







 本文介绍了如何使用TensorFlow的Distribution Strategy API和Kubernetes进行分布式训练,以减少训练时间。主要讨论了MirroredStrategy,通过数据并行性和AllReduce实现多GPU训练,并介绍了CollectiveAllReduceStrategy用于多节点环境。文章强调了API的易用性、性能和适用性,以及在不同硬件、API和分布式架构中的应用。
本文介绍了如何使用TensorFlow的Distribution Strategy API和Kubernetes进行分布式训练,以减少训练时间。主要讨论了MirroredStrategy,通过数据并行性和AllReduce实现多GPU训练,并介绍了CollectiveAllReduceStrategy用于多节点环境。文章强调了API的易用性、性能和适用性,以及在不同硬件、API和分布式架构中的应用。
(TensorFlow @ O’Reilly AI Conference, San Francisco '18)
整理自google tensorflow2018年9月参加的TensorFlow @ O’Reilly AI Conference,介绍的分布式tensorflow《Distributed TensorFlow training using Keras and Kubernetes》,内容和ppt图片来自YouTube视频。
分享的主题
tensorflow提供的Distribution Strategy API。

Let’s begin with the obvious question. Why should one care about distributed training? Training complex neural networks with large amounts of data can often take a long time. In the graph here, you can see training the resident model on a single but powerful GPU can take up to four days. If you have some experience running complex machine learning models, this may sound rather familiar to you. Bringing down your training time from days to hours can have a significant effect on your productivity because you can try out new ideas faster.
In this talk, we’re going to talk about distributed training that is running training in parallel on multiple devices such as CPUs, GPUs, or TPUs to bring down your training time. With the techniques that you-- we’ll talk about in this talk, you can bring down your training time from weeks or days to hours with just a few lines of change of code and some powerful hardware. To achieve these goals, we’re pleased to introduce the new distribution strategy API. This is an easy way to distribute your TensorFlow training with very little modification to your code. With distribution strategy API, you no longer need to place ops or parameters on specific devices, and you don’t need to restructure a model in a way that the losses and gradients get aggregated correctly across the devices. Distribution strategy takes care of all of that for you. So let’s go with what are the key goals of distribution strategy.
目标

- The first one is ease of use. We want you to make minimal code changes in order to distribute your training.
- The second is to give great performance out of the box. Ideally, the user shouldn’t have to change any-- change or configure any settings to get the most performance out of their hardware.
- And third we want distribution strategy to work in a variety of different situations, so whether you want to scale your training on different hardware like GPUs or TPUs or you want to use different APIs like Keras or estimator or if you want to run distributed-- different distribution architectures like synchronous or asynchronous training, we have one distribution strategy to be useful for you in all these situations.
单机多GPU的训练

So if you’re just beginning with machine learning, you might start your training with a multi-core CPU on your desktop. TensorFlow takes care of scaling onto a multi-core CPU automatically. Next, you may add a GPU to your desktop to scale up your training. As long as you build your program with the right CUDA libraries, TensorFlow will automatically run your training on the GPU and give you a nice performance boost. But what if you have multiple GPUs on your machine, and you want to use all of them for your training? This is where distribution strategy comes in.

In the next section, we’re going to talk about how you can use distribution strategy to scale your training to multiple GPUs.

