






最近的学习大多都是和mysql的索引相关的
1.mvcc
mvcc是不需要手动配置,是mysql的一个机制
在事务开启时,对涉及到的数据加一个隐藏列,隐藏列对应的值,就是事务id
如果当前是修改操作,就copy一份原来的数据到新的一行,然后这一行有个隐藏列是事务id 方便回滚
如果是删除 就不用copy了
2.openfeign也可以通过url方式调用
也能起到负载均衡
但是如果通过指定url的方式,还能否实现负载均衡,我发现有不同说法,个人更倾向于不能实现负载均衡
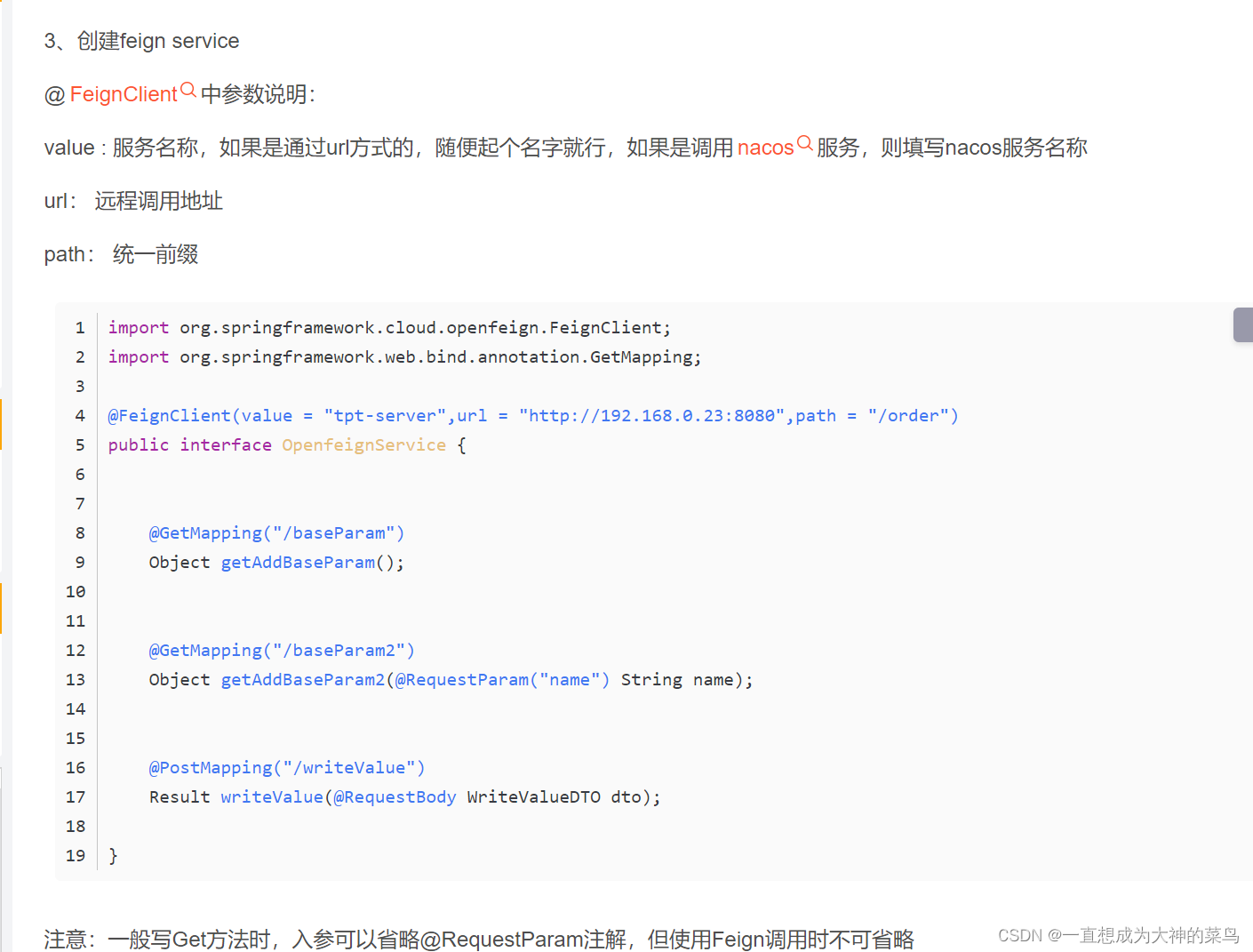
还可以把url放在yml配置文件中,这样取值
url = "http://${a.url}"3.踩坑:Mybatis-Plus子类起名注意
使用Mybatis-Plus如果继承了BaseMapper后,注意子类接口方法名不能和BaseMapper中的重复
这个bug我差了半天,我调用了mybatis-plus的java8相关方法delete,但是打印的sql跟我想要的完全无关
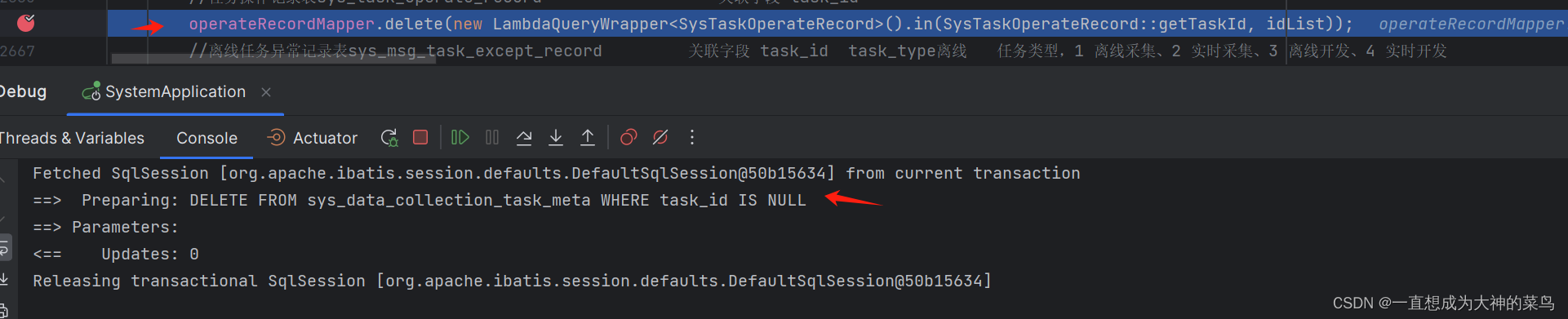
然后点到BaseMapper这个父类,我发现delete方法被重载了,然后这个控制台打印的就是重载的方法,改个名就好了
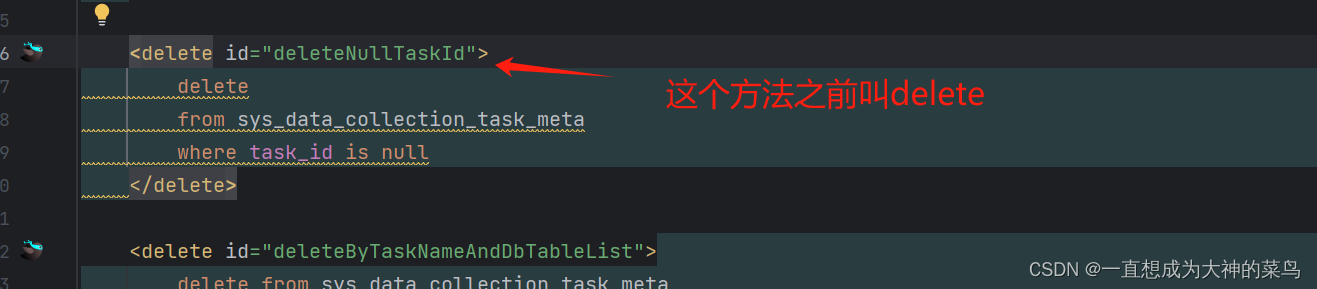
查了一下,他不支持重载,他认为是重写。子类要是重载,他就直接执行子类的方法了。

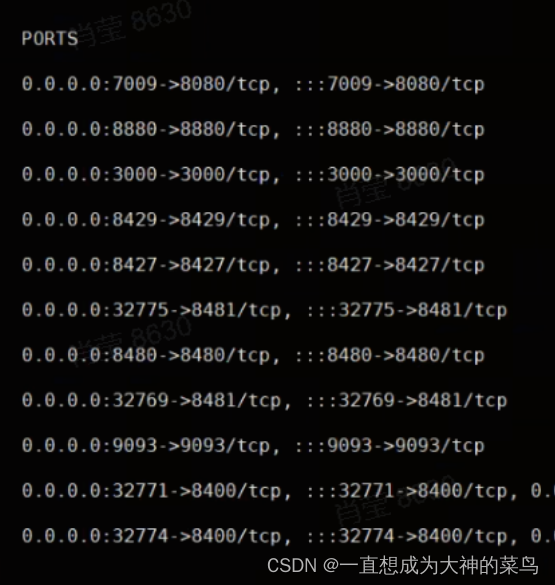
4.linux怎么看容器端口和宿主机端口
docker ps -a命令中的ports谁是内部端口,docker容器内部端口,谁是宿主机的端口
后边的是docker的,前边的是当前服务器开放出来,我们可以访问的端口

5.\G干嘛的
linux命令执行mysql相关指令的时候总在结尾加一个\G,没啥别的意思,就是为了让结果集展示的好看一点,换行展示,也相当于一个分号
6.隔离级别和对应的问题
mysql默认隔离级别是可重复读,并且认为可重复读不会产生幻读
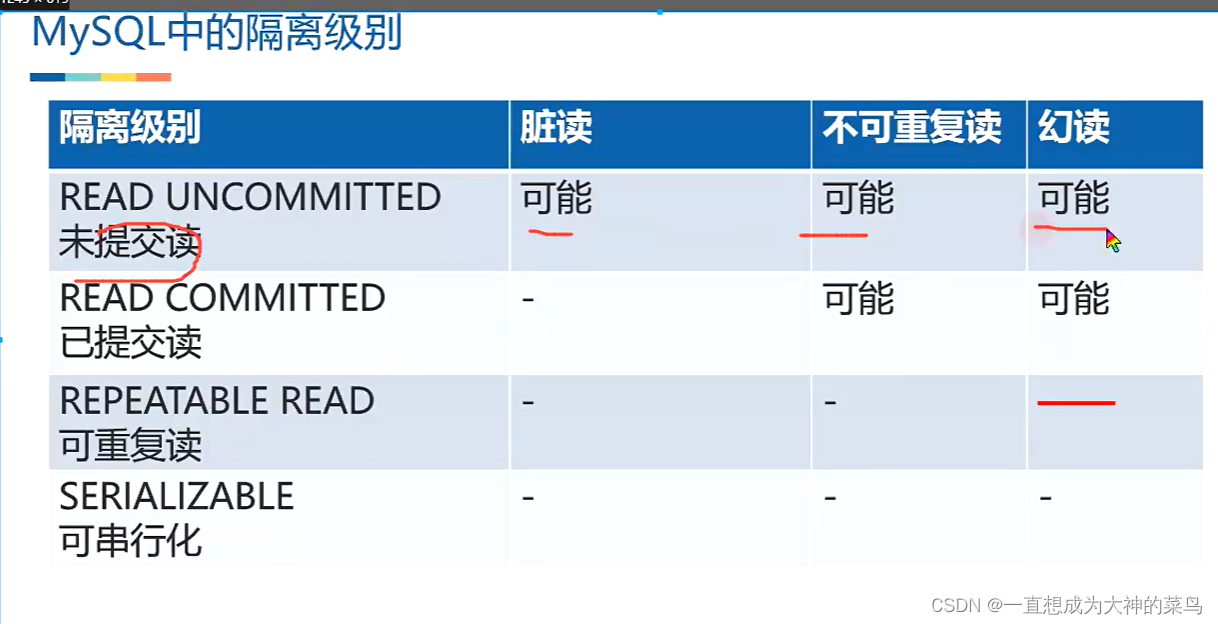
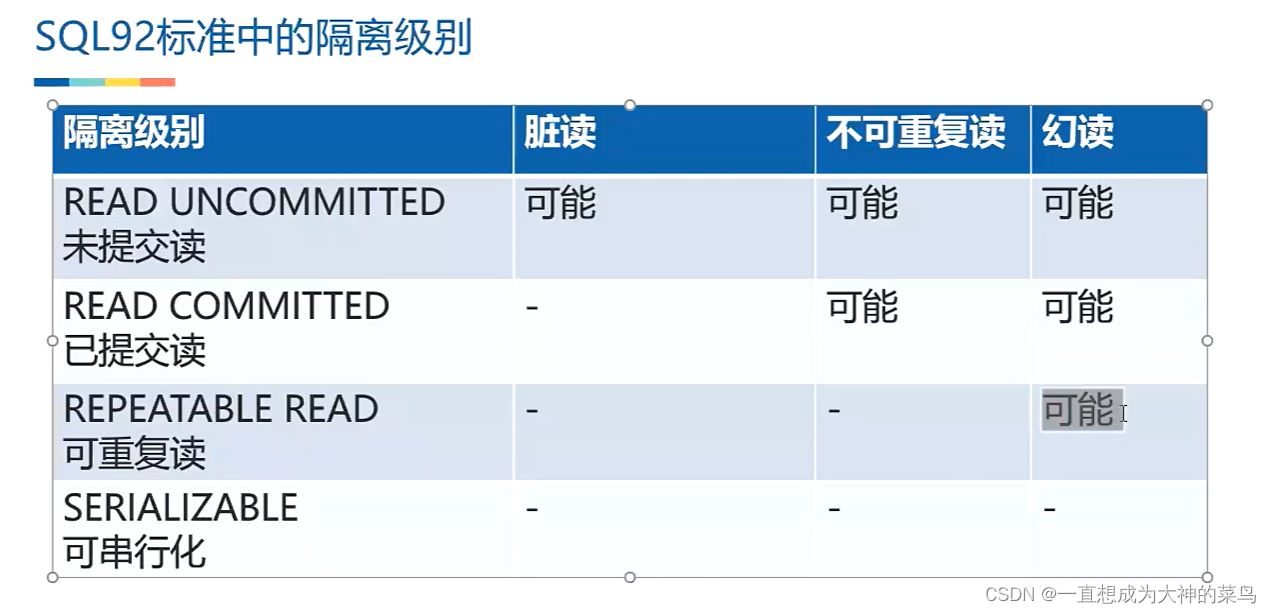
7.save point到底干嘛的
与事务回滚相关,save point在一个事务内定义保存点,然后rollback可以指定回滚的时候回滚到哪个保存点,如果不指定,就是整个事务都回滚

