






第16次周报
一、摘要:
This week I read an article about the bert model,Bert is a pre-trained language model that consists of multiple bidirectional layers of transformer encoder,BERT is conceptually simple and empirically,It can be used to process multiple NLP on downstream tasks,On experiment,the bert model outperforms the best previously models。In addition,I also learned about the details of the transformer model。
这周我读了一篇关于bert模型的文章,bert是一个预训练的语言模型,由多个双向的transformer编码器组成,bert在概念上更简单,而且在实验上表现更好,它可以被用于处理多个NLP的下游任务上。实验证明,bert比以前的模型效果更好。此外,我还对transformer模型的细节进行了学习。
二、 transformer细节补充
为什么摒弃RNN和CNN会更好?
传统的基于RNN的Seq2Seq模型难以处理长序列的句子,无法实现并行,并且面临对齐的问题。
RNN的T 时刻隐层状态的计算,依赖两个输入,一个是 T 时刻的句子输入单词 Xt,以及另外一个输入,T 时刻的隐层状态 St 还依赖 T-1 时刻的隐层状态 S(t-1) 的输出,它本身有的序列依赖特性所以导致RNN的并行能力差,这就导致RNN计算速度很慢。而self-attention机制和CNN可以进行并行计算,并且self-attention机制能够很好地捕捉长文本之间的关系,同时不存在长期依赖问题。
CNN不能直接用于处理变长的序列并且样本单层卷积存在无法有效捕获长距离特征的问题,只能通过堆叠更深的卷积层来解决长距离特征的问题,而self-attention通过并行计算可以解决这个问题,且不会遗忘。
传统的 RNN 和 CNN 模型需要使用滑动窗口或者批处理(batching)来处理数据,而Transformer模型则可以直接处理整个输入序列,这意味着它不需要额外的 padding 或者截断输入,可以更好地处理可变长度的输入序列,所以transformer中摒弃RNN和CNN会更好,减少了计算量并且提高了并行效率。
为什么CNN可以通过多层卷积叠加实现捕捉长距离特征,但对于文本特征的提取没transformer的表现好?
尽管CNN通过多层卷积叠加能够捕捉长距离特征,但是在处理长文本序列时,CNN存在一些缺点,使得transformer在处理自然语言处理任务中表现更好:
(1)局部区域对全局的贡献不同。由于CNN使用的是固定大小的卷积核,每个位置的信息只能通过卷积核内的局部区域来传递和叠加,因此局部区域对全局的贡献存在不同的权重。而Transformer使用的是全局的self-attention机制,每个位置与其他位置的关系可以根据其在所有位置上的表现来动态调整权重。
(2)CNN中信息随着深度被稀释。多层的卷积操作会使输入的信息在深度方向被不断稀释,从而会影响长距离依赖的捕捉和准确性。相比之下,Transformer的self-attention机制可以更好地捕捉长距离依赖关系。
(3)CNN中的下采样操作会降低分辨率。CNN通常会包括下采样操作(如max pooling),以降低表征的维度和加快计算速度。然而,这个下采样会降低序列的分辨率,因此在长序列的任务中表现不如Transformer。
综合以上几点,在NLP领域,由于长文本的特殊性质,transformer的全局self-attention机制将更加适合处理长文本序列,因此transformer表现更好。
decoder怎么实现这个更好的?
用大白话解释就是,在训练阶段,根据decoder每一次当前的输入(目标序列)和以前的输入,去encoder的输出(原序列的编码)中挑选自己感兴趣的资讯,并通过多层的Feed-Forward神经网络得到最终的生成序列。
数据工程是否做了encoder?
做了。从原序列提取特征,把每个token转化成对应的embedding。具体来说,文章中用了一个多层的encoder网络,用于将输入的序列语义信息编码为一组高维向量表示。这个encoder网络的每一层都包括一个self-attention机制和一个前馈神经网络。通过多次重复这个过程,从而有效地捕获输入序列的各种特征,并进行有效的语义编码。
直接用decoder会得到什么?
