






目录
第一种主流数据集结构(不同类图像分别保存在不同类的文件夹下)
第二种主流数据集结构(所有的图像都在同一个文件夹中,图像的名字为其标签)
前言
本文概述:Pytorch没有自带的数据集切分方法,自己手写一个数据集切分方法又很麻烦,因此作者提供了一个数据集切分万能模块,适用于目前主流的图像数据集结构,并通过两个实例带大家轻松上手这个模块。
作者介绍:作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果您觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
一、图像数据集切割模块代码
import os
import torch
from torchvision import datasets,transforms
from torchvision.utils import save_image
from tqdm import tqdm
import math
def data_split(scr_data_path,traget_data_path,train_scale,val_scale,test_scale,num_workers,img_format):
data = datasets.ImageFolder(scr_data_path,transforms.ToTensor())
class_name=list(data.class_to_idx.keys())
image_size=len(data)
print("总计:"+str(image_size)+"it")
train_size=math.ceil(image_size*train_scale)
test_size=min(image_size-train_size,math.ceil(image_size*test_scale))
val_size =min(image_size-train_size-test_size,math.ceil(image_size*val_scale))
loader = torch.utils.data.DataLoader(data,batch_size=1,shuffle=True,num_workers=num_workers)
for C in class_name:
if not os.path.isdir(os.path.join(traget_data_path,'train',C)) and train_scale:
os.makedirs(os.path.join(traget_data_path,'train',C))
if not os.path.isdir(os.path.join(traget_data_path,'test',C)) and test_scale:
os.makedirs(os.path.join(traget_data_path,'test',C))
if not os.path.isdir(os.path.join(traget_data_path,'val',C)) and val_scale:
os.makedirs(os.path.join(traget_data_path,'val',C))
for index,image in tqdm(enumerate(loader)):
image,label=image
while train_size>0:
save_image(image,os.path.join(traget_data_path,'train',class_name[label],str(index+1)+'.'+img_format))
train_size-=1
break
while test_size>0 and not train_size:
save_image(image,os.path.join(traget_data_path,'test',class_name[label],str(index+1)+'.'+img_format))
test_size-=1
break
while val_size>0 and not test_size:
save_image(image,os.path.join(traget_data_path,'val',class_name[label],str(index+1)+'.'+img_format))
val_size-=1
break
print("切分完成\n保存路径为:"+traget_data_path)
if __name__ =='__main__':
data_split(
scr_data_path='D:/scr_data', # 原始数据集路径
traget_data_path='D:/traget_data', # 保存切分后数据集的保存路径
train_scale=0.8, # 训练集数量占比
test_scale=0.2, # 测试集数量占比
val_scale=0., # 验证集数量占比
num_workers=1, # 线程数 越大越快
img_format='jpg', # 想要保存的图像格式 'jpg' or 'png'
)PS:这个模板切分速度不算特别快,但是优势在于pytorch的shuffle比python的随机打乱效果要好。
二、使用方法
第一种主流数据集结构(不同类图像分别保存在不同类的文件夹下)
结构如图所示:
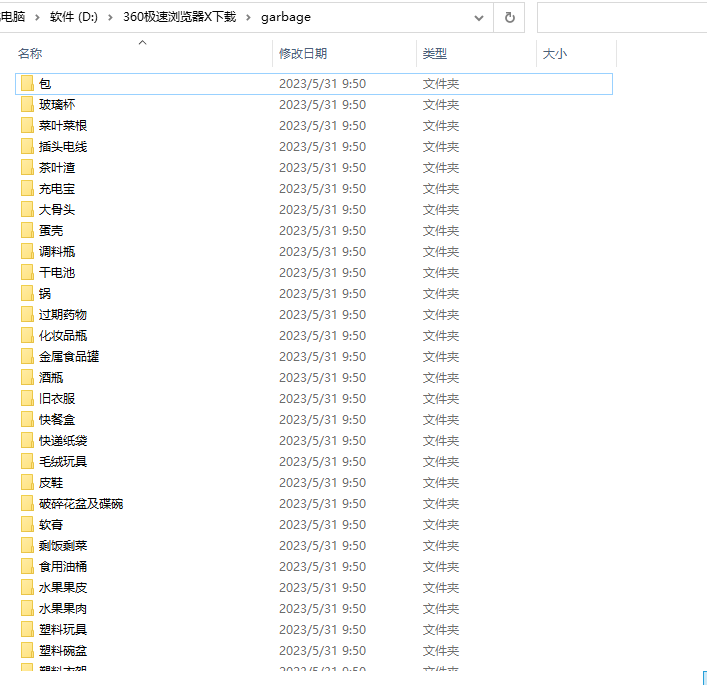