8.隐式提交
这个知识点个人认为不太重要,因为spring如果开启一个新事务,新事务提交或者不提交是不影响原来的事务的
mysql的隐式提交:在commit之前有ddl语句,或者再写个begin 那ddl和begin之前的都会被commit
已经提交了 就无法回滚
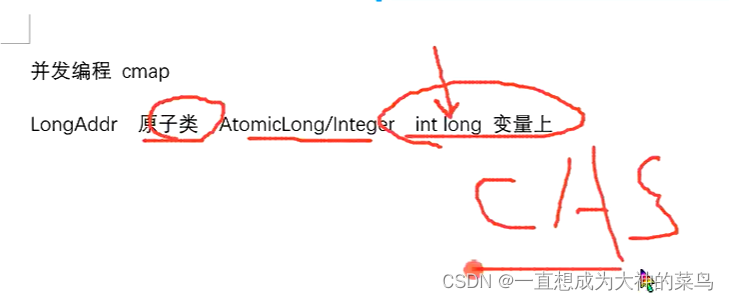
9.Atomic无锁编程
自旋
10.数据库字段定义:越小越好
字段优化:越小越快,
比如能用int不用long,long就是bigint
再比如能用char就不用varchar
能用varchar(10)就不选varchar(200),因为mysql会根据长度进行内存分配

11.数据库中boolean型字段值与返回给前端的字段值
突然好奇想到的,因为之前做的时候,会定义一个枚举,数据库中存字符串YES和NO
所以返回给前端的字段和存在数据库里的字段值相同,不做转换
但是也有人说如图这种
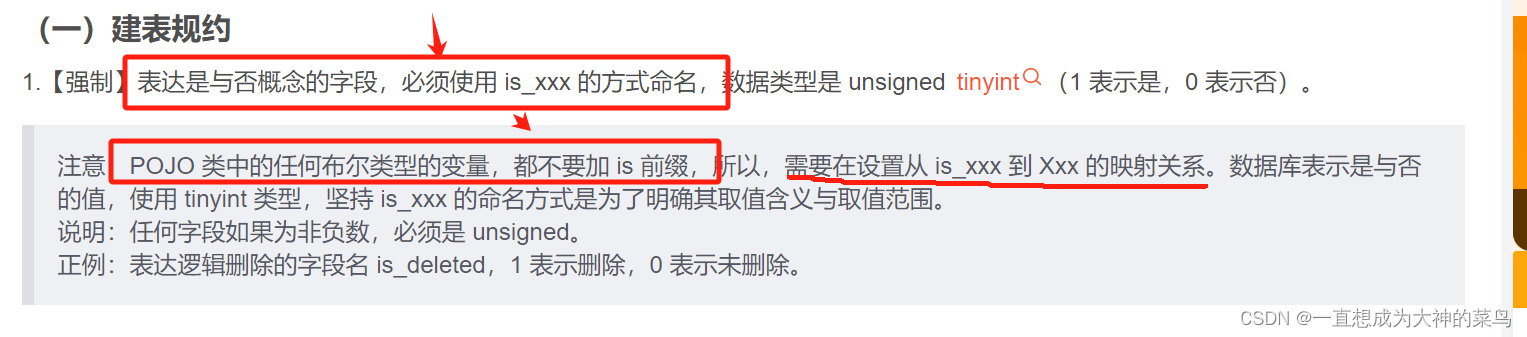
在mysql中定义boolean型,虽然下拉选中有boolean的选项,
但是保存会被保存为tinyint,true是1false是0
然后用mybatis自动生成对应实体时候,建的这个boolean型在实体中也是Integer类型,如果想用截图要求的,需要手动修改
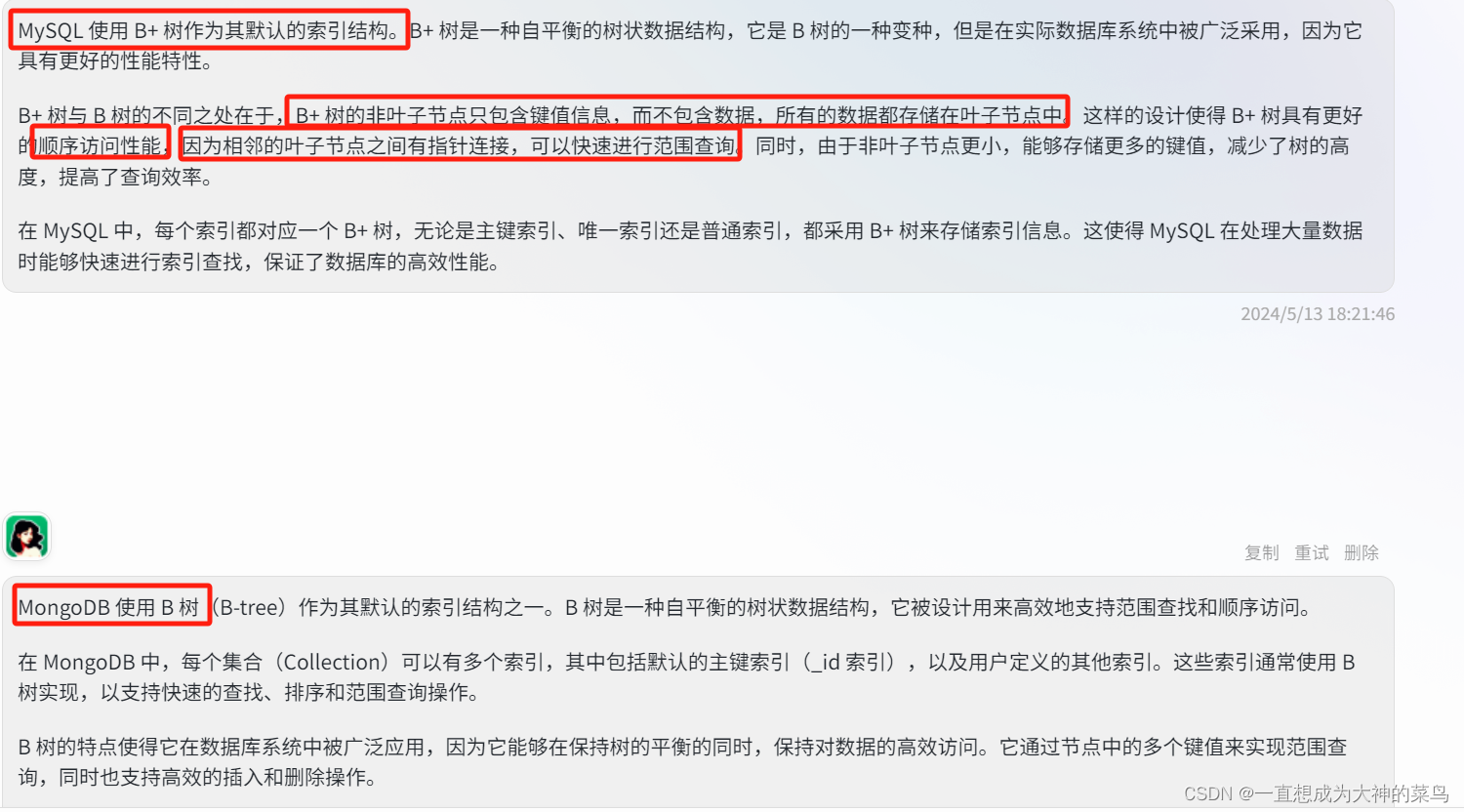
12.为什么mongo用B树,mysql用B+树
B+树只有叶子节点存储数据,并且数据之间有序,且组成一个链表
B树是每个节点都会存储数据,不管是叶子节点还是非叶子节点
至于选择哪个做底层索引,跟他们自己的业务选型有关,
mongo是非关系型数据库,每条数据之间相关性不大,一般一次也就取一条数据。
所以mongo用B树是为了取单条数据是查询比较快
mysql是关系型数据库,经常需要使用到范围查找,分页查询
所以mysql使用B+树是为了范围取值
b树的每个节点都要存数据,那每个节点可以容纳的子节点路数就会比b+树小
13.二分查找
为什么说着索引突然又说到二分查找?
你建立索引,是为了你加快查询速度吧?
那索引又会使用到一种数据结构,B树或者B+树,那这两种数据结构,又是由二叉树衍生过来的。
二叉树又和二分查找相关
平衡二叉树,左右高度差不超过1
B树,其实有点像多个子节点的二叉树,二叉树每个父节点最多两个子节点,但是B树可以多个
二分查找:有序数组,用下标除以二的方式,判断目标数字所在范围
如果奇数的时候,除以二之后可以选择前边那个也可以选择后边那个,这没事没啥影响