原始Transformer论文中并没有明确说明只使用Decoder部分可以得到什么结果,下面说的都是我的想法,请多包涵。
decoder部分的功能是:特征提取功能、语言模型功能、attention的翻译模型功能。
如果直接用decoder,在做翻译任务时,要对每个token进行编码,由于(MASK-注意力机制)得到的embedding没考虑全局的资讯,只考虑了前文的资讯,会导致整个机器学到的资讯不够多,从而得到的结果不够准确。
如果要只使用Decoder来完成原文中的翻译任务,那么输入序列要改成聚合表征(如bert的特殊标记符[CLS]最后一层的输出),优化的目标是最大化对给定的目标序列的生成概率,我的理解是Decoder部分一般用于生成任务,如文本生成、机器翻译等。
三、文献阅读
论文名:《BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding》
作者:Jacob Devlin Ming-Wei Chang Kenton Lee Kristina Toutanova
摘要
作者引入了一种新的语言表示模型,称为BERT,它是第一个使用双向Transformer编码器(bidirectional Transformer encoder)进行预训练的深度模型,与最近的语言表示模型不同,BERT的设计是通过联合调节所有层的左右上下文,从未标记的数据中预训练深的双向表示,通过它们来有效地捕捉和编码不同层面的语言信息。因此,预先训练过的BERT模型可以通过加上一个额外的输出层进行微调,就可以在广泛的任务中创建性能最先进的模型,如问题回答和语言推理,并且不需要对很多实质性的任务进行特定架构的修改。最近语言模型的迁移学习的经验改进表明,丰富的、无监督的预训练是许多语言理解系统的一个重要部分。特别是,这些结果使即使是低资源的任务也能从深层的单向架构中获益。作者的主要贡献是将这些发现进一步推广到深度双向架构,允许相同的预训练模型成功地处理一组广泛的NLP任务。
研究背景
语言模型预训练已被证明对改善许多自然语言处理任务是有效的,现有有两种策略可以将预先训练过的语言表达应用到下游任务中:基于特征的策略和微调策略。这两种方法在预训练期间具有相同的目标函数,它们使用单向语言模型来学习通用语言表达。作者认为,目前的技术限制了预训练表示的能力,特别是对于微调方法。主要的限制是标准语言模型是单向的,这限制了在预训练过程中可以使用的架构的选择。在本文中,作者改进了基于微调的方法,提出了BERT:通过使用“掩蔽语言模型(MLM)预训练目标,减轻了前文提到的单向性的约束,与“从左到右”的预训练的语言模型不同,MLM模型能够融合左右上下文进行表达,这允许作者能够预训练一个深的双向Transformer。
模型架构
