










作者:CSDN @ _养乐多_
labml-nn库集合了多种神经网络和相关算法的简单 PyTorch 实现,可以帮助我们快速开发深度学习模型。并配有逐行解释代码的文档。
一、网站
给大家分享一个深度学习模型代码逐行解释网站(https://nn.labml.ai/),主流模型都包含在里面。
该网站中文翻译网站:https://nn.labml.ai/zh/
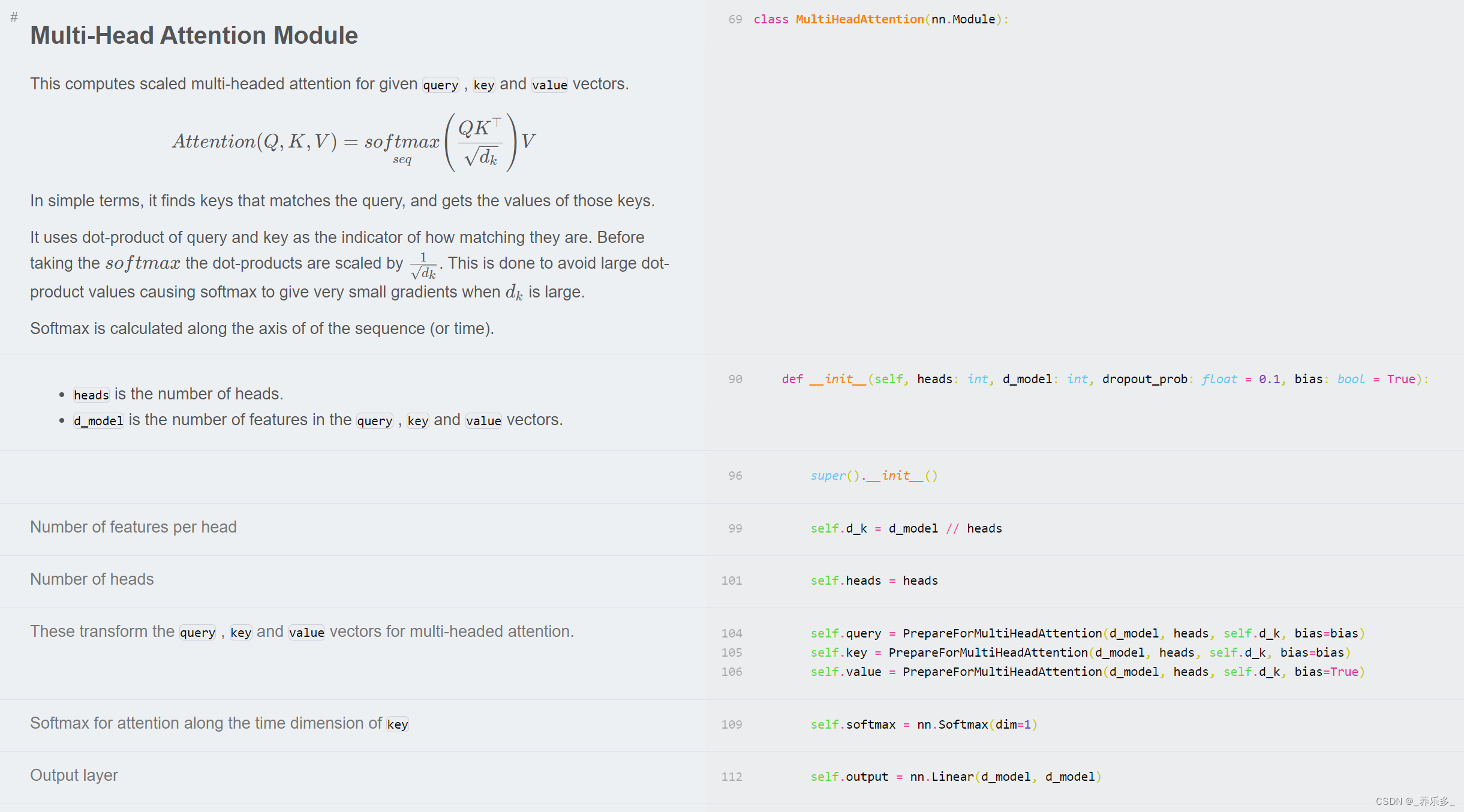
该网站可以逐行解释深度模型代码。
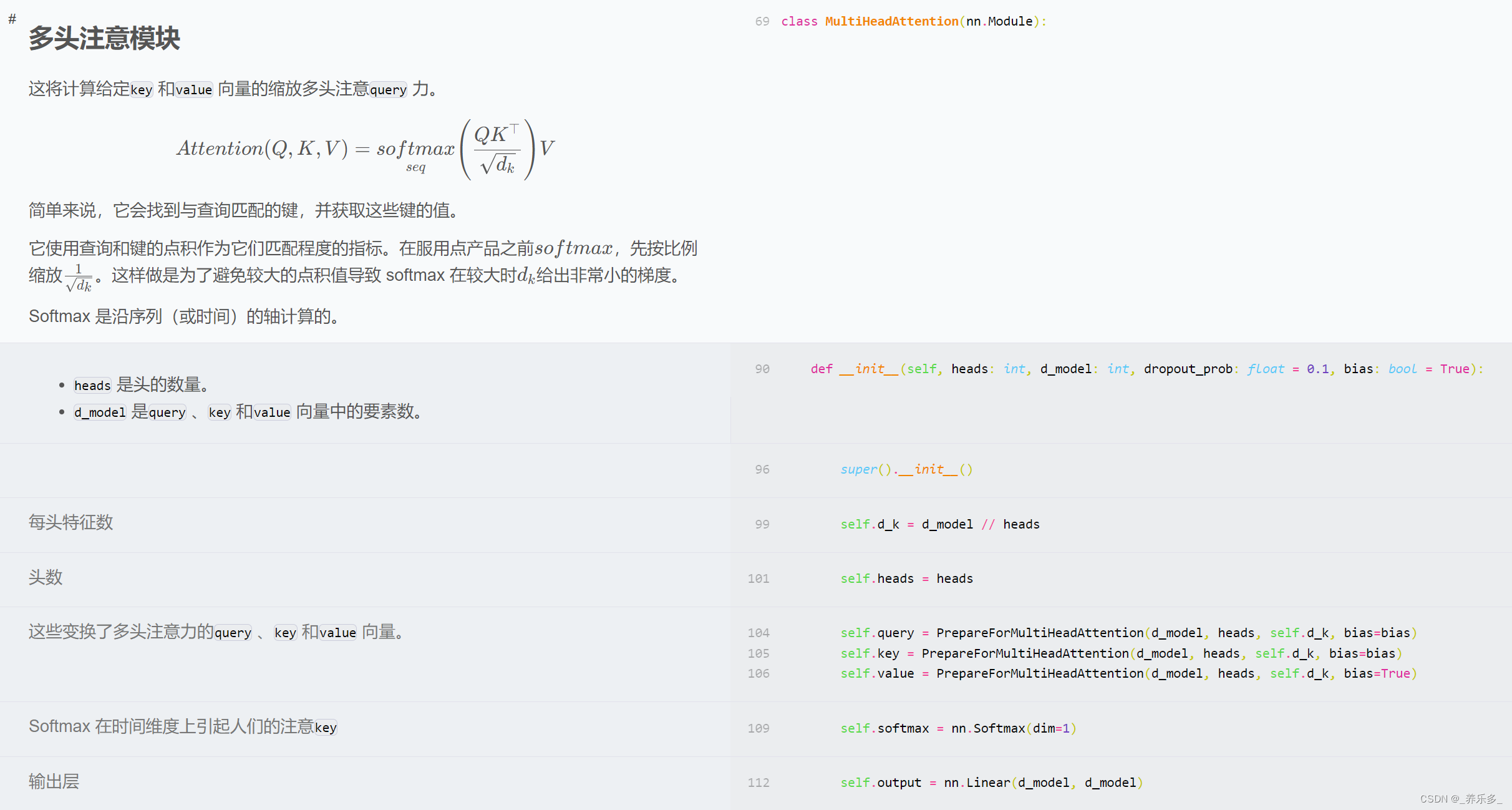
二、主要包含的模型
主要包含的模型有
| 类型 | 项目 |
|---|---|
| Transformers | 多头注意力、Transformer构建模块、Transformer XL、相对多头注意力、旋转位置嵌入(RoPE)、带线性偏置的注意力(ALiBi)、RETRO、压缩Transformer、GPT架构、GLU变种、kNN-LM: 通过记忆实现泛化、反馈Transformer、开关Transformer、快速权重Transformer、FNet、无注意力Transformer、掩码语言模型、MLP-Mixer: 用于视觉的全MLP架构、关注MLPs(gMLP)、视觉Transformer(ViT)、Primer EZ、Hourglass |
| Eleuther GPT-NeoX | 在48GB GPU上生成、在两个48GB GPU上微调、LLM.int8() |
| 扩散模型(Diffusion models) | 降噪扩散概率模型(DDPM)、降噪扩散隐式模型(DDIM)、潜在扩散模型、稳定扩散 |
| 生成对抗网络(Generative Adversarial Networks) | 原始GAN、具有深度卷积网络的GAN、Cycle GAN、Wasserstein GAN、具有梯度惩罚的Wasserstein GAN、StyleGAN 2 |
| 递归高速公路网络(Recurrent Highway Networks) | 循环公路网络 |
| LSTM | |
| HyperNetworks - HyperLSTM | 超网络 - HyperLSTM |