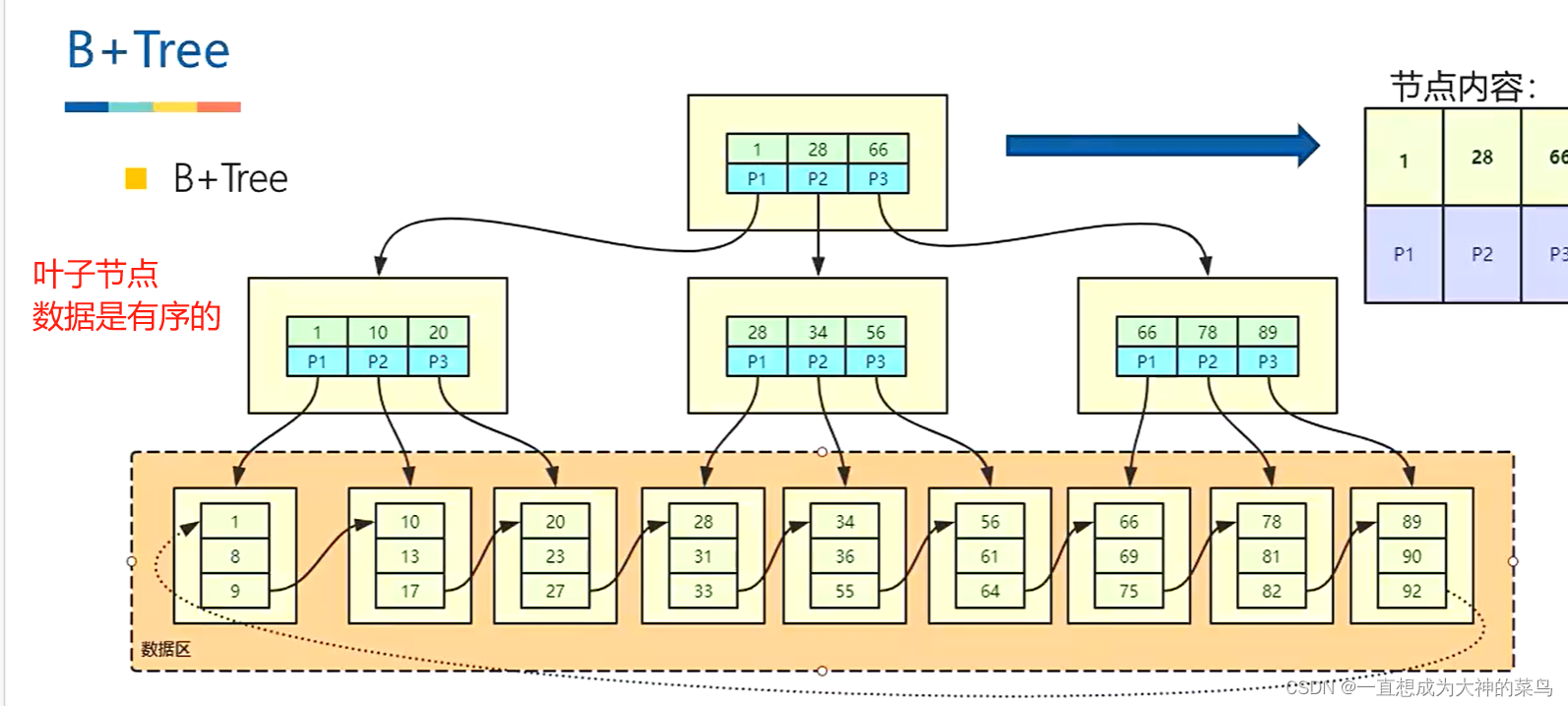
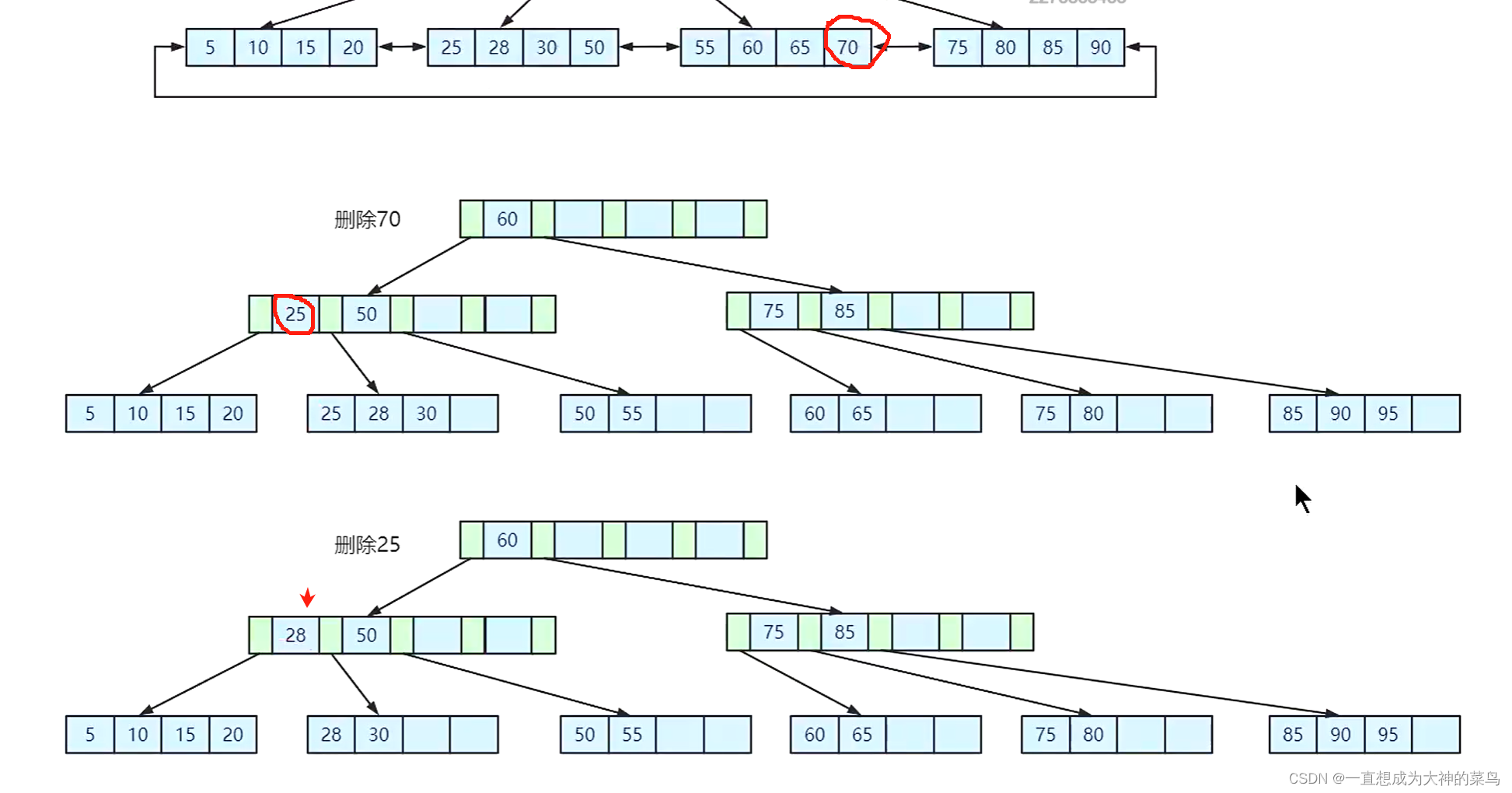
14.B+树的数据结构,以及页合并以及分裂
看完这个就知道为什么要合理的建索引,而不是把每个字段都作为索引

如图叶子节点又组成了一个链表
索引对应的数据增加的时候 ,可能发生的变化,比如页分裂
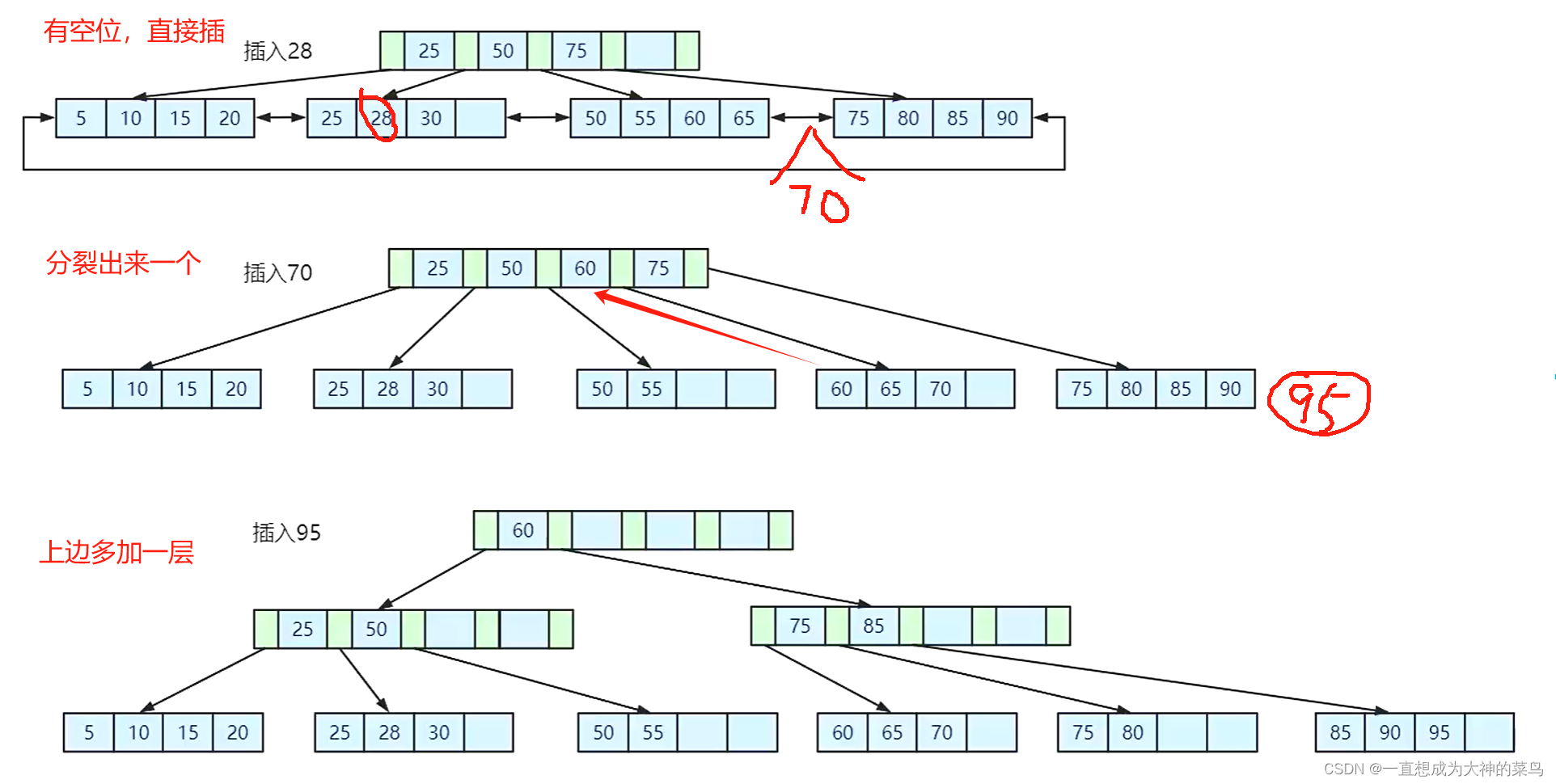
索引对应数据删除,可能发生的变化,比如页合并
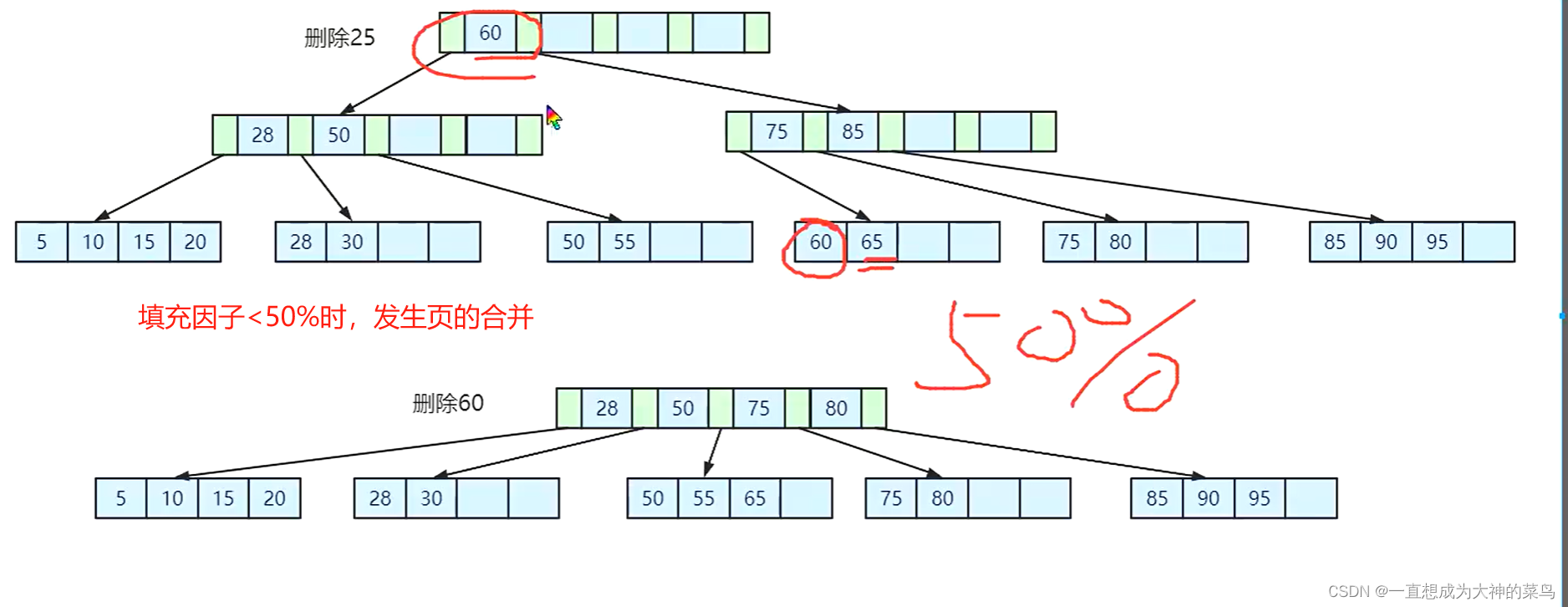
一个索引就是一棵B+树 (mysql中)
以上,其实索引在数据增加删除的时候是有维护成本的,毕竟使用索引是为了提升系统的运行速度,如果把每个字段都作为索引,维护成本就大大提醒,违背了建立索引的初衷
15.blob和text谨慎使用
blob和text谨慎使用,原因是如果用select * from 然后那这个表里如果有blob和text字段也会返回,那耗费带宽也浪费内存
16.为什么索引会自行排序
这和磁盘读取有关