BERT模型架构是双向Transformer的encoder部分的多重堆叠,BERT的具体实现框架中有两个步骤:预训练和微调。 在预训练期间,通过不同的预训练任务对未标记的数据进行模型训练。 为了进行微调,首先使用预训练的参数初始化BERT模型,然后使用下游任务中的标记数据对所有参数进行微调。
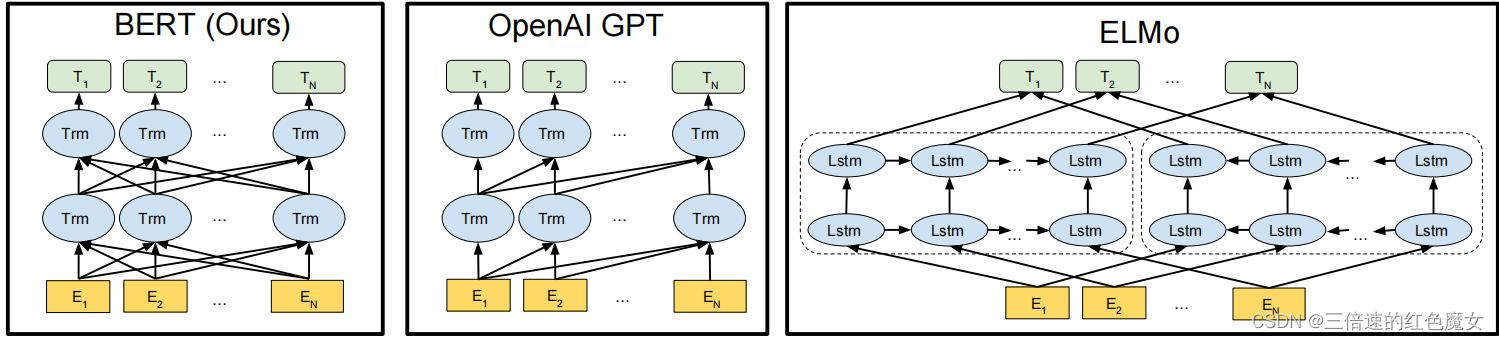
(这样看bert就像缝合了GPT和ELMo的思想)
输入/输出表征
输入表征能在一个词块序列中明确地表征单个文本句子或一对文本句子,在这项工作中,“句子”可以是连续文本的任意跨度,而不是实际的语言句子。“序列”指BERT的输入词块序列,可以是单个句子或两个句子打包在一起。对于给定词块,其输入表征通过对词本身的编码、句子编码和位置编码求和来构造,如下图所示: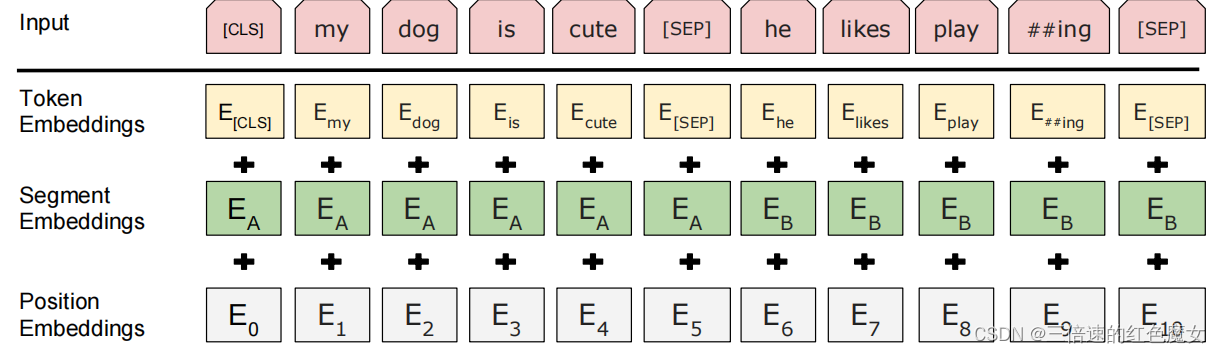
预训练任务1:掩蔽语言模型
为了训练深度双向表征,我们采用一种随机遮蔽输入词块的某些部分,然后仅预测那些被遮蔽词块的方法。该过程被称为“Masked LM”,在这种情况下,对应于遮蔽词块的最终隐藏向量被馈送到词汇表上的输出softmax函数中,如在标准LM中那样预测所有词汇的概率。在所有实验中,作者随机地遮蔽蔽每个序列中所有WordPiece词块的15%,只预测遮蔽单词而不是重建整个输入。
但该方法有两个缺点。
(1)**正在创建预训练和微调之间的不匹配。**因为在微调期间从未看到[MASK]词块。为了缓解这个问题,并非始终用[MASK]替换所选单词。相反,训练数据生成器随机选择15%的词块,然后完成以下过程:
80%的概率:用[MASK]词块替换单词,例如,我的狗是毛茸茸的!我的狗是[MASK]
10%的概率:用随机词替换遮蔽词,例如,我的狗是毛茸茸的!我的狗是苹果
10%的概率:保持单词不变,例如,我的狗是毛茸茸的!我的狗毛茸茸的。这样做的目的是将该表征偏向于实际观察到的单词.
这样的好处是,变换器编码器不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入词块的分布式语境表征,从而学到更多的特征信息。
(2)每批序列中只预测了15%的词块。这表明模型可能需要更多的预训练步骤才能收敛。
预训练任务2:Next Sentence Prediction (NSP)
为了训练一个理解句子关系的模型,我们预训练了一个二值化NSP任务,具体来说,该任务是选择句子A和B作为预训练样本进行如下判断:B有50%的可能是A的下一句,也有50%的可能是来自语料库的随机句子。面向该任务的预训练对QA和NLI都非常有益
Fine-tuning BERT