First, we’ll look at some code to train the ResNet model without any distribution. We’ll use a Keras API, which is the recommended TensorFlow high level API. We begin by creating some datasets for training and validation using the TF data API. For the model, we’ll simply reuse the ResNetthat’s prepackaged with Keras and TensorFlow. Then we create an optimizer that we’ll be using in our training. Once we have these pieces, we can compile the model providing the loss and optimizer and maybe a few other things like metrics, which I’ve omitted in the slide here. Once a model’s compiled, you can then begin your training by calling model dot fit, providing the training dataset that you created earlier, along with how many epochs you want to run the training for. Fit will train your model and update the models variables. Then you can call evaluate with the validation dataset to see how well your training did.
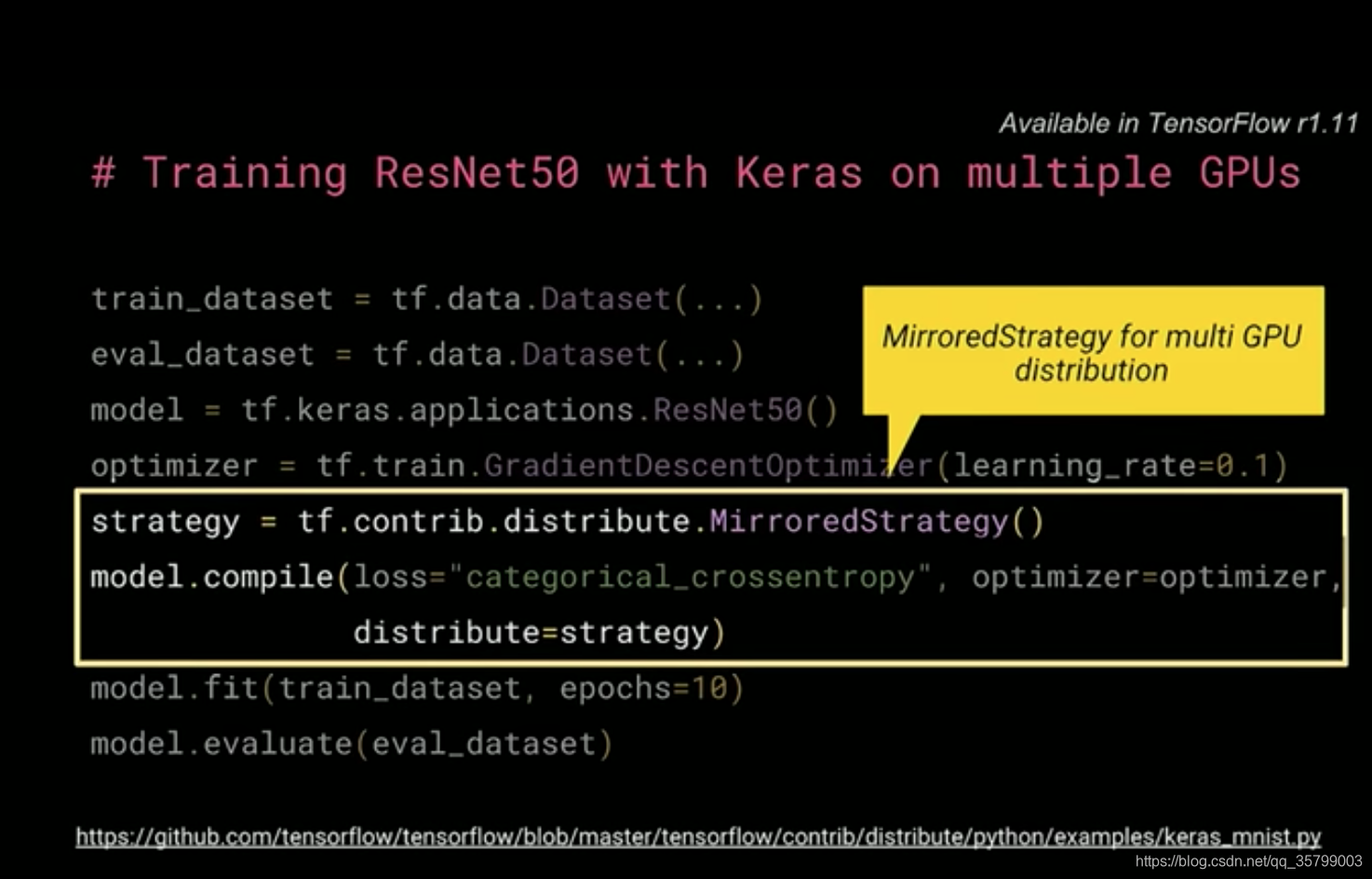
So given this code to run your training on a single machine or a single G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2880
2880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