所以数据分布最好有序
而且磁盘读取数据,如果你得文件比较小,他不止会读你一个文件 他是一个扇形区域 至少也要把这块扇形区域的都读出来
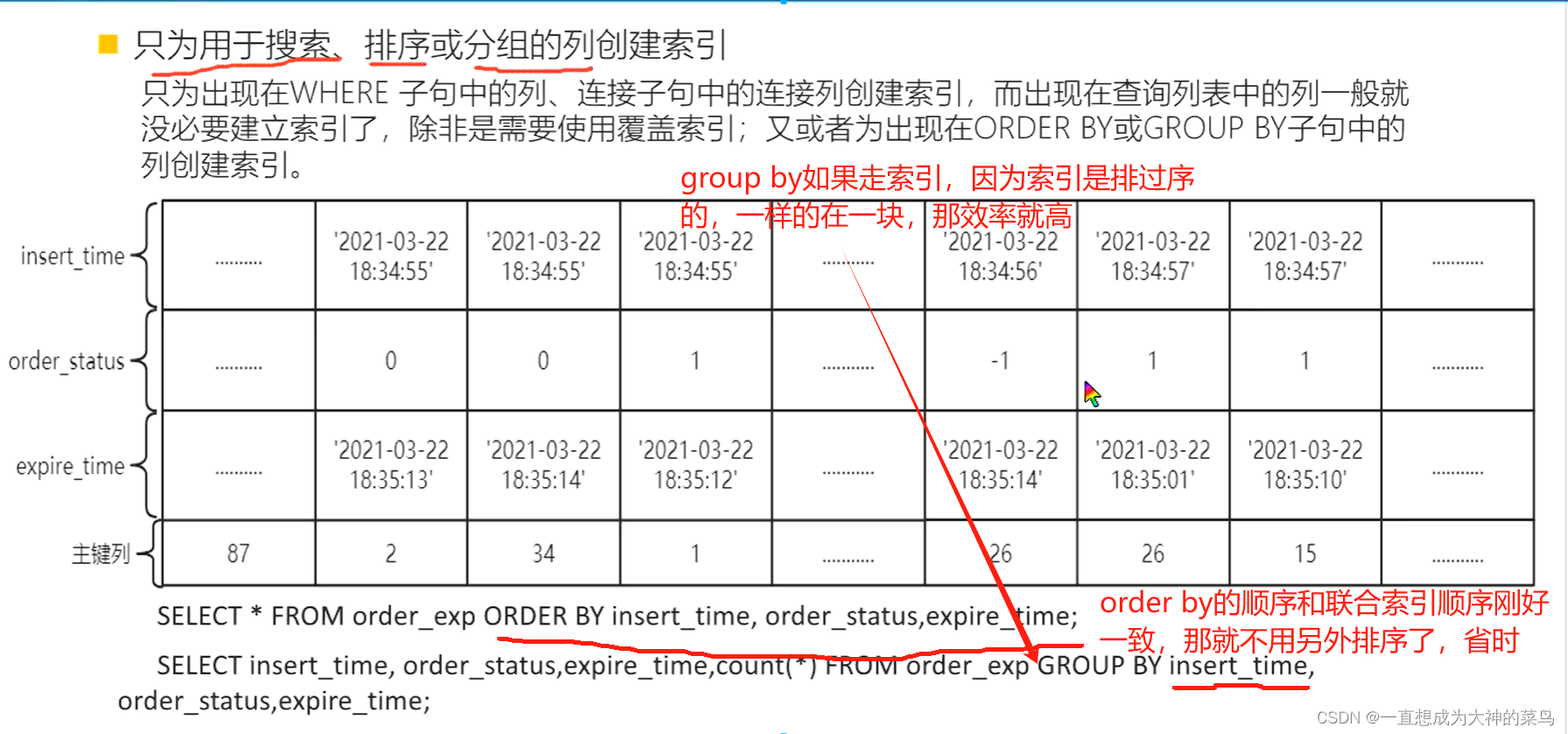
17.联合索引
看了如图就可以知道,为啥使用联合索引的查询的时候,一定要按照口诀
带头大哥不能死,中间兄弟不能断
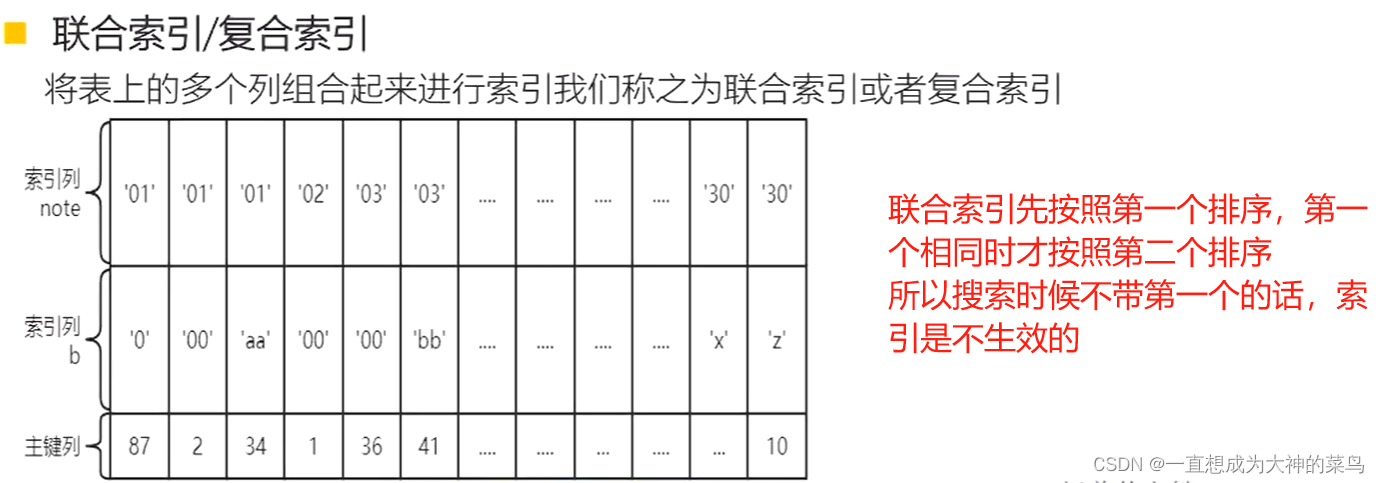
因为索引肯定是有序的,他会先按照第一个列排序,第一个列相同的时候,才按照第二个列排序,以此类推,第二个列相同的时候,才会按照第三列排序
如果我搜索的时候直接只用第三个列去搜索,那大概率是无序的,查询速率大大降低
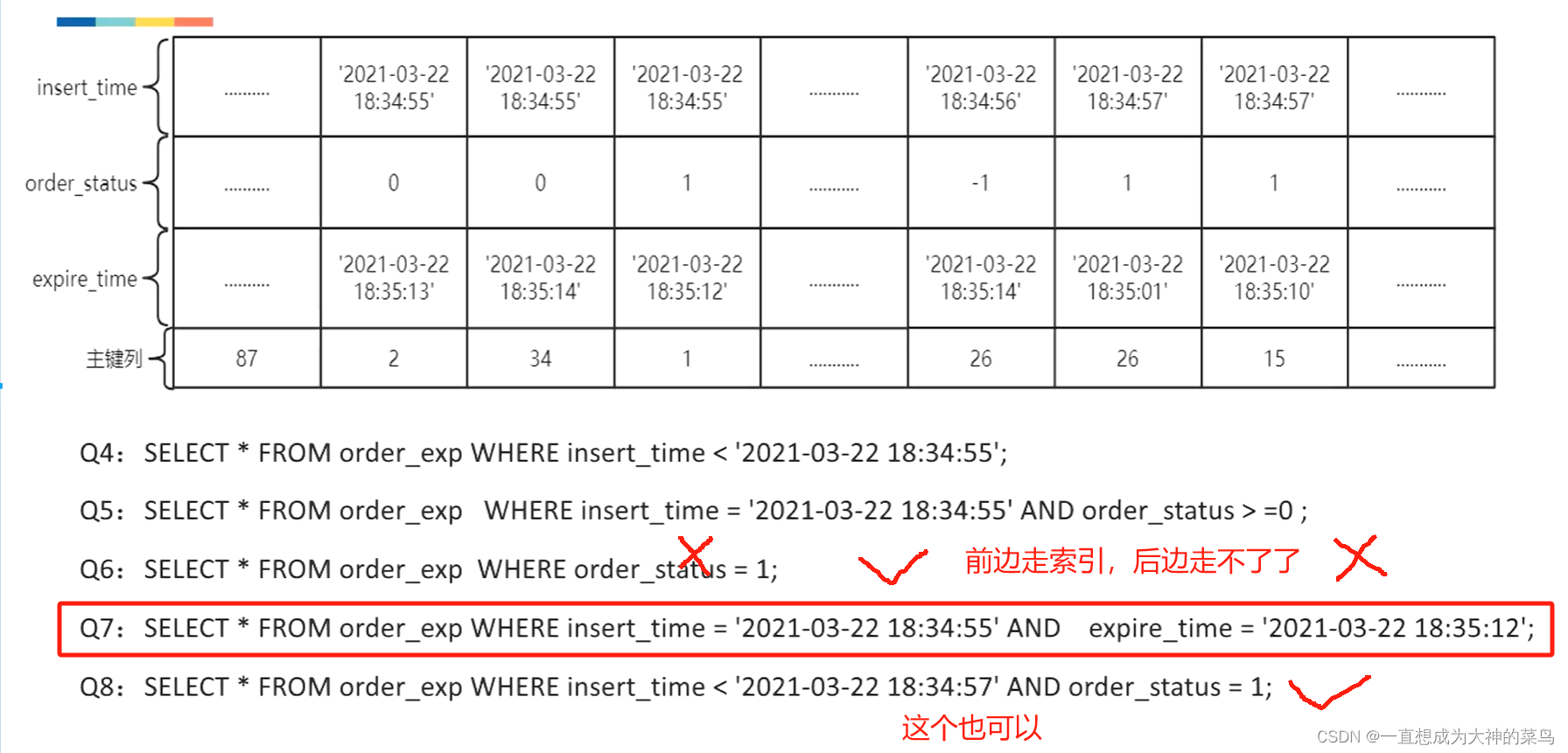
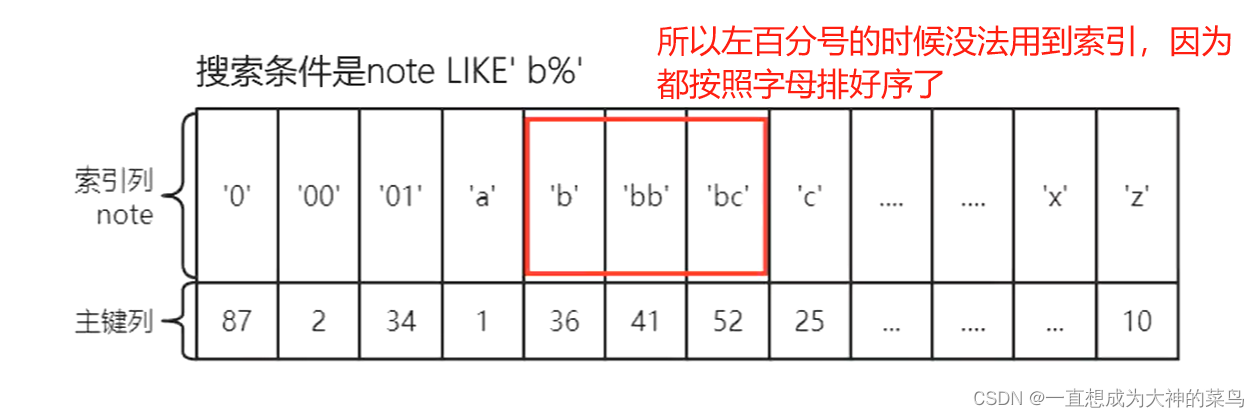
比如Index(a,b,c) 然后我用
select * from table where a=1 b like'%ss' and c=2结论是只有A用到了索引
那联合索引中a是用到的,b因为左百分号不知道以什么开头,就不确定它在哪个位置,用不到
然后c是在b拍好序的前提下才去排序的,现在b都不确定位置,c就更走不了索引了
那如果我改成
select * from table where a=1 b like'ss%' and c=2结论是A,B,C都用到了索引
区别就是b字段换成右百分号了,那这样b就知道以什么开头了,就能按照一定顺序把b的范围找到,这时候b走索引,c也能走索引
当然你如果更改一下顺序,写成
select * from table where c=2 and b like'ss%' and a=1 效果是一样的,mysql的sql优化器会自动调整顺序
18.一个select中只会用到一个二级索引
这是一个颠覆以前认知的事,就算where中使用了多个二级索引,那最后mysql也只会选择一个,其他的条件再回表之后在结果集中作为筛选条件,而不会走他们的索引树
比如我建立了三个索引,分别是索引A索引B索引C
不是联合索引奥,都是单个的
然后我查询的时候
select * from table where a=1 and b=1 and c=1那这时候同样会发生回表,不会索引覆盖
为什么呢?
因为mysql最终只会选择一颗B+树

