







Beyond Short Snippets: Deep Networks for Video Classification
Abstract
使用在imageNet上预训练过的CNN(AlexNet或者GoogleLeNet)提取帧级特征,再将帧级特征和提取到的光流特征输入到池化框架或者LSTM进行训练,得到分类结果。
Introduction
1.提出采用CNN来得到视频级的全局描述,并且证明增大帧数能够显著提高分类性能。
2.通过在时序上共享参数,参数的数量在特征聚合和LSTM架构中都作为视频长度的函数保持不变。
3.证明了光流图像能够提升分类性能并用实验结果说明即使在光流图像本身存在大量噪声的情况下(如在Sports-1M数据集中),与LSTM结合后仍然对分类有很大帮助。
主要关注lstm部分,pooling部分省略。
LSTM Architecture
每帧特征后连接五个LSTM层(five layers of stacked LSTMs),512个cells,前一帧的LSTM输出将输入到下一帧的LSTM。
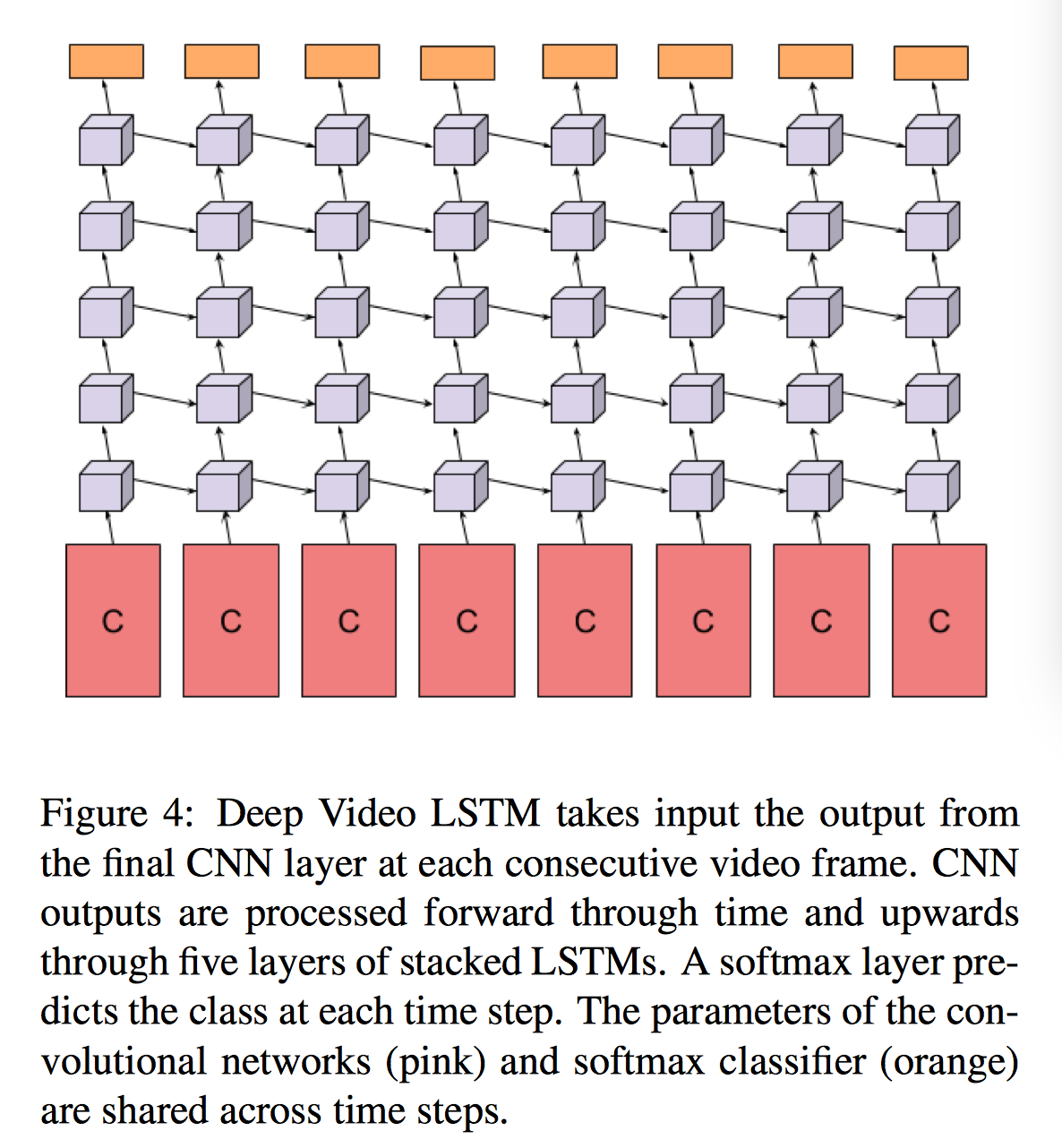
优化方法:随机梯度下降(SGD)
参数:学习率为N(输入视频帧数)X10^-5,并随时间衰减
LSTM Inference
为了 聚合帧级预测得到视频级预测结果,提出四种方式:
1)使用最后一个时间帧的预测结果为最终视频预测结果;
2)对所有时序帧的预测结果进行最大池化得到最终结果;
3)加和所有帧预测结果,并取最大值;
4)结合g(线性插值)对每帧预测结果进行线性加权,求和并返回最大值。
然而这四种方法的效果只有少于1%的区别,其中加权预测往往会带来最优结果。
Optical Flow
