







最近在看一篇论文,里面用到以上几个分类器算法,简单回顾一下。
DBSCAN


K-means++
K-Means聚类算法原理 - 刘建平Pinard - 博客园

k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。那K-means++就是在K-means算法的基础上,多了一步选取优秀的初始聚类中心点,即,使k个中心点相隔较远。具体实现:

Naive Bayes(朴素贝叶斯)
忆臻博士的这篇用具体栗子来说明,特别容易理解!


Adaboosting
概念看这篇:数据挖掘算法学习(八)Adaboost算法_Bonnie的专栏-CSDN博客_ada算法
栗子看这篇:AdaBoost算法 - 知乎
SVM(支持向量机)
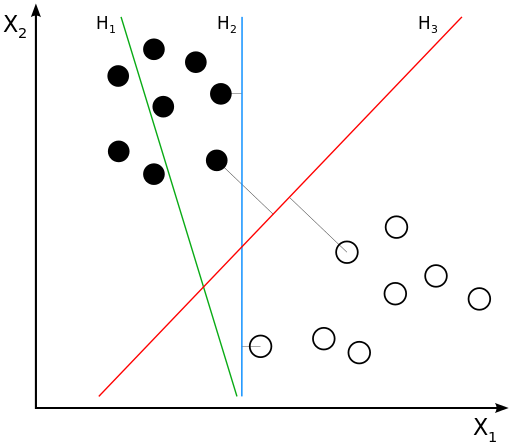
SVM就是一种二分类模型,他的基本模型是的定义在特征空间上的间隔最大的线性分类器,SVM的学习策略就是间隔最大化。
Random Forest(随机森林)
随机森林是由很多决策树构成的,不同决策树之间没有关联。
















 8499
8499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