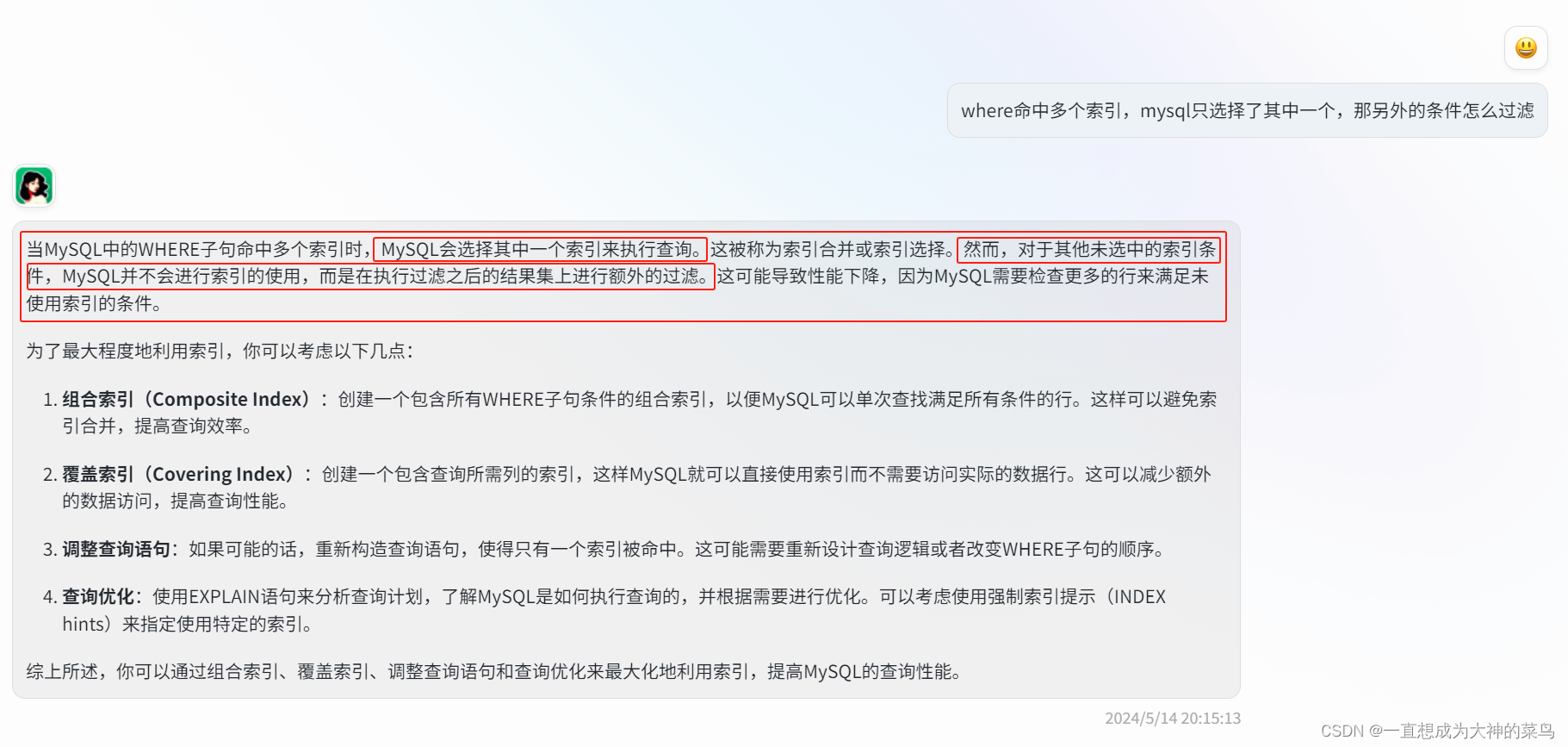
在一棵索引树上找到where条件中这个索引下指定范围的数据,然后回表去主键索引查询所有列,把这个作为结果集,再通过其他的where条件对这个结果集进行筛选
比如 select * from table_A where a<3 and b>2;
a和b都是非聚集索引那通过Mysql的查询优化器筛选出来哪个索引更快,它就去那个索引树上找
比如选择了a
那找到a<3那部分数据之后
就拿着这些数据的id去主键索引树,回表查询拿到结果集,再用b>2对这个结果集进行筛选,但是b的那棵索引树他是不走的
19.建立了索引但是依然全表扫面的情况
比如我分别建立索引expire_time和索引order_note
如果我用and去查询,那mysql至少会选择一棵索引树,然后回表去筛选另一个条件
但是如果我用OR去查询,那Mysql就没办法选择索引树,直接全表扫描
为什么?
因为OR取并集,只筛选一棵的话,没办法确定另一棵的范围

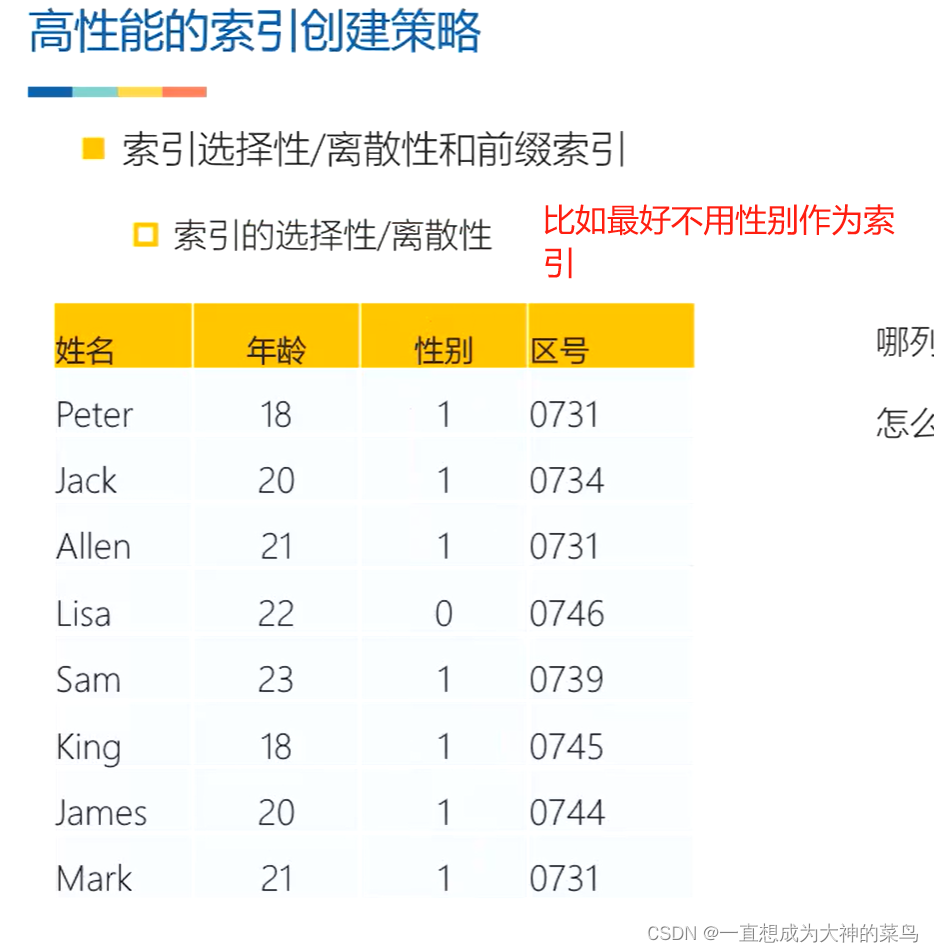
20.选择什么样的字段作为索引
选择离散型高的,比如性别和名字这两个字段,那就选择名字作为索引,而不是选择性别
因为索引是要排序的,排好序之后,定位快,搜索快
如果选择性别,一共就俩,排不排序,没啥意义

21.前缀索引


22.什么情况下要创建索引
1.表连接

2.group by,order by
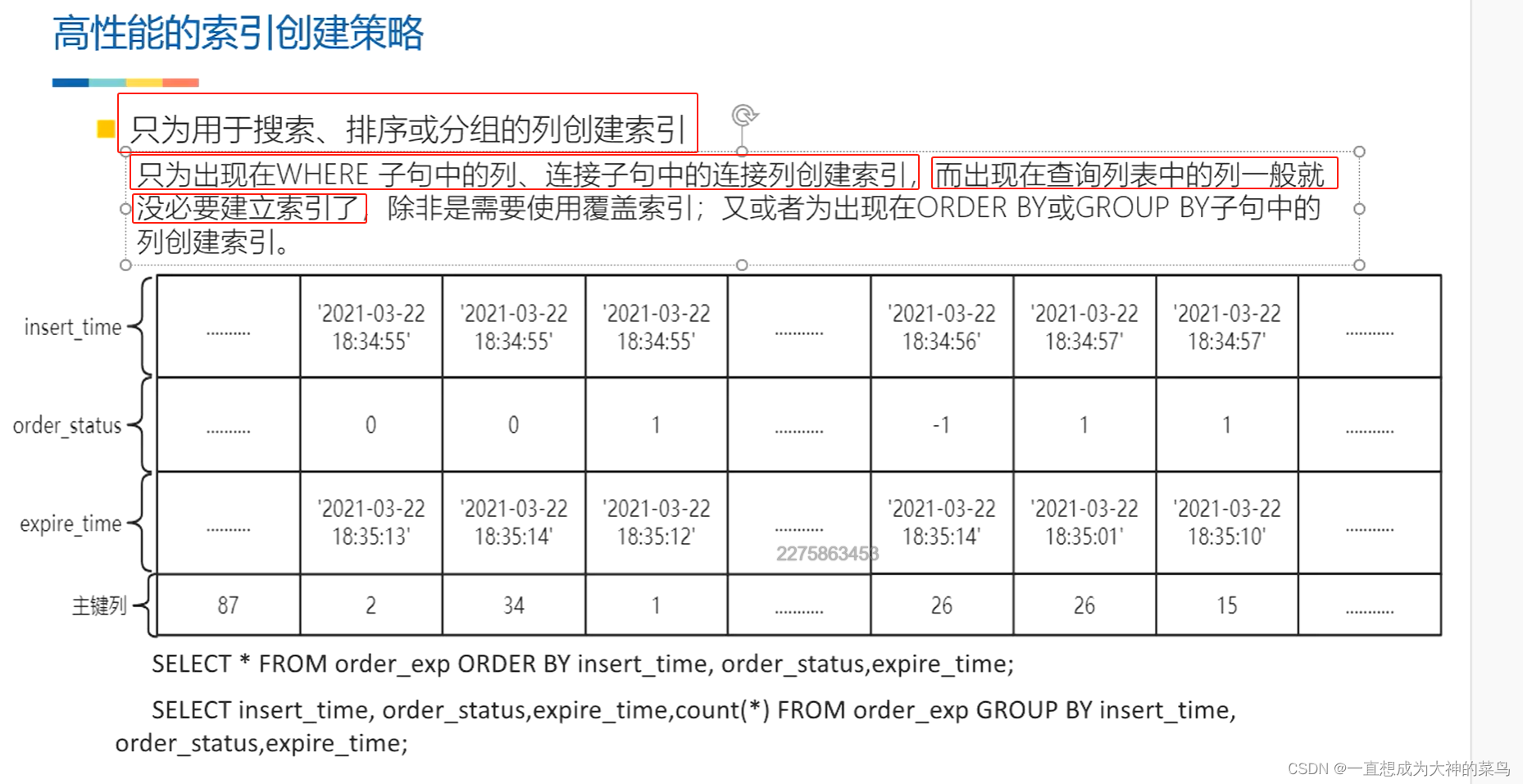
多列索引,就是联合索引

索引覆盖,不用回表
23.设计表结构时,尽量不为NULL
mysql认为每个null都是独一无二的 所以如果索引字段,存入的值有null,那么每个null值都会占用索引树的一部分空间
当查询where 字段 is null时,会得到一个范围 而不是像where 字段=1 这种只获得一条数据
可以默认0或者空字符串