| ResNet | 残差网络 |
| ConvMixer | |
| 胶囊网络(Capsule Networks) | |
| U-Net | |
| Sketch RNN | |
| 图神经网络(Graph Neural Networks) | 图注意力网络(GAT)、图注意力网络v2(GATv2) |
| 强化学习(Reinforcement Learning) | 近端策略优化与广义优势估计、具有双网络、优先回放和双Q网络的深度Q网络 |
| 反事实遗憾最小化(CFR) | 用 CFR 解决信息不完全的游戏,例如扑克。库恩扑克 |
| 优化器(Optimizers) | Adam、AMSGrad、具有预热的Adam优化器、Noam优化器、修正的Adam优化器、AdaBelief优化器、Sophia-G优化器 |
| 标准化层(Normalization Layers) | 批标准化、层标准化、实例标准化、组标准化、权重标准化、批-通道标准化、DeepNorm |
| 蒸馏(Distillation) | |
| 自适应计算(Adaptive Computation) | PonderNet |
| 不确定性(Uncertainty) | 用于分类不确定性量化的证据深度学习 |
| 激活函数(Activations) | 模糊平铺激活(Fuzzy Tiling Activations) |
| 语言模型抽样技术(Language Model Sampling Techniques) | 贪婪抽样、温度抽样、前k个抽样、核抽样(Nucleus Sampling) |
| 可扩展训练/推理(Scalable Training/Inference) | Zero3内存优化 |
三、github代码
https://github.com/labmlai/annotated_deep_learning_paper_implementations/tree/master/labml_nn
四、pip安装
pip install labml-nn



















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











