







论文相关
论文标题:Label prompt for multi-label text classification(基于预训练模型对少样本进行文本分类)
发表时间:2021
领域:多标签文本分类
发表期刊:ICANN(顶级会议)
相关代码:无
数据集:无
摘要
最近,预先训练过的语言模型在许多基准测试上都取得了非凡的性能。通过从一个大型的训练前语料库中学习一般的语言知识,该语言模型可以在微调阶段以相对少量的标记训练数据来适应特定的下游任务。更值得注意的是,带有175 B参数的GPT-3通过利用自然语言提示和很少的任务演示,在特定的任务中表现良好。受GPT-3成功的启发,我们想知道更小的语言模型是否仍然具有类似的少样本学习能力。不像在之前的少样本学习研究工作中,各种精心设计的任务,我们做得更实际。我们提出了一种基于问答问题的方法,通过将一个与标签相关的问题连接到每个候选句子中,来帮助语言模型更好地理解文本分类任务。通过利用语言模型在预训练阶段学习到的与标签相关的语言知识,我们的QA模型在英语和中文数据集上都优于传统的二进制和多类分类方法。之后,我们通过对多个预先训练过的语言模型进行少样本学习实验来测试我们的QA模型。我们惊讶地发现,即使是DistilBERT,这是我们测试的只有66 M参数的最小语言模型,仍然具有不可否认的少样本学习能力。此外,具有355 M参数的RoBERTa-large在只有100个标记训练数据的情况下,可以显著实现92.18%的高准确率。这个结果给人们提供了一个实用的指导方针,即当需要一个新的标记数据类别时,只需要标记多达100个数据。然后配合适当的预训练模型和分类算法,可以得到可靠的分类结果。即使没有任何标记的训练数据,即在零样本学习设置下,RoBERTa-large仍能达到84.84%的稳定准确率。
1.引言
随着深度学习的发展,各种预训练的语言模型(PLMs)已被广泛用于解决自然语言处理任务。第一代的PLMs,如Skip-Gram和GloVe,旨在学习无法捕获更高层次语义概念的与上下文无关的词嵌入。第二代plm,如ELMo、BERT和GPT,在上下文中表示单词。通过以自我监督的方式在一个大型语料库上进行预训练,plm只需要对特定下游任务的少量标记数据进行微调。从那时起,训练前和微调范式开始主导NLP。在Brown等人引入的4000亿个代币上训练了1750亿个参数。在2020年,将plm推到了新一个水平。当只提供一个描述和很少的任务例子时,GPT-3模型可以不需要梯度更新而做出准确的预测或微调。尽管已经获得了显著的少样本学习能力,但同样突出的是,GPT-3背后的大量参数使将其应用于现实应用具有挑战性。
作为一个机器学习问题,少样本学习比PLM有更长的历史。人类能够通过利用他们在过去学到的东西来快速学习新的任务。因此,研究人员认为,设计一种高效的少样本学习算法可以让机器达到与人类相同的智力水平。然而,受GPT-3的启发,我们认为少量学习是预先训练的语言模型本身的一种能力,而不是被视为一项任务。毫无疑问,具有少镜头学习能力的语言模型应该有较大的参数,并在较大的语料库上进行预训练。然而,有多大才足够呢?因此,在本研究中,我们通过文本分类实验来探索各种语言模型的少样本学习能力。我们测试的预先训练的语言模型包括DistilBERT 、BERT 和RoBERTa-large ,它们分别有66M、110M和355M的参数。扩展一个常规大小的自动编码器语言模型在文本分类中的少样本学习能力是很有吸引力的:
- 文本分类是一个模型能够轻松掌握的下游任务;
- 一些带有标记的样品很容易获取;
- 这种模型可以在一般硬件上进行微调。
因此,我们提出了一种可行的场景来制作更好的少样本文本分类器,并研究了语言模型尺度对其少镜头学习能力的影响。具体来说,本文的主要贡献如下: - 我们提出了一种基于问答的分类方法,该方法在英语和中文数据集上都优于传统的二进制和多类分类方法。
- 我们在多个不同大小的预训练语言模型上进行了一系列的少镜头学习实验,范围从蒸馏室到RoBERTa-大。结果表明,所有这些模型都表现出不同水平的少镜头学习能力。有些人甚至实现了零样本学习。
