









note
- 全模态LLM:输入可以是文本、图片、语音、视频,输出可以是流式的文本/语音
- 提出Thinker-Talker模型架构
- 提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入和音频的时间戳
- 实时语音和视频聊天:专为完全实时交互而设计的架构,支持分块输入和即时输出
- 和单模态模型作对比,更强:Qwen2.5-Omni 在音频功能方面优于类似大小的 Qwen2-Audio,并达到了与 Qwen2.5-VL-7B 相当的性能
一、Qwen2.5-Omni-7B模型
- 是全模态LLM:输入可以是文本、图片、语音、视频,输出可以是流式的文本/语音
- 提出Thinker-Talker模型架构
- 提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入和音频的时间戳
- 实时语音和视频聊天:专为完全实时交互而设计的架构,支持分块输入和即时输出
- 和单模态模型作对比,更强:Qwen2.5-Omni 在音频功能方面优于类似大小的 Qwen2-Audio,并达到了与 Qwen2.5-VL-7B 相当的性能
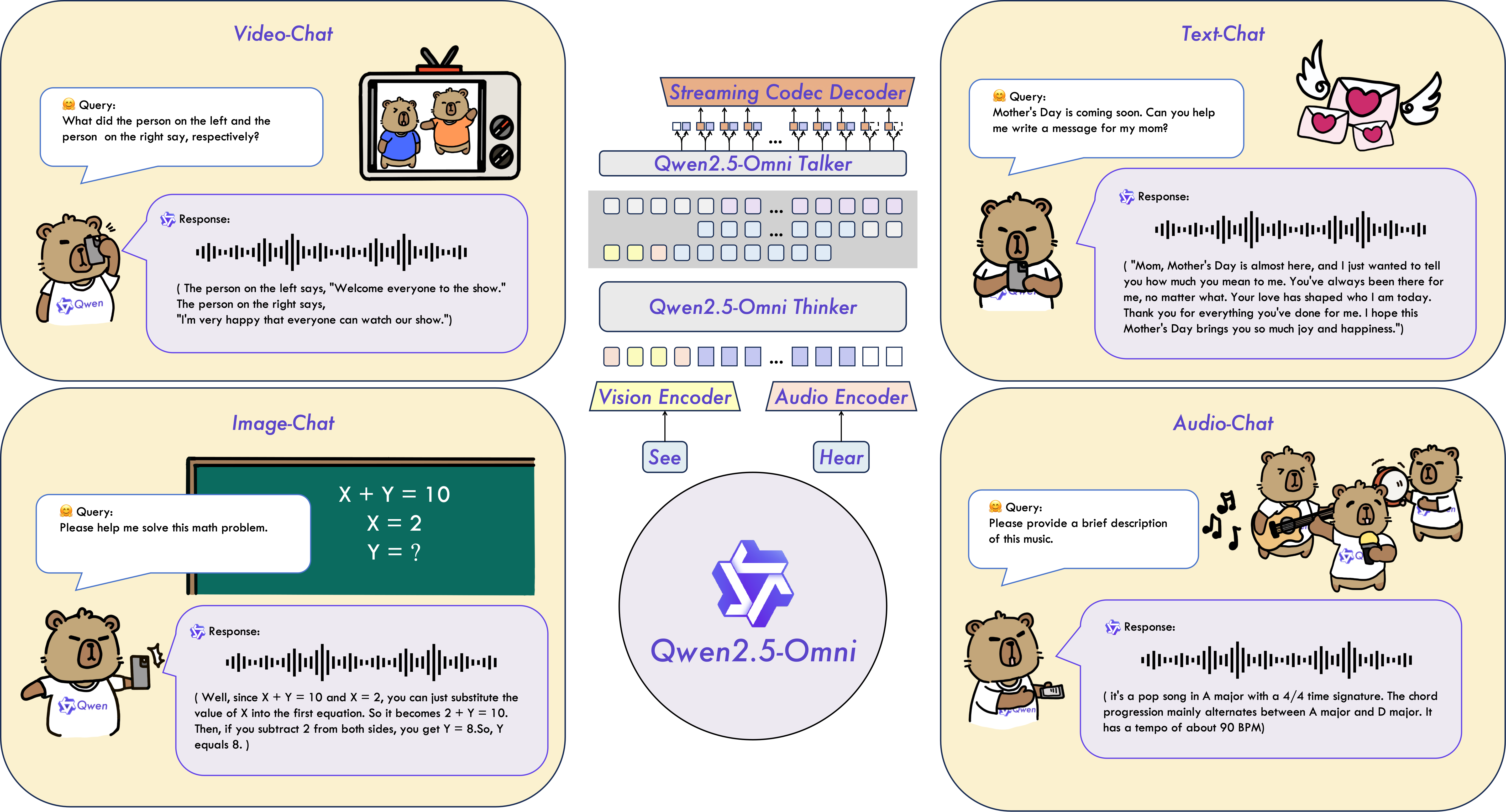