对于句子级的分类任务,为了获得输入序列的固定维度池化表征,BERT直接取第一个[CLS]token的最后一个隐含层状态作为聚合表征级记为向量C,加一层权重作为分类层向量W∈RKxH,其中K是分类器标签的数量。用softmax函数计算出标签根据P=softmax(CWT)。BERT的·所有参数都经过联动地微调,以最大化正确标签的对数概率。其他预测任务需要进行一些调整,必须以任务特定方式稍微修改上述过程,如下图所示:
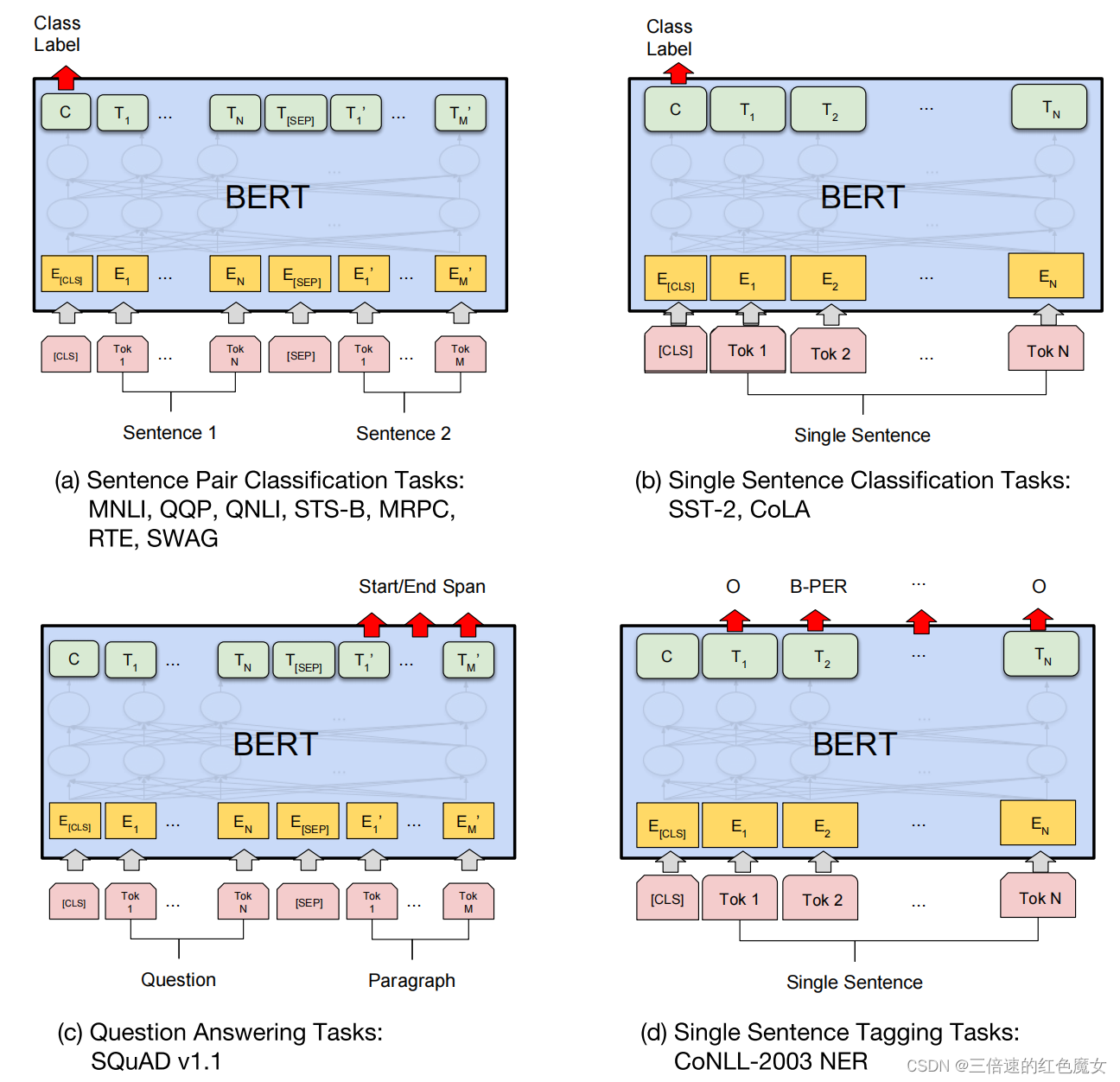
总结来说就是:
(a)句子对分类:把两个句子拼接起来,用CLS对应的最后一层输出,通过激活函数判断,如0—不相似,1—相似;
(b)单个句子分类:跟a差不多一样,都是用CLS的输出做分类;
(c)问答系统:将问题与包含答案相关文本打包作为输入,BERT 需要将相应的答案文本的范围高亮出来,每个词输出的embeddings 与起始词分类器权重点乘后,用softmax 对所有词生成概率。概率最高的词作为起始词,重复这个过程可得结束词。
(d)序列标注任务:把每一个Token输入,做一个softmax得到概率,就可以知道token属于哪一类标签。
实验
数据集
预训练数据集主要包括BooksCorpus和英文维基百科。其中,BooksCorpus包含11,038本图书中的文本,英文维基百科包含了2,500万文章,总计约3.3亿个Token。这些数据被用于BERT模型的预训练。
微调数据集包括GLUE、SQuAD v1.1和SQuAD v2.0。其中GLUE是一个由9个不同的任务组成的基准测试套件,用于评估模型在各种自然语言推理和下游任务上的性能,SQuAD v1.1和SQuAD v2.0是问答任务的数据集。
实验结果
结果如下表所示。在所有任务上都bert大大优于所有模型,比现有技术分别获得了4.5%和7.0%的平均精度提高。除了注意力掩盖外,BERTBASE和OpenAI GPT在模型架构方面几乎是相同的。对于最大和最广泛报道的GLUE任务,MNLI,BERT获得了4.6%的绝对精度提高。
作者还在论文中提到,预训练数据集的规模对BERT模型性能的影响很大。在实验中,他们使用了不同大小的数据集进行了比较,证明了BERT在大规模数据集上表现良好。
研究贡献
(1)证明了双向预训练对语言表征量的重要性。
(2)展示了预训练能消除许多重型工程任务特定架构的需求。
四、总结
本周虽然学习了bert模型的论文和一些细节,但对它在下游任务中的微调以及模型的训练了解的还不够深入,下周会手动训练bert模型以及它在下游任务中的具体操作,以及实现bert和transformer的代码。














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