- 本文使用不同训练样本的每个模型的详细准确率。这些结果可以作为人们在实践中标记样本的指导方针。
- 我们还对预先训练过的语言模型的注意机制进行了深入的说明和讨论。通过它,我们试图揭示少样本学习能力的奥秘。
2. 相关工作
2.1 语言模型(LM)
语言模型的演化可分为统计语言模型、神经语言模型和预训练语言模型三个阶段。统计语言模型从20世纪60年代到20世纪10年代占主导地位,如隐马尔可夫模型和条件随机场。自2010年以来,深度学习模型的出现在文本分类方面取得了显著进展。神经模型,如CNN 和LSTM ,只是数据驱动的,避免做特征工程。然而,他们不能处理少样本学习。

图1。近年来的语言模型(GPT系列为紫色;BERT系列为蓝色;transformer是BERT和GPT的基础,为绿色)。
随着transformer的发展,近年来语言模型出现了预训练(图1)。值得注意的是,类似gpt的自动回归语言模型在精心选择的提示下表现得非常好,而且在许多下游任务中只有几个例子。由于被这些少样本学习能力所吸引,研究人员开始探索类似bert的自动编码器语言模型,并发现它也具有少样本学习能力。
2.2 传统的少样本学习
多年来,深度学习在与数据绑定的行业中取得了巨大的成功,但当数据量很少时,它往往是不可行的。因此,在数据不足的情况下训练一个表现良好的模型自然被视为一项具有挑战性的任务。提出了多种处理少样本学习任务的方法,包括利用可访问数据生成更多样本的数据论证,计算特征之间相似性的孪生神经网络,以及学习多个数据集学习几个例子的元学习。这些方法似乎是“机械地”使用这些知识的方法。然而,受GPT系列研究的启发,我们认为少样本应该被认为是语言模型的固有属性。
2.3 基于预训练语言模型的少样本学习
使用提示来让语言模型做出更好的推断似乎更加“人性化”,在大型语料库上的预训练赋予了语言模型较强的语言技能,因此只需要在特定下游任务的少量标记数据中进行微调。自回归语言模型,如GPTs和CPM ,可以通过生成后续文本来进行预测,并提供上下文中任务的字面定义,称为提示。在最近的工作中,他们使用一个精细的构造模板来使语言模型完成完成任务,这有助于语言模型理解特定的任务。这似乎是有效的,但模板的局限性使上述方法不能适应任何任务。然而,偏离这些研究,我们关注语言模型本身的少样本学习能力,并提出了一种任务不可知的方法,称为QA分类。
3. 方法
3.1 文本分类
在本文中,我们通过文本分类进行实验(见图2),因为文本分类是语言模型易于学习的下游任务。因此,做文本分类可以使语言模型更容易显示出少样本的学习能力。
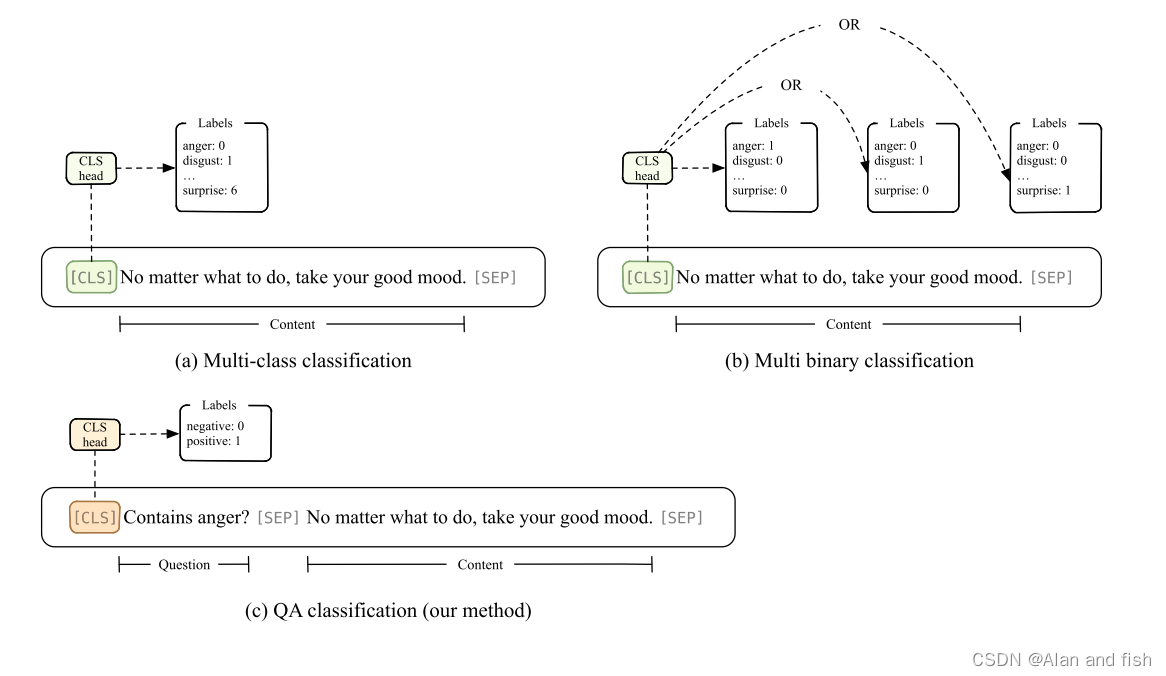
图2 我们使用了(a)多类分类、(b)多元分类、©将多类分类转化为问题回答的方法。
然后,我们采用做问题和回答的想法,可以帮助语言模型更好地利用知识,因为我们给模型提供了更多的信息。因此,我们将多类文本分类转换为问答(QA),这为语言模型提供了先验信息,并将任务转化为一个简单的二元分类。
我们用标签空间Y来微调数据集D上的一个BERT M。M接受一个序列 x i n x_{in} xin的输入,并输出该序列的表示。第一个输出总是[CLS],我们把它作为整个序列的表示,并微调M以最小化交叉熵。我们以M‘作为具有全连接层的M的表示,M的输出为P,它由类和 dim § = |Y|对应的概率组成。
二分类 在二值分类中,我们仅仅在M的预测标签概率 y p r e d i c t y_{predict} ypredict的下面添加了一个带有sigmoid激活函数的全连接层。
p ( y ∣ x i n ) = 1 1 + e x p ( − W ⋅ h [ C L S ] ) . . . . . . . . . . . . . . . . . . . . . . . . ( 1 ) p(y|x_{in})=\frac{1}{1+exp(-W·h_{[CLS]})}........................(1) p(y∣xin)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









