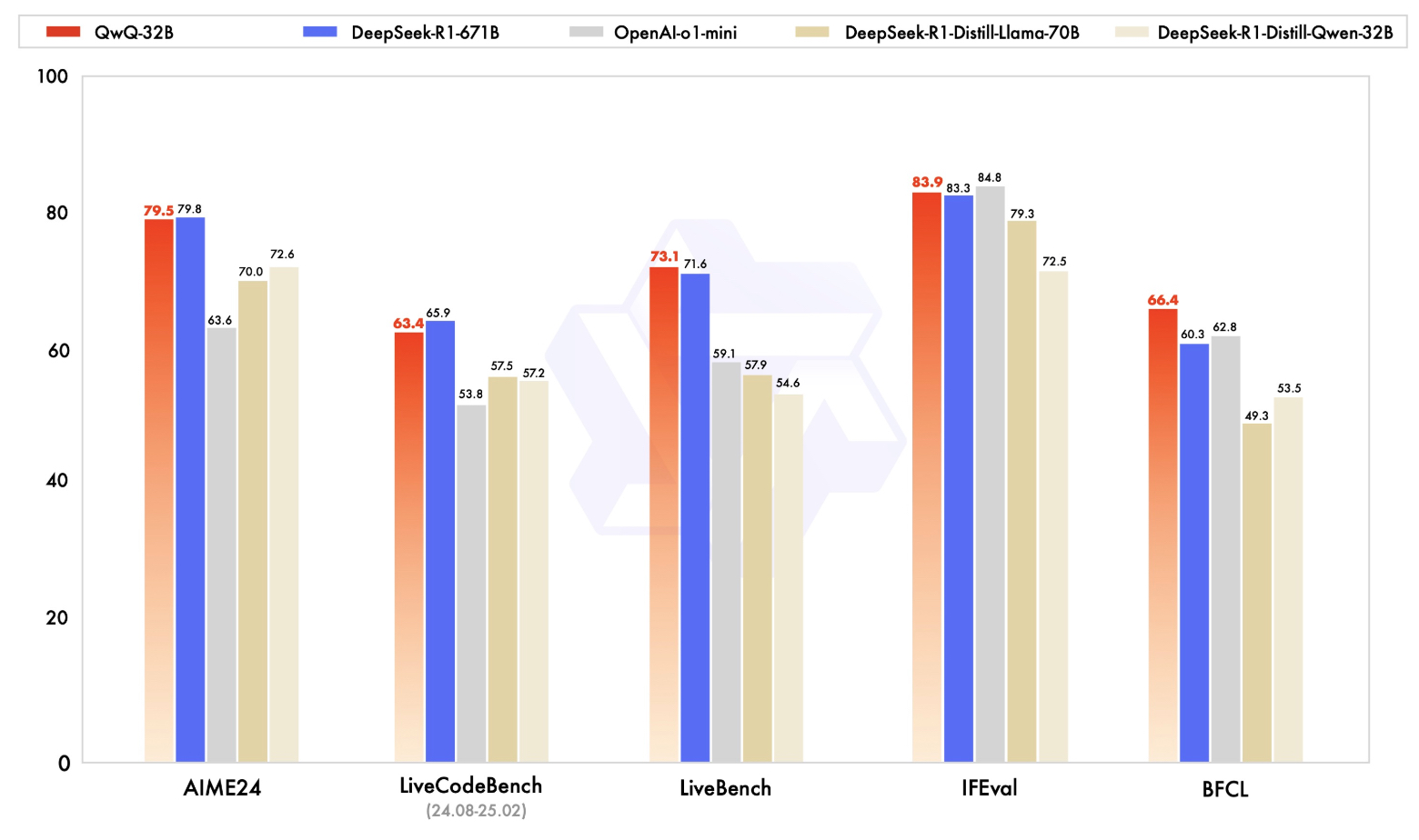
note 一、QwQ-32B 模型:https://huggingface.co/Qwen/QwQ-32B 使用RL训练,没使用传统的奖励模型,使用数学答案检查器、代码执行器等规则奖励。 指标和ds基本持平: Reference [1] https://huggingface.co/Qwen/QwQ-32B [2] https://qwenlm.github.io/blog/qwq-32b/




























 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