24. 查询优化
我们经常说减少与数据库的交互,但是真到需要优化的时候,如果之前的sql又臭又长,执行很慢,然后把他拆分了反倒快了,那就哪个快用哪个,东西是死的人是活的。多交互也没办法


这个也是可以酌情增加与数据库交互次数
本来关联5个表,然后查询很慢,那我分解为俩sql,一个是关联3个,一个是关联两个
在代码层面再去处理
反正哪个快用哪个

这些优化没有非黑即白得,就是看怎么快就怎么调整
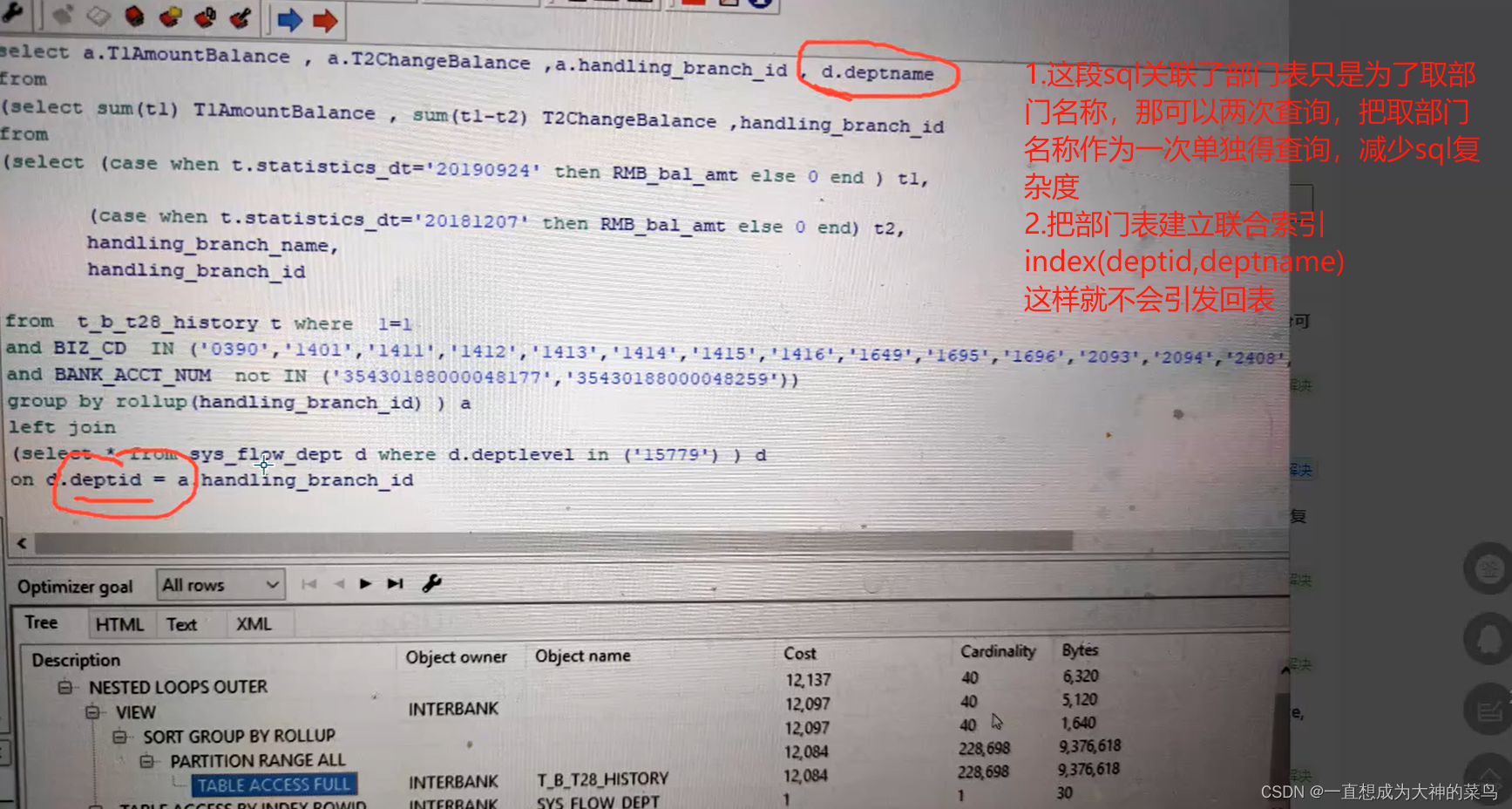
25.从索引上来讲,主键最好不要用uuid
如果是自增主键,那插入的时候在最后的索引节点进行操作就行
但如果用uuid,就很有可能发生新增的主键放在索引的中间位置,后边的就得重新挪位置
26.执行计划
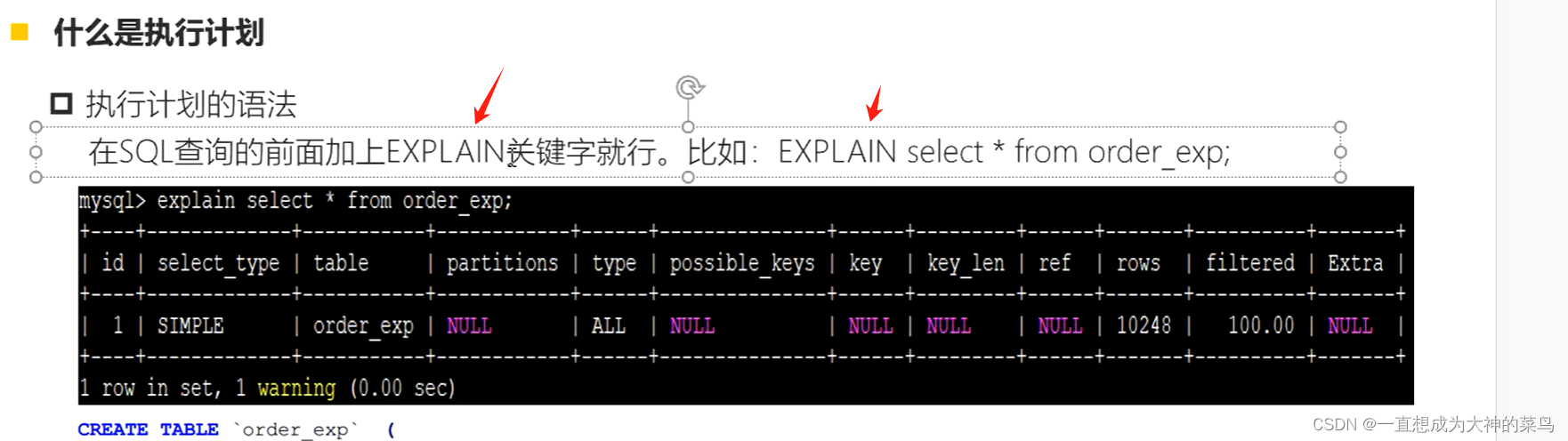
 查询多个表的时候可能出现多条执行计划
查询多个表的时候可能出现多条执行计划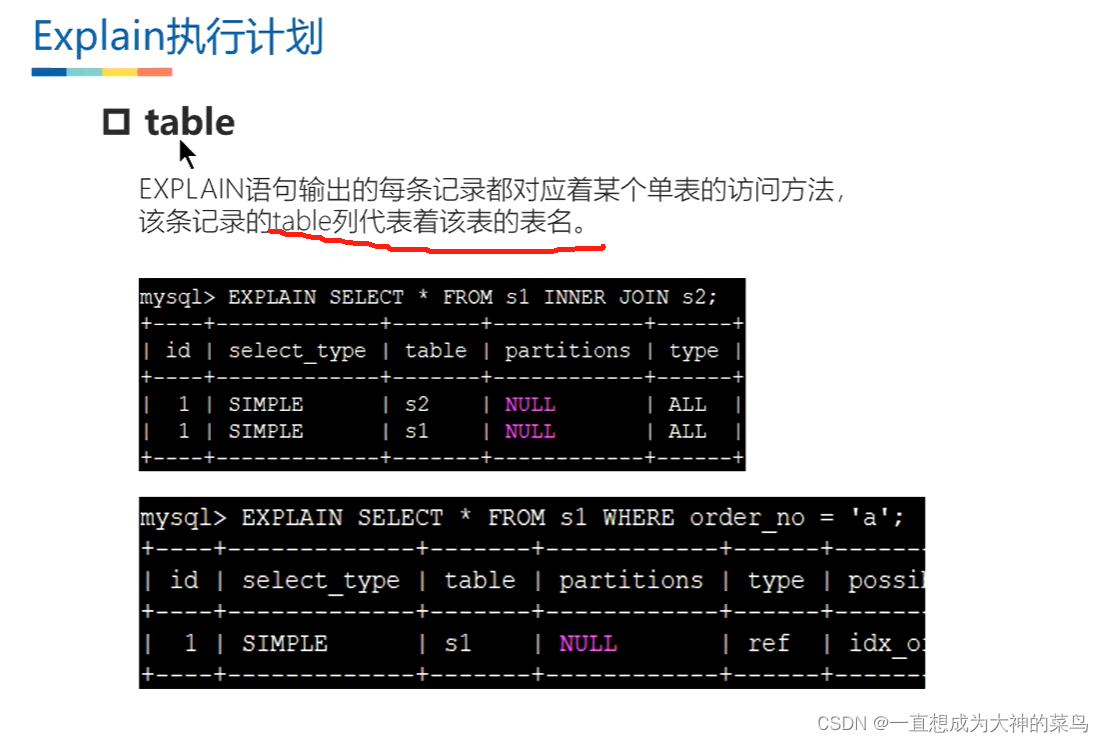
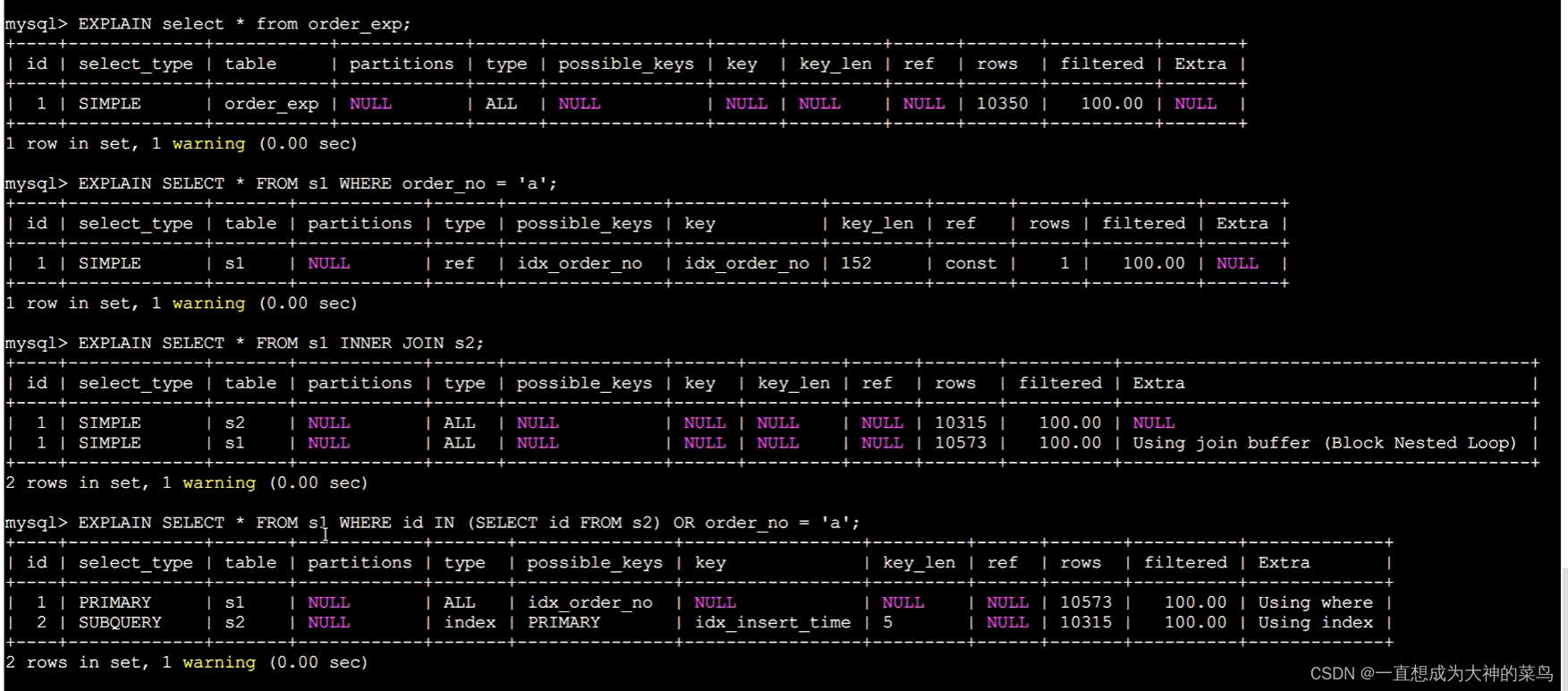
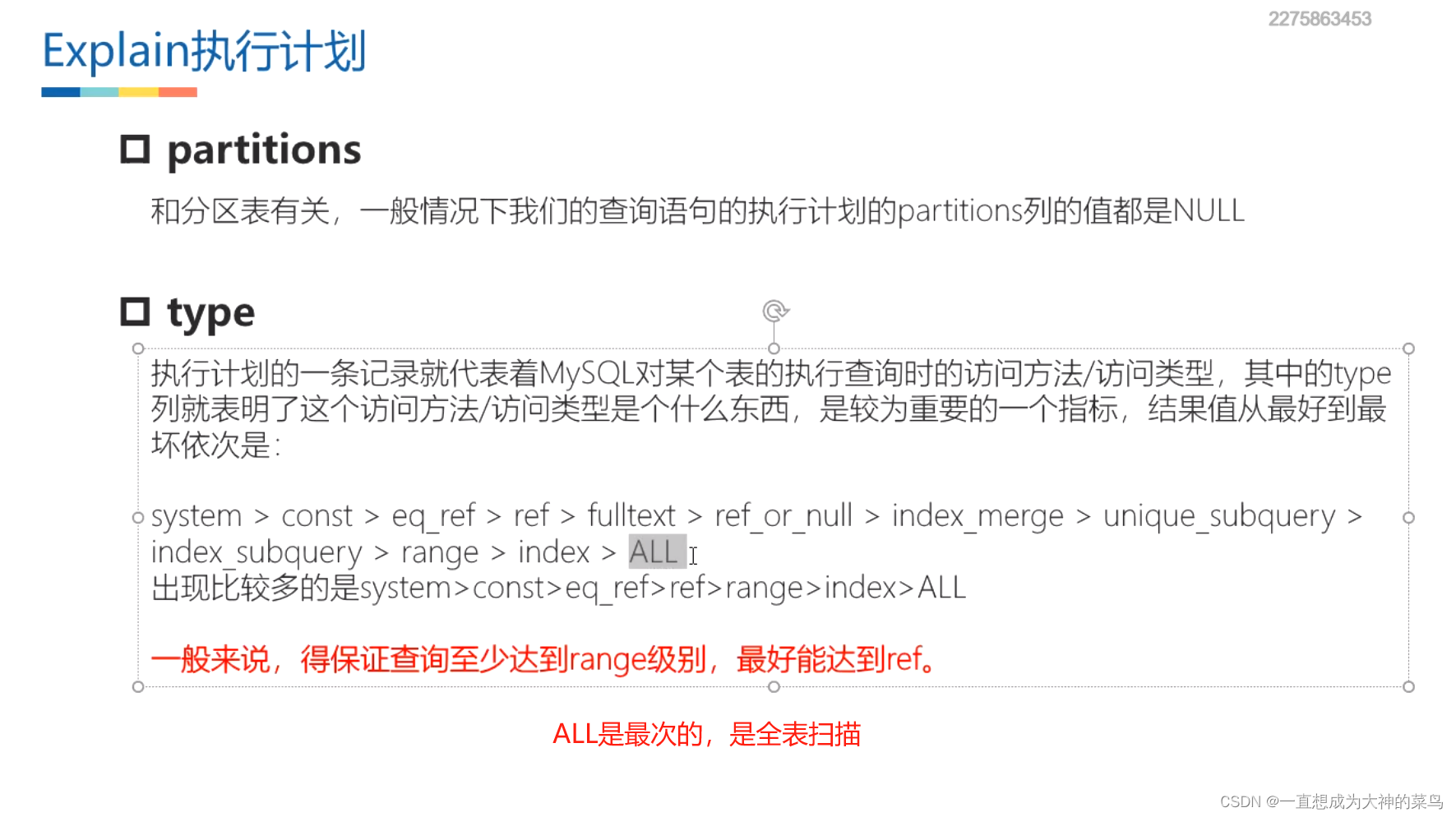
 type为const这种情况基本是最好的
type为const这种情况基本是最好的
所谓全表扫描,就是遍历整棵主键索引树
因为主键索引存储所有数据
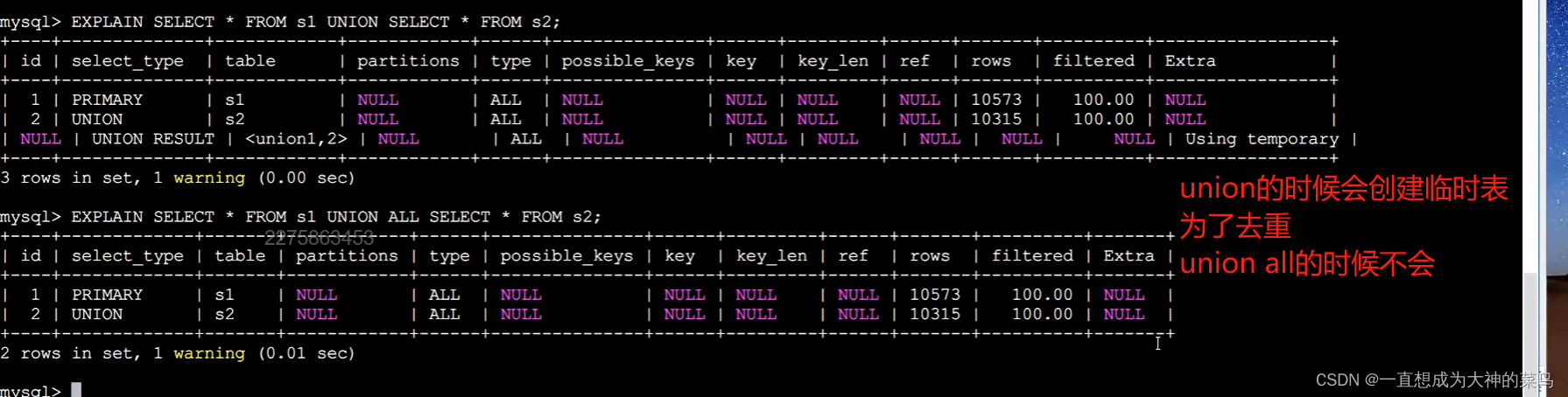
使用inner join时,mysql的优化器会根据效率,选择一个主表,比如A,B内连接,A只有十条数据,B有一千条,那就把A作为主表,去关联B,取交集,缩小范围
但使用外连接时,写sql时就注定了哪个表为主表,所以在写sql时候要注意这个优化,把数据少,能筛选掉大多数数据的表作为主表,缩小查询范围

