






1.Ernie1.0的创新点
1.改进mask策略
ERNIE有三种级别的mask,分别是对字、词组、命名实体进行mask。在预训练中,第一阶段是对字进行mask,第二阶段是对词组进行mask,第二阶段是对命名实体进行mask,如人名,机构名,商品名等,模型在训练完成后,也就学习到了这些实体的信息。

2.使用了大量中文语料
主要有Chinese Wikepedia,Baidu Baike,Baidu news,Baidu Tieba,并进行了繁简转化以及全部uncased。
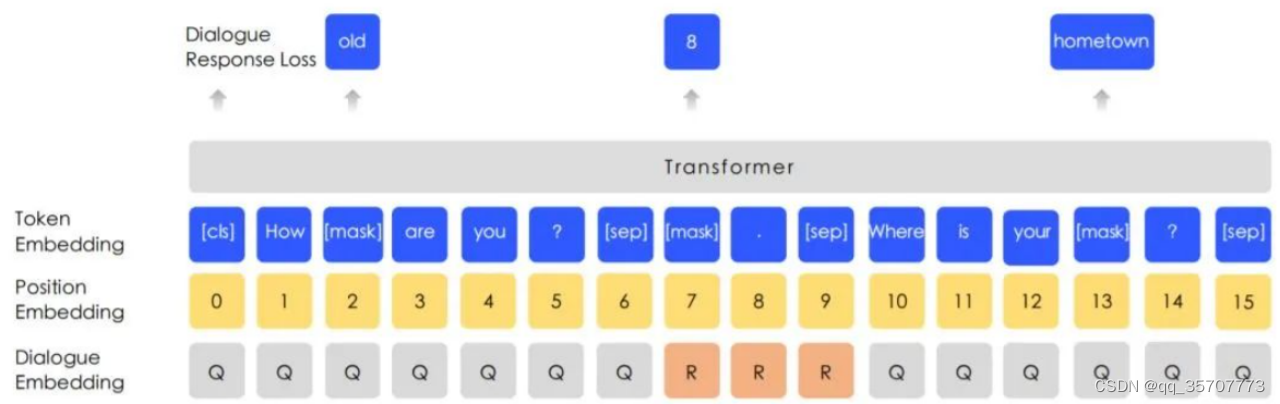
3.增加了对话任务
ERNIE增加了多轮对话形式的输入,即三个句子的组合[CLS]S1[SEP]S2[SEP]S3[SEP] 。这种组合可以表示多轮对话,例如QRQ,QRR,QQR。Q:提问,R:回答。为了表示哪些是提问、回答,还添加了dialog embedding,这个和segment embedding很类似。此外还增加了任务来判断这个多轮对话是真的还是假的。在多轮对话数据外都采用的是普通的NSP+MLM预训练任务。
2.ERNIE 2.0(一个用于语言理解的持续预训练框架)
在ERNIE1.0的基础上,提出了多个任务做预训练。为了避免模型在学了新的任务之后,忘记旧的任务,提出了一个包含pre-training 和fine-tuning的持续学习框架。
持续学习框架
首先,语言模型的任务可以分为三大类:字层级的任务,句层级的任务,语义层级的任务。
对于多个任务,框架将自动地为每个任务在模型训练的不同阶段都安排N个训练轮次,这样保证了有效率地学习到多任务。并且同一个阶段一起训练的任务之间有递进的关系。
每次有新任务过来,使用之前学习到的模型参数作为初始化,然后将新的任务和旧的任务一起训练。
除了正常的三种嵌入还增加了任务嵌入用来区别训练的任务, 对于N个任务,task的id就是从0~N-1。















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