Qwen2.5-Omni-7B是一个端到端的多模态模型,可以接收文本、图像、音频和视频的输入,以文本或语音作为输出,参数模型结构见图2-3。
HF link:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
Paper:
https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
Qwen2.5-Omni提出了Thinker-Talker架构,同时提出了TMRoPE(时间对齐多模态 RoPE)的新型位置编码,用于同步视频输入的时戳与音频,支持全实时交互,支持分块输入和即时输出。
Qwen2.5-Omni,文本部分初始化采用Qwen2.5模型,Vision编码器初始化采用Qwen2.5-VL部分,Audio编码器初始化使用Whisper-large-v3。
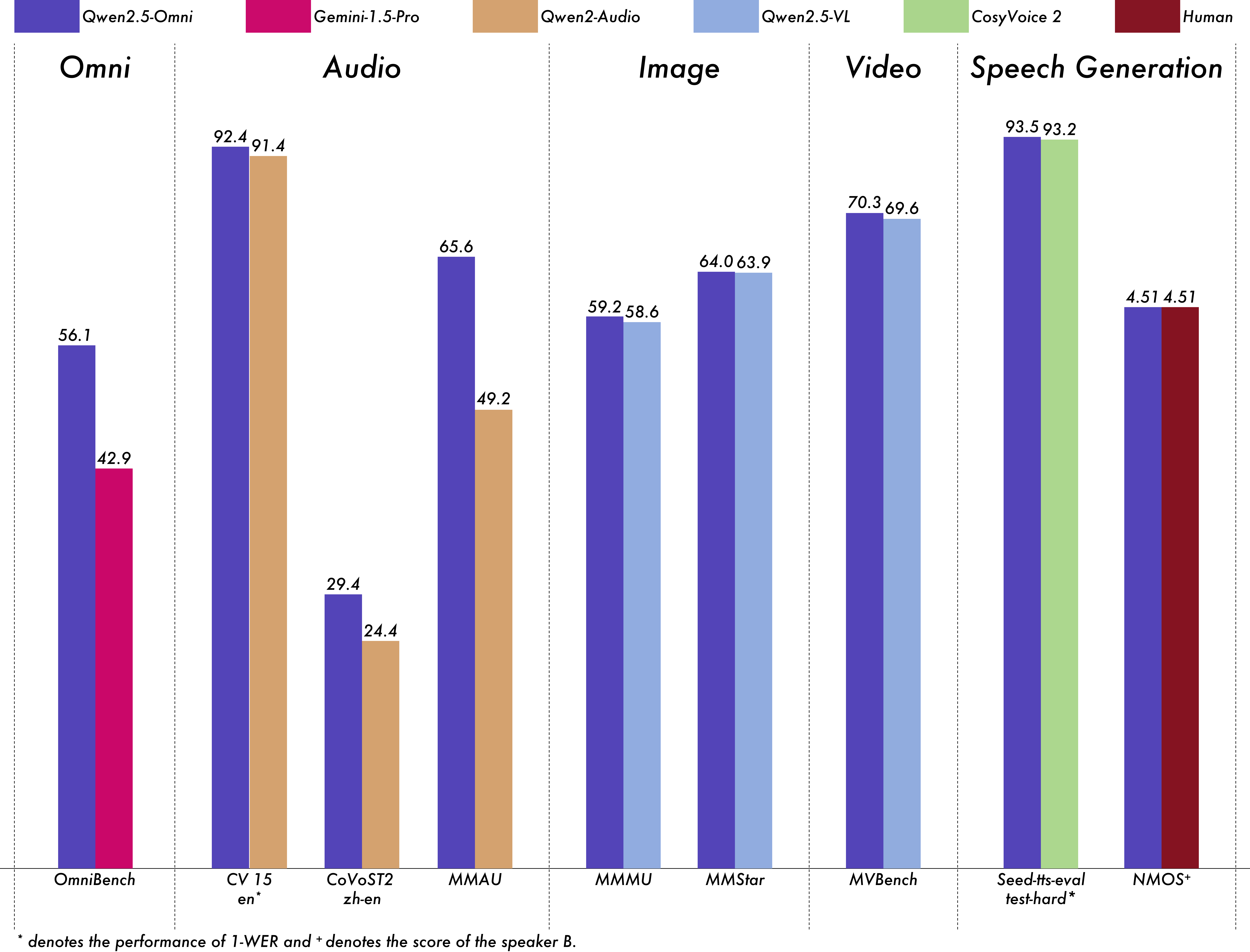
Qwen2.5-Omni效果很强,在音频能力上优于同等规模的Qwen2-Audio,在视觉能力上与Qwen2.5-VL-7B相当。
注意:如果需要音频输出,系统提示词必须为“You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.”