对于此类数据集,我们直接修改下模块的数据路径和你想要的切分比等配置即可
data_split(
scr_data_path='D:/360极速浏览器X下载/garbage', # 原始数据集路径
traget_data_path='D:/traget_data', # 保存切分后数据集的保存路径
train_scale=0.8, # 训练集数量占比
test_scale=0.2, # 测试集数量占比
val_scale=0., # 验证集数量占比
num_workers=12, # 线程数 越大越快
img_format='jpg', # 想要保存的图像格式 'jpg' or 'png'
)我们待切分的数据集的目录为D:/360极速浏览器X下载/garbage,我们想要将数据集只划分为8:2的训练数据集和测试集,然后我们的cpu核心有12个故线程这里填了12(不知道往大了填,报错会自动提示你的cpu最大线程数是多少),最后一项是想要将图片以什么样的格式保存。
切分好的数据集如下图所示:
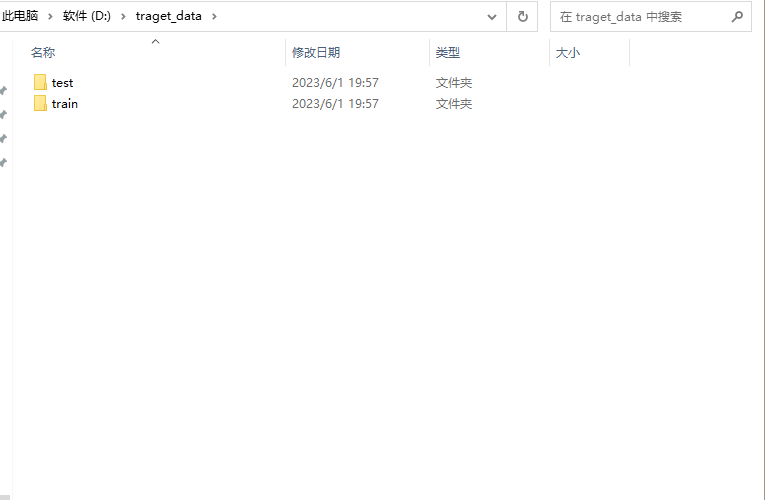