范围查询:in between > < 都是范围扫描

27.索引覆盖的另一种情况
expire是联合索引最后一列,正常逻辑来讲应该是不走索引的
但是这个sql的结果集和条件,刚好都在联合索引那棵树上,然后mysql就直接扫描那棵B+树,这样成本比全表扫描低,也不用回表了
问题引申:为啥他不在主键索引上找?
1.where条件中没用到主键索引
2.全表扫描说的就是把主键索引从头到脚扫一边
3.主键索引存储了这个表的所有字段,数据量太大

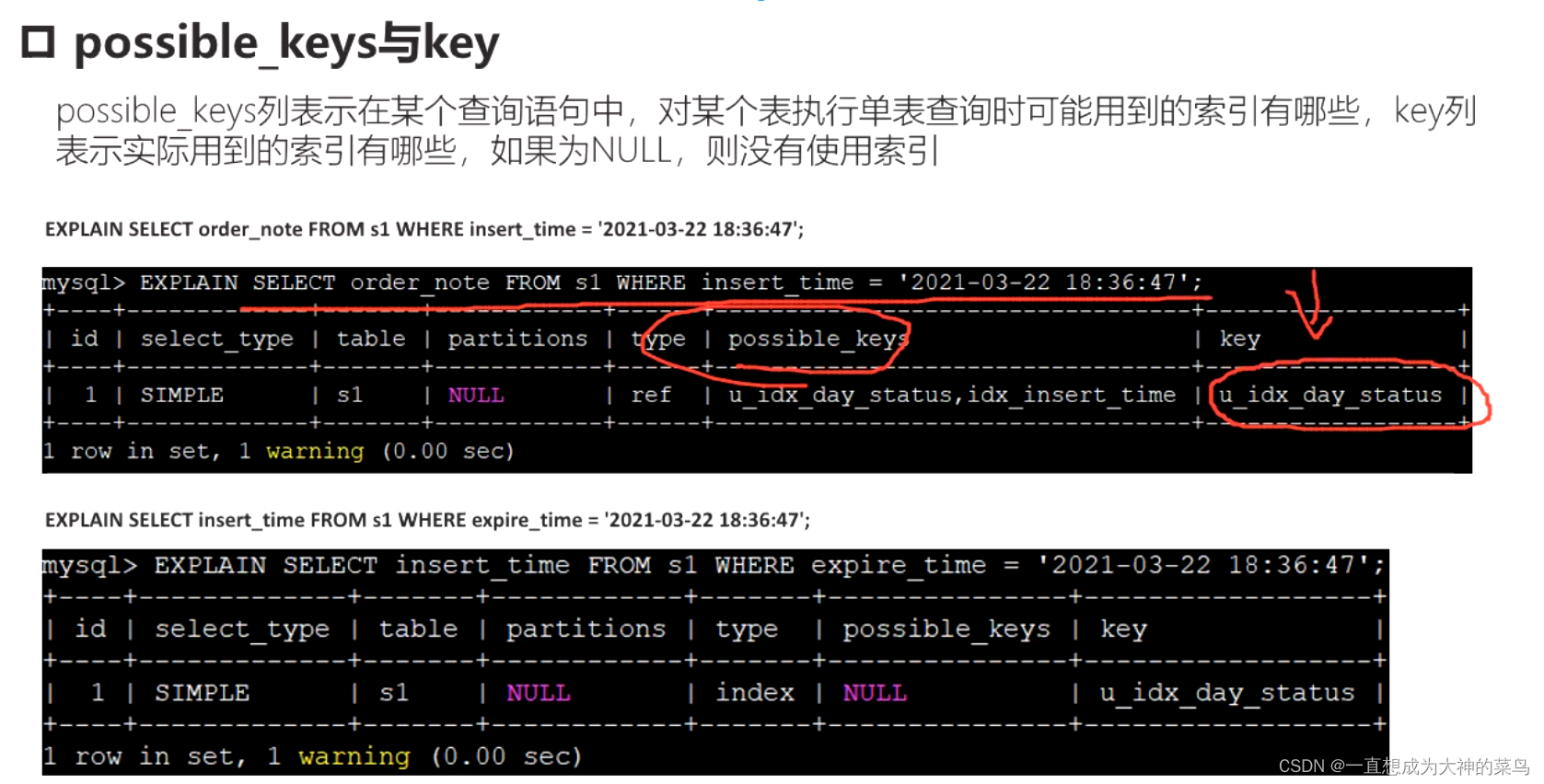
执行计划是这样显示的

possible_key是可能用到的索引,key是真正用到的索引,正常来讲,key是possible_key的子集
但是这个不是
因为mysql做出如上分析之后,会选择效率最高的一种
 28.执行计划的其他参数
28.执行计划的其他参数
key_len:索引长度

