







一、基本信息
论文题目:《Item-Based Top-N Recommendation Algorithms》
发表时间:2004 《ACM Transactions on Information Systems》
作者及单位:

论文地址:http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.5563
二、摘要
万维网的爆炸性增长和电子商务的出现导致了推荐系统的发展,这是一种个性化的信息过滤技术,用于识别一组特定用户感兴趣的项目。基于用户的协同过滤是目前构建推荐系统最成功的技术,在许多商业推荐系统中得到广泛应用。不幸的是,这些方法的计算复杂度随着客户数量的增加而线性增长,在典型的商业应用中,客户数量可能会达到数百万。为了解决这些可伸缩性问题,已经开发了基于模型的推荐技术。这些技术分析用户-项目矩阵以发现不同项目之间的关系,并使用这些关系计算建议列表。
在本文中,我们提出了一类基于模型的推荐算法,首先确定不同项目之间的相似性,然后使用它们来识别要推荐的项目集。这类算法的关键步骤是:(i)用于计算项目之间的相似性的方法;(i i)用于组合这些相似性的方法,以便计算一篮子项目与候选推荐项目之间的相似性。我们对八个真实数据集的实验评估表明,这些基于项的算法比传统的基于用户邻域的推荐系统快两个数量级,并提供具有可比性或更好质量的推荐。
三、主要内容与工作
1、predict whether a particular user will like a particular item (prediction problem)
identify a set of N items that will be of interest to a certain user (top-N recommendation problem)
2、本文的组织结构如下:第2节提供了将在整个论文中使用的定义和注释。第3节简要介绍了基于协同过滤的推荐算法的相关研究。第4节和第5节描述了我们基于一阶和更高阶的项目Top-N推荐系统中使用的各种阶段和算法。第6节对所提出算法的各种参数进行了实验评估,并将所提出的算法与基于用户的算法进行了比较。最后,第7节给出了一些总结性的评论。
3、一阶算法

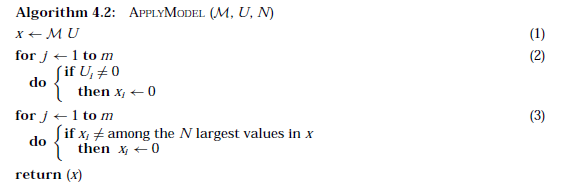
4、高阶模型


四、总结
在本文中,我们提出并实验评估了一类基于模型的Top-N推荐算法,该算法使用项到项或项到项集的相似性来计算推荐。结果表明,基于条件概率的项目相似度方案和基于高阶项目的模型都会导致推荐系统提供比传统的基于用户的CF技术更合理、更准确的推荐。此外,所提出的算法大大加快了速度;允许独立于用户项矩阵大小的实时建议。















 1833
1833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