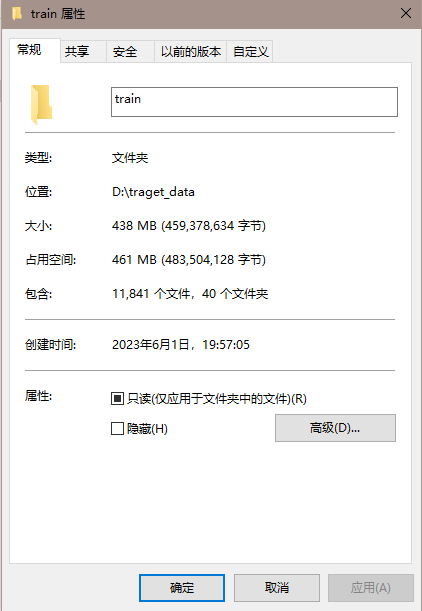
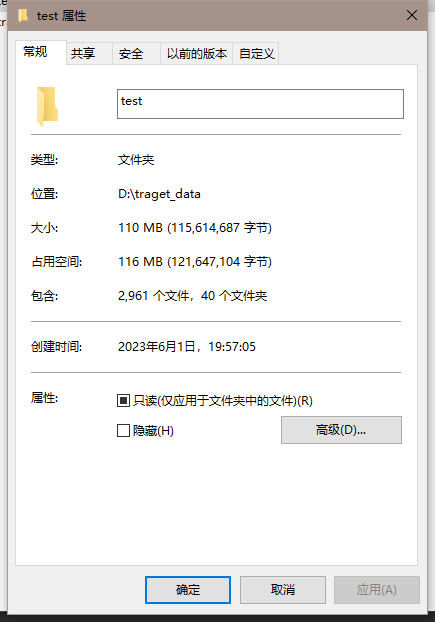
第二种主流数据集结构(所有的图像都在同一个文件夹中,图像的名字为其标签)
如图所示:
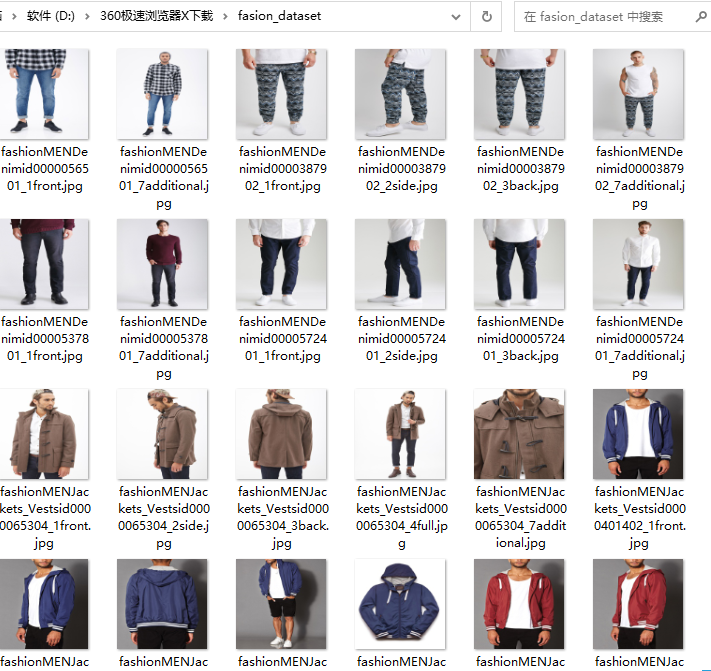
对于这种结构的数据集,我们依然可以使用上面的模板进行数据集切分,只不过额外多了一步创建新的文件夹。
第一步,创建一个新的文件夹,随意起个英文名就好,然后将原来装有数据集的文件,复制或者剪切到这个新的文件夹中
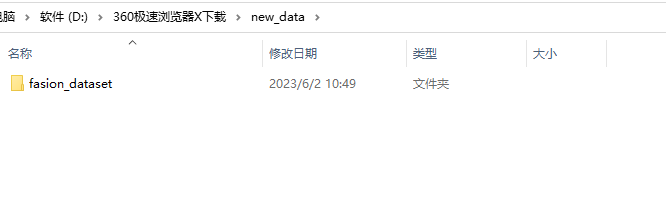
然后,后续步骤都和之前没有任何区别了
data_split(
scr_data_path='D:/360极速浏览器X下载/new_data', # 原始数据集路径
traget_data_path='D:/traget_data', # 保存切分后数据集的保存路径
train_scale=0.8, # 训练集数量占比
test_scale=0.2, # 测试集数量占比
val_scale=0., # 验证集数量占比
num_workers=1, # 线程数 越大越快
img_format='jpg', # 'jpg' or 'png'
)需要注意的是,这里的原始数据路径到新创建的文件夹D:/360极速浏览器X下载/new_data这一级就够了,而不是D:/360极速浏览器X下载/new_data/fasion_dataset
运行完成得到如下结果:
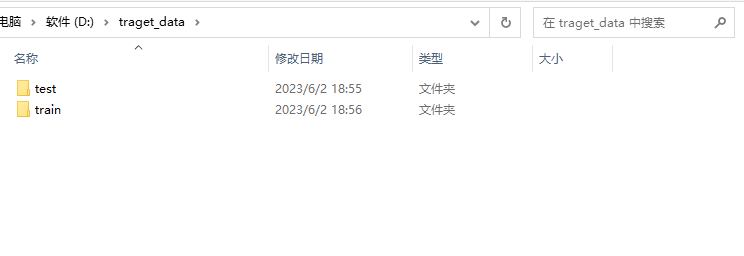

至此我们的数据集切分便完成了。
尾言
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。
















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