ref:关联查询是被连接的字段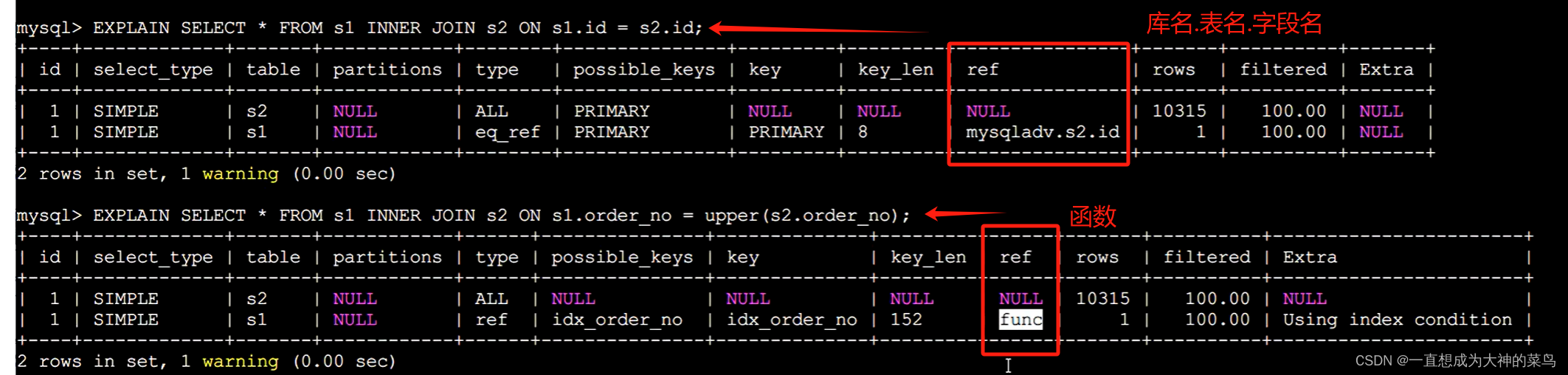
rows:扫描的行数
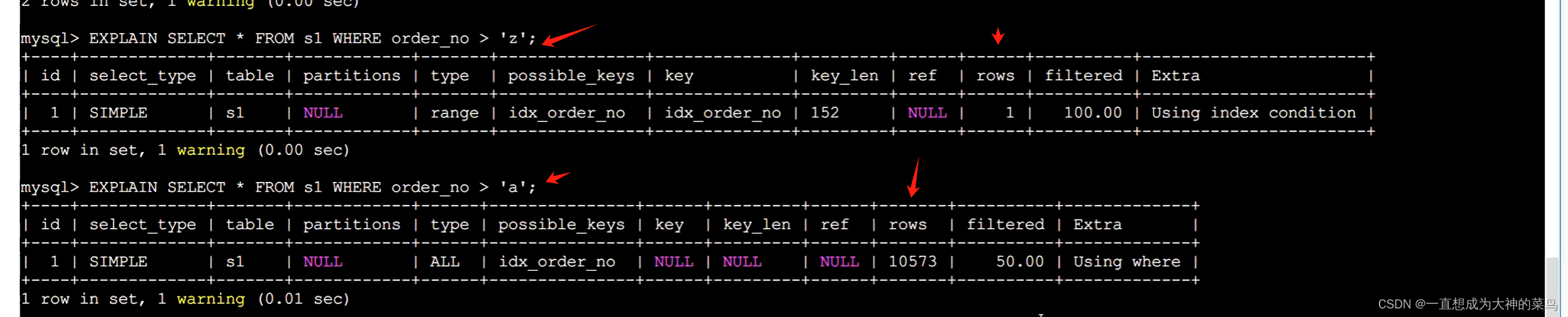 filtered:最终结果树跟扫描行数的比例,所占百分比
filtered:最终结果树跟扫描行数的比例,所占百分比

28.1 Extra
执行计划的最后一个字段
 using index:索引覆盖
using index:索引覆盖
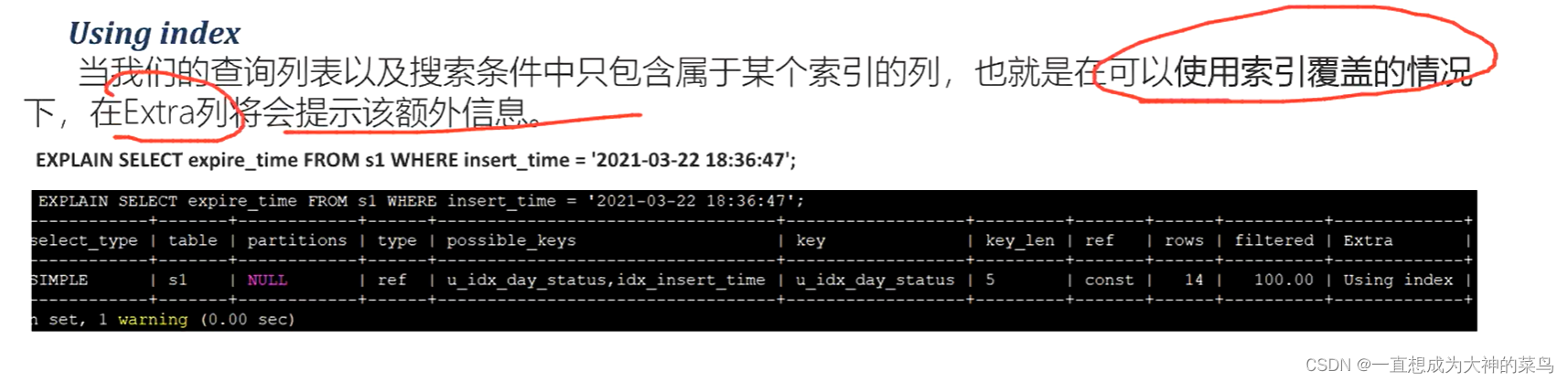 索引下推:如图举例
索引下推:如图举例
 useing where:只能说明用了where,别的啥也说明不了
useing where:只能说明用了where,别的啥也说明不了

not exist:查询条件与建表定义相反
比如有个字段我建表的时候就定义为not null
然后查询的时候我非得查询这个字段is null

using filesort:排序字段不是索引字段
fielsort时候 也需要优化
冷知识:mysql会在group by的时候自动按照被group by的字段顺序进行order by字段排序
要是不想排序,就得加上order by null
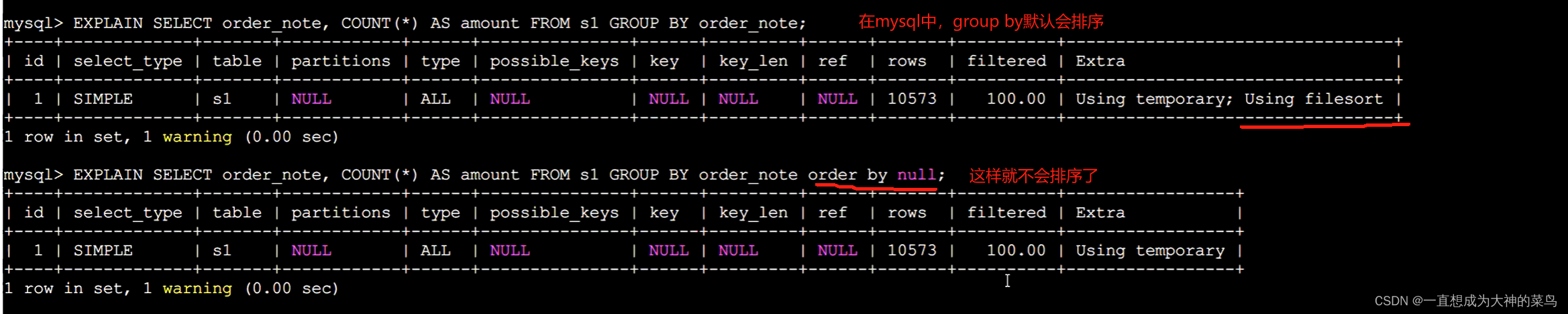
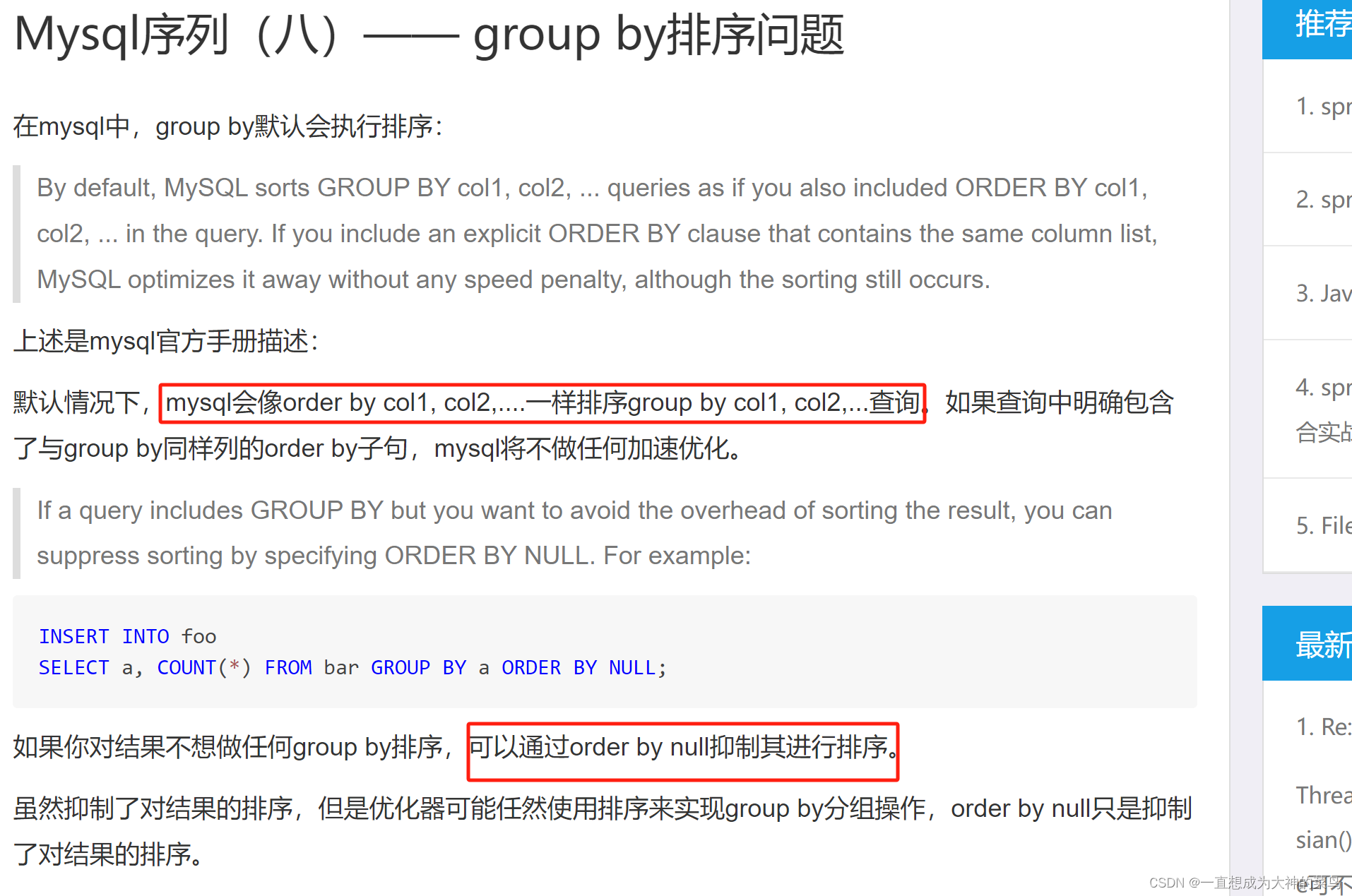
using temp:创建了临时表
出现这个的时候,是比较不好的一个情况,考虑优化
当执行计划中出现临时表这种情况,代表执行比较慢,因为临时表需要建立和维护
















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









