







梯度消失
在使用
s
i
g
m
o
i
d
sigmoid
sigmoid激活函数进行梯度下降调参时,往往会出现梯度消失的问题,即无法找到收敛点。
神经网络主要的训练方法是BP算法,BP算法的基础是导数的链式法则,也就是多个导数的乘积。而
s
i
g
m
o
i
d
sigmoid
sigmoid的导数最大为0.25,且大部分数值都被推向两侧饱和区域,这就导致大部分数值经过
s
i
g
m
o
i
d
sigmoid
sigmoid激活函数之后,其导数都非常小,多个小于等于0.25的数值相乘,其运算结果很小。随着神经网络层数的加深,梯度后向传播到浅层网络时,基本无法引起参数的扰动,也就是没有将loss的信息传递到浅层网络,这样网络就无法训练学习了。这就是所谓的梯度消失。


更新
w
k
+
1
=
w
k
−
η
g
k
w^{k+1}=w^k-\eta g^k
wk+1=wk−ηgk后经过神经元,数据会通过
s
i
g
m
o
i
d
\bm {sigmoid}
sigmoid函数衰减,因为
s
i
g
m
o
i
d
sigmoid
sigmoid函数会将比较大的值映射到(0,1)区间内。

靠近输入层的的参数,每通过一个隐层,数据就会衰减一次,数据变化越来越小,所以会造成在输入层附近的梯度较小。
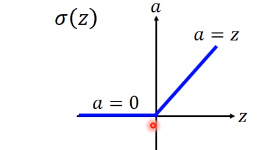
ReLu激活函数(Recifited Linear Unit)
可以使用另一种激活函数ReLU函数来改变上面的情况。
σ
(
z
)
=
{
0
,
if
z
<
0
z
,
otherwise
\sigma(z)=\left\{\begin{array}{ll}{0,} & {\text { if } z<0} \\ {z,} & {\text { otherwise }}\end{array}\right.
σ(z)={0,z, if z<0 otherwise
图像如下:
一些变化形式

Maxout
让神经网络自己学习得到激活函数的方法称为Maxout
事先决定那几个神经元分为一组,然后选择组内最大的神经元。

然后利用选择的最大的神经元继续重复上面的操作。

举例:
假设某神经元参数是
w
,
b
;
z
=
w
x
+
b
,
a
是
R
e
L
U
激
活
函
数
w,b;z=wx+b,a是ReLU激活函数
w,b;z=wx+b,a是ReLU激活函数,
a
=
σ
(
z
)
=
{
0
,
if
z
<
0
z
,
otherwise
a=\sigma(z)=\left\{\begin{array}{ll}{0,} & {\text { if } z<0} \\ {z,} & {\text { otherwise }}\end{array}\right.
a=σ(z)={0,z, if z<0 otherwise

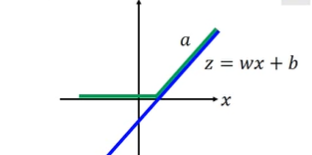
则输出结果可以对应下图中绿色的线:
假设输出层有两个神经元,则选取其中函数
z
1
.
z
2
z_1.z_2
z1.z2中函数值最大的传给激活函数。
注:此时应注意比较不同取值范围内函数值的大小。
举例:如图,假设第二层中
z
2
z_2
z2的参数为
0
,
0
0,0
0,0,则
z
2
=
0
(
在
任
意
区
间
内
)
,
z_2=0(在任意区间内),
z2=0(在任意区间内),在(
−
∞
,
b
-\infty,b
−∞,b)的范围内
z
1
<
z
2
z_1<z_2
z1<z2,所以此时取
z
2
z_2
z2,在(
b
,
∞
b,\infty
b,∞)上取
z
1
z_1
z1。
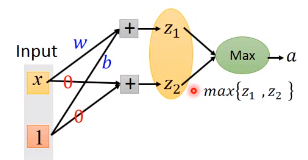

一般情况:

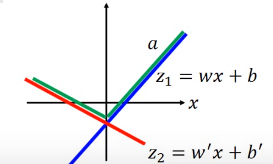
绿线表示根据数据自学习的激活函数。(因为参数
w
,
b
w,b
w,b是自己训练得到的,所以这个神经网络可以自己的数据决定激活函数。).
假设分组一组有两个神经元,图像形式可以如下:

如果是三个神经元一组:

Maxout-Training
训练:由于根据上面可以看出,我们的激活函数是分段函数,可能不具有微分值。那么应该怎么做呢。(即使没有办法微分,可以找到参数的变化对Loss函数的变化,也可以使用梯度下降。)
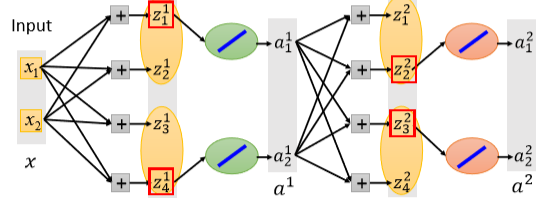
假设一个神经网络,下图中红框内表示两个中的最大值。

我们可以将较小值的神经元隐去(如下图),进行训练,这样就是一个线性函数了,那么去掉的神经元是不是就没有意义呢?不是的,因为这只是一个数据的结果,在训练集中有不同的数据,总会有数据使得这个神经元比另外的一个大,就可以训练该神经元上的参数了。














 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