每秒随机抽取连续的15帧,并从中随机抽取两帧进行特征提取
以图的方式存储光流特征,阈值为[-40,40],并将光流的水平(第一维)和垂直(第二维)的部分重新缩放到[0,255]的范围,增加第三维并且将数值设置为0。提取完光流图之后采取和帧图像一样的特征提取方法(CNN)。
Experiment
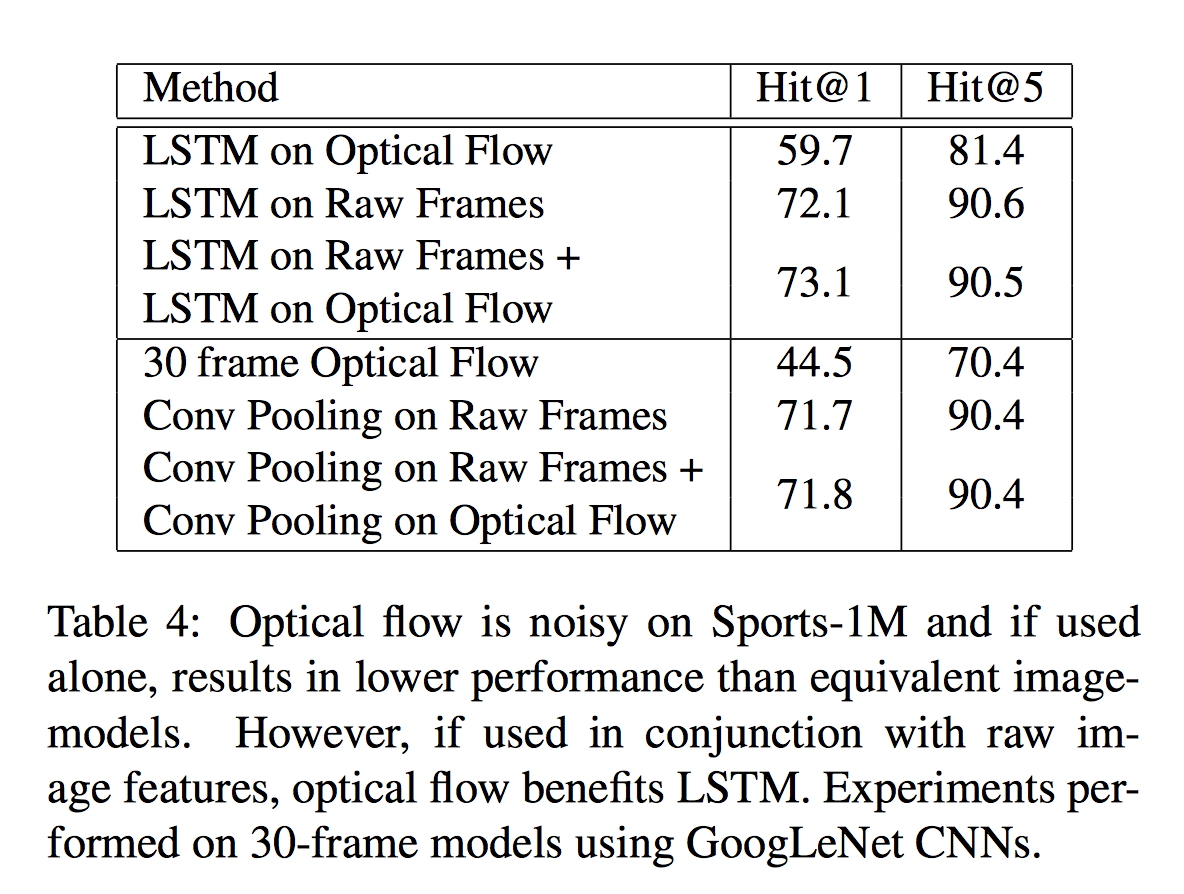
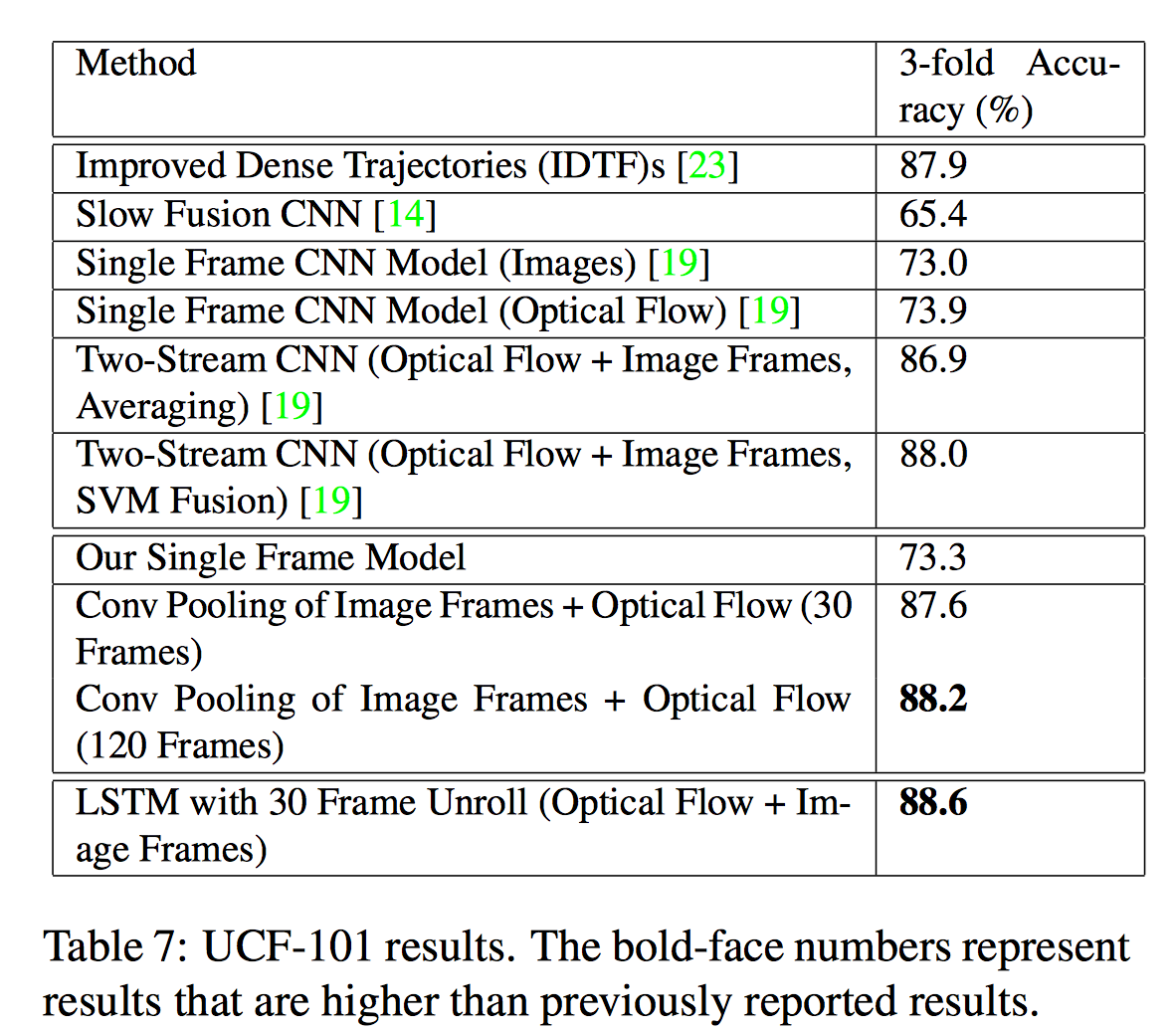
从上述分别在sports-1m和ucf-101数据集上的实验可以看出lstm利用光流及图像帧数据对于分类有一定的帮助。















 3246
3246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









