencv2/opencv.hpp>
#define slots Q_SLOTS
#include <QFileDialog>
MainWindow::MainWindow(QWidget* parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
// Assuming your pushButton is named pushButton
bool test = connect(ui->pushButton, &QPushButton::clicked, this, &MainWindow::slt_pushButton_clicked);
bool test2 = connect(ui->pushButton_2, &QPushButton::clicked, this, &MainWindow::slt_pushButton_2_clicked);
//定义使用cuda
auto device = torch::Device(torch::kCUDA, 0);
auto model = torch::jit::load("D:/proj/cpp/deploy_qt_pytorch/testModel.pt");
}
MainWindow::~MainWindow()
{
delete ui;
}
void MainWindow::slt_pushButton_clicked()
{
filePath = QFileDialog::getOpenFileName(this,
tr("Open Image"), QDir::currentPath(), tr("Images (*.png *.jpg *.bmp)"));
if (!filePath.isEmpty()) {
cv::Mat image = cv::imread(filePath.toStdString());
if (!image.empty()) {
cv::cvtColor(image, image, cv::COLOR_BGR2GRAY);
cv::resize(image, image, cv::Size(28, 28));
QImage qImage(image.data, image.cols, image.rows, static_cast<int>(image.step), QImage::Format_Grayscale8);
ui->label_4->setPixmap(QPixmap::fromImage(qImage));
ui->label_4->setScaledContents(true);
}
else {
qDebug() << "Error loading image!";
}
}
}
void MainWindow::slt_pushButton_2_clicked()
{
if (!filePath.isEmpty()) {
cv::Mat image = cv::imread(filePath.toStdString());
if (!image.empty()) {
cv::cvtColor(image, image, cv::COLOR_BGR2GRAY); // 单通道图像一定要做灰度变换
cv::resize(image, image, cv::Size(28, 28));
// 单通道
auto input_tensor = torch::from_blob(image.data, { image.rows, image.cols }, torch::kByte).unsqueeze(0).unsqueeze(0).to(torch::kFloat32) / 225.0;
// RGB
//auto input_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }).unsqueeze(0).to(torch::kFloat32) / 225.0;
auto model = torch::jit::load("D:/proj/cpp/deploy_qt_pytorch/testModel.pt");
model.to(torch::Device(torch::kCUDA, 0));
model.eval();
//前向传播
auto output = model.forward({ input_tensor.to(torch::Device(torch::kCUDA, 0)) }).toTensor();
output = torch::softmax(output, 1);
argmax_value = torch::argmax(output).item<int>();
max_value = output.max().item<float>();
ui->label->setText(QString("Result: %1").arg(argmax_value));
ui->label_3->setText(QString("Ratio: %1").arg(max_value));
//qDebug() << "label" << argmax_value;
//qDebug() << "value" << max_value;
}
else {
qDebug() << "Error loading image!";
}
}
}
软件打包
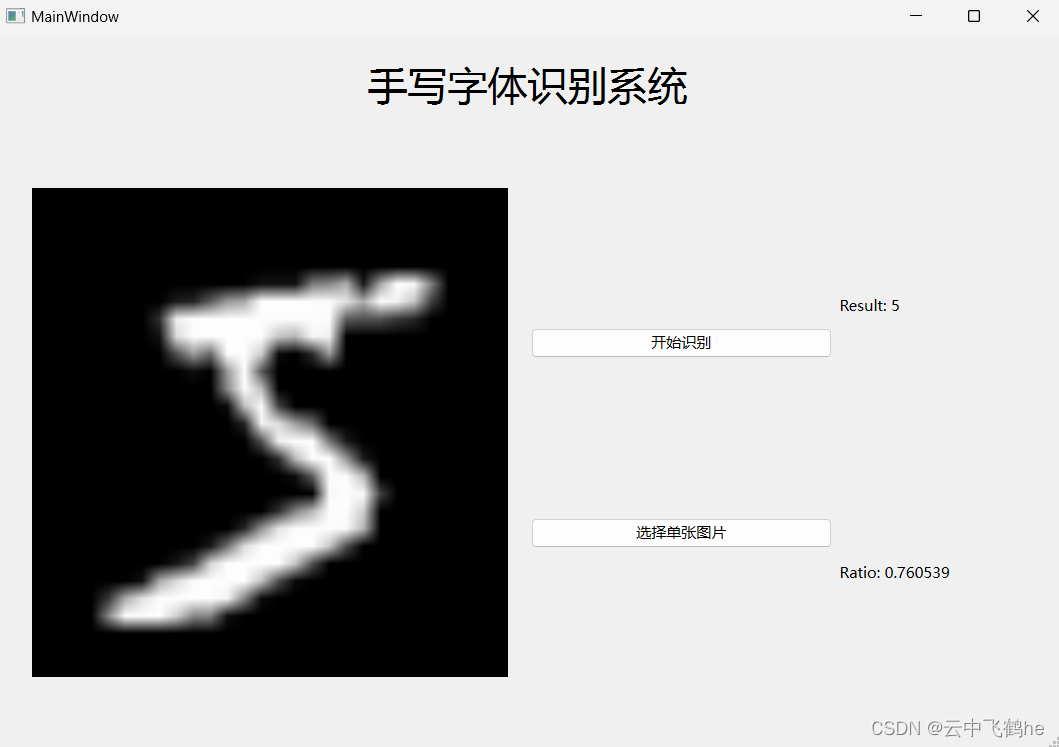
软件最终运行结果














 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