二、Qwen2.5-Omni-3B模型
HF link: https://huggingface.co/Qwen/Qwen2.5-Omni-3B
Paper: https://huggingface.co/papers/2503.20215
三、模型架构
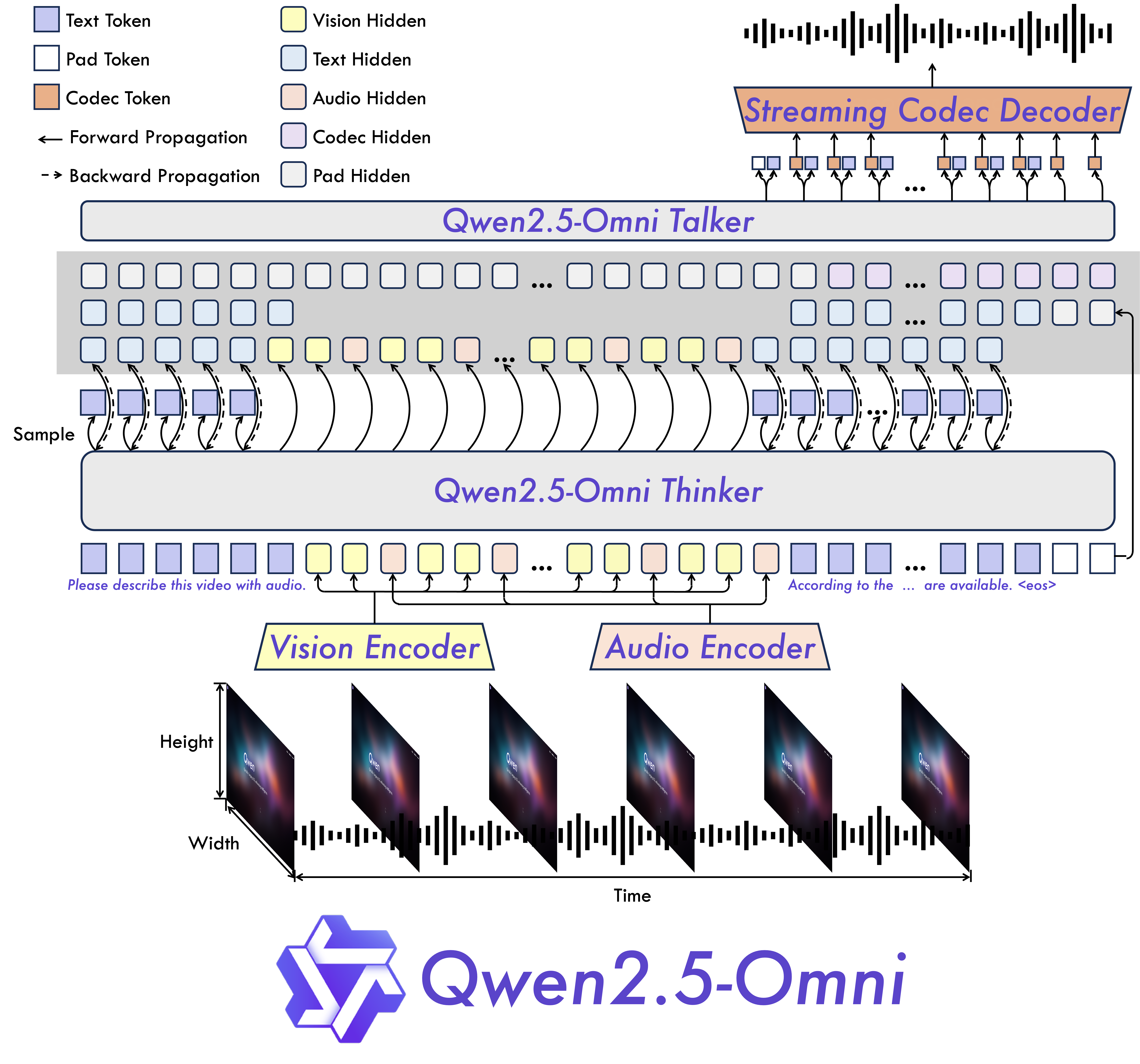
一、架构设计:
- Thinker-Talker架构: Thinker负责处理和理解来自文本、音频和视频模态的输入,生成高层次的表示和相应的文本。Talker则负责接收Thinker的高层次表示,并以流式方式生成语音令牌。
- TMRoPE: 提出了一种新的位置嵌入方法TMRoPE,显式地结合时间信息以同步音频和视频。通过对原始旋转嵌入进行分解,分别处理时间、高度和宽度信息。
- 流式处理: 采用块状流处理方法,支持多模态信息的实时处理。音频和视频编码器分别采用块状注意力和闪存注意力机制,以提高处理效率。
二、生成过程:
- 文本生成: 由Thinker直接生成文本,采用自回归采样方法,基于词汇表上的概率分布生成文本。
- 语音生成: Talker接收Thinker的高层次表示和文本令牌的嵌入,自回归地生成音频令牌。引入滑动窗口块注意力机制,限制当前令牌的上下文访问范围,增强流式输出的质量。
三、训练过程:
- 预训练: 分为三个阶段,第一阶段锁定LLM参数,训练视觉和音频编码器;第二阶段解冻所有参数,进行更广泛的多模态数据训练;第三阶段使用长序列数据进行训练,增强模型对复杂长序列数据的理解能力。
- 后训练: 包括指令跟随数据训练、DPO优化和多说话人指令微调,提升语音生成的稳定性和自然性。
四、模型效果


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











